深度学习框架PyTorch入门与实践:第八章 AI艺术家:神经网络风格迁移
本章我们将介绍一个酷炫的深度学习应用——风格迁移(Style Transfer)。近年来,由深度学习引领的人工智能技术浪潮越来越广泛地应用到社会各个领域。这其中,手机应用Prisma,尝试为用户的照片生成名画效果,一经推出就吸引了海量用户,登顶App Store下载排行榜。这神奇背后的核心技术就是基于深度学习的图像风格迁移。
风格迁移又称风格转换,直观点的类比就是给输入的图像加个滤镜,但是又不同于传统滤镜。风格迁移基于人工智能,每个风格都是由真正的艺术家作品训练、创作而成。只需要给定原始图片,并选择艺术家的风格图片,就能把原始图片转化成具有相应艺术家风格的图片。如下图所示,给定一张风格图片(左上角,手绘糖果图)和一张内容图片(右上角,斯坦福校园图),神经网络能够生成手绘风格的斯坦福校园图(下图)。
本章我们将一起学习风格迁移的原理,并利用PyTorch从头实现一个风格迁移的神经网络,来看看人工智能与艺术的交叉碰撞会产生什么样的有趣结果。
8.1 风格迁移原理介绍
风格迁移中有两类图片,一类是风格图片,通常是一些艺术家的作品,比较经典的有梵高的《星月夜》《向日葵》,毕加索的《A muse》,莫奈的《印象-日出》,日本浮世绘的《神奈川冲浪里》等,这些图片往往具有比较明显的艺术家风格,包括色彩、线条、轮廓等;另一类是内容图片,这些图片通常来自现实世界中,例如用户个人摄影。利用风格迁移能够将内容图片转换成具有艺术家风格的图片。
2015年,来自德国图宾根大学(University of Tubingen)Bethge实验室的三位研究院莱昂-盖提斯(Leon Gatys)、亚历山大-埃克(Alexander Ecker)和马蒂亚斯-贝特格(Matthias Bethge)研发了一种算法,模拟人类视觉的处理方式,通过训练多层卷积神经网络(CNN),让计算机识别并学会了梵高的“风格”,然后将任何一张普通的照片变成梵高的《星空》。2015年,他们的发现被整理成两篇论文《A Neural Algorithm of Artistic Style》和《Texture Synthesis Using Convolutional Neural Networks》,引起了学术界和工业界的极大兴趣。
Gatys等人提出的方法称为Neural Style,然而他们的做法在实现上过于复杂,每次进行风格迁移都需要几十分钟甚至几个小时的训练。斯坦福博士生Justin Johnson于2016年在ECCV上发表论文《Perceptual Losses for Real-Time Style Transfer and Super-Resolution》,提出了一种快速实现风格迁移的算法,这种方法通常被称为Fast Neural Style。当用Fast Neural Style训练好某一个风格的模型之后,通常只需要GPU运行几秒,就能生成对应的风格迁移结果。本章中介绍的主要是基于Justin Johnson的Fast Neural Style方法,即快速风格迁移。
Fast Neural Style和Neural Style主要有以下两点区别。
(1)Fast Neural Style针对每一个风格图片训练一个模型(在GPU上运行大概4个小时),而后可以反复利用,进行快速风格迁移(几秒到20秒)。Neural Style不需要专门训练模型,只需要从噪声中不断地调整图像的像素值,直到最后得到结果,速度较慢,需要十几分钟到几十分钟不等。
(2)普遍认为Neural Style生成的图片效果会比Fast Neural Style的效果好。
关于Neural Style的实现,可以参考PyTorch官方的Tutorial中的教程,实现也比较简单。本节主要介绍Fast Neural Style的实现。
要产生效果逼真的风格迁移的图片有两个要求。一是要生成的图片在内容、细节上尽可能地与输入的内容图片相似;二是要生成的图片在风格上尽可能地与风格图片相似。相应地,我们定义两个损失content loss和style loss,分别用来衡量上述两个指标。
图像的内容和风格含义广泛,并且没有严格统一的数学定义,具有很大程度上的主观性,因此很难表示。content loss比较常用的做法是采用逐像素计算差值,又称pixel-wise loss,追求生成的图片和原始图片逐像素的差值尽可能小。这种做法有诸多不合理的地方,Justin在论文中提出了一种更好的计算content loss的方法:perceptual loss。不同于pixel-wise loss计算像素层面的差异,perceptual loss计算的是图像在更高语义层次上的差异,论文中使用预训练好的神经网络的高层输入作为图片的知觉特征,进而计算二者的差异值作为perceptual loss。
深度学习之所以被称为“深度”,就在于它采用了深层的网络结构,网络的不同层学到的是图像不同层面的特征信息。深度学习网络的输入是像素信息,也可以认为是点,研究表明,几乎所有神经网络的第一层学习到的都是关于线条和颜色的信息,直观理解就是像素组成色彩,点组成线,这与人眼的感知特征十分相像。再往上,神经网络开始关注一些复杂的特征,例如拐角或者某些特殊的形状,这些特征可以看成是低层次的特征组合。随着深度的加深,神经网络关注的信息逐渐抽象,例如有些卷积核关注的是这张图中有个鼻子,或者是图中有张人脸,以及对象之间的空间关系,例如鼻子在人脸的中间等。
在进行风格迁移时,我们并不要求生成图片的像素和原始图片中的每一个像素都一样,我们追求的是生成图片和原始图片具有相同的特征:例如原图中有只猫,我们希望风格迁移之后的图片依旧有猫。图片中“有猫”这个概念不就是我们分类问题最后一层的输出吗?但最后一层的特征对我们来说抽象程度太高,因为我们不仅希望图片中有只猫,还希望保存这只猫的部分细节信息,例如它的形状、动作等信息,这些信息相对来说没有那么高的层次。因此我们使用中间某些层的特征作为目标,希望原图像和风格迁移的结果在这些层输出的结果尽可能相似,即将图片在深度模型的中间某些层的输出作为图像的知觉特征。
我们一般使用Gram矩阵来表示图像的风格特征。对于每一张图片,卷积层的输出形状为 C × H × W C \times H \times W C×H×W, C C C是卷积核的通道数,一般称为有 C C C个卷积核,每个卷积核学习图像的不同特征。每一个卷积核输出的 H × W H \times W H×W代表这张图像的一个feature map,可以认为是一张特殊的图像——原始彩色图像可以看作RGB三个feature map拼接组合成的特殊feature maps。通过计算每个feature map之间的相似性,我们可以得到图像的风格特征。对于一个 C × H × W C \times H \times W C×H×W的feature maps F F F,Gram Matrix的形状为 C × C C \times C C×C,其第 i i i、 j j j个元素 G i , j G_{i,j} Gi,j的计算方式定义如下:
G i , j = ∑ k F i k F j k G_{i,j}=\sum_k F_{ik}F_{jk} Gi,j=k∑FikFjk
其中 F i k F_{ik} Fik代表第 i i i个feature map的第 k k k个像素点。关于Gram Matrix,以下三点值得注意:
- Gram Matrix的计算采用了累加的形式,抛弃了空间信息。一张图片的像素随机打乱之后计算得到的Gram Matrix和原始Gram Matrix一样。所以可以认为Gram Matrix抛弃了元素之间的空间信息。
- Gram Matrix的结果与feature maps F F F的尺度无关,只与通道数有关。无论 H H H、 W W W的大小如何,最后Gram Matrix的形状都是 C × C C \times C C×C。
- 对于一个 C × H × W C \times H \times W C×H×W的feature maps,可以通过调整形状和矩阵乘法快速计算它的Gram Matrix,即先将 F F F调整为 C × ( H W ) C \times (HW) C×(HW)的二维矩阵,然后再计算 F ⋅ F T F \cdot F^T F⋅FT,结果计算Gram Matrix。
下图展现了Gram Matrix的特点:注重风格纹理等特征,忽略空间信息。图中第一行是输入的原图片,经过神经网络计算出不同层的Gram Matrix,然后尝试从这些层的Gram Matrix恢复出原图,换一种角度说,我们可以认为每一列的图像的Gram Matrix值都很接近。我们可以明显地看出,无论恢复的图像清晰度如何,图像的空间信息在计算Gram Matrix时都被舍弃,但是纹理、色彩等风格信息被保存下来。

实践证明利用Gram Matrix表征图像的风格特征在风格迁移、纹理合成等任务中的表现十分出众。
总结如下。
- 神经网络的高层输出可以作为图像的知觉特征描述。
- 神经网络的高层输出的Gram Matrix可以作为图像的风格特征描述。
- 风格迁移的目标是使生成图片和原图片的知觉特征尽可能相似,并且和风格图片的风格特征尽可能地相似。
在最初的Neural Style论文中,随机初始化目标图片为噪声,然后利用梯度下降法调整图片,使目标图片和风格图片的风格特征(即Gram Matrix)尽可能地相似,和原图片的知觉特征也尽可能地相似。这种做法生成的图片效果很好,但其十分耗时!每次都需要从一个噪声开始调整图片,直到得到最终的目标图片,在GPU上完成一次风格迁移需要十几分钟甚至数小时。
2016年Justin Johnson提出了一种快速风格迁移算法,这种算法被称为Fast Neural Style或Fast Style Transfer。与Neural Style相比,Fast Neural Style专门设计了一个网络用来进行风格迁移,输入原图片,网络自动生成目标图片。这个网络需要针对每一种风格图片驯良一个相对应的风格网络,但是一旦训练完成,便只需要20秒甚至更短的时间就能完成一次风格迁移。
Fast Neural Style的网络结构如下所示。 x x x是输入图像,在风格迁移任务中 y c = x y_c=x yc=x, y s y_s ys是风格图片,Image Transform Net f w fw fw是我们设计的风格迁移网络,针对输入的图像 x x x,能够返回一张新的图像 y ^ \hat y y^。 y ^ \hat y y^在图像内容上与 y c y_c yc相似,但在风格上与 y s y_s ys相似。损失网络(Loss Network)不用训练,只是用来计算知觉特征和风格特征。在论文中损失网络采用在ImageNet上预训练好的VGG-16。
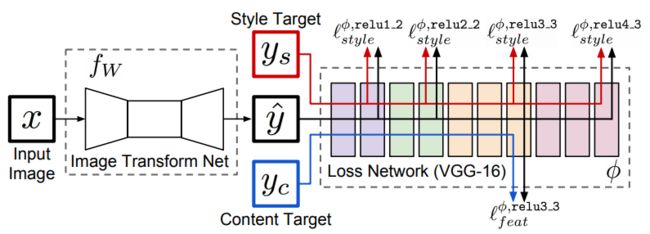
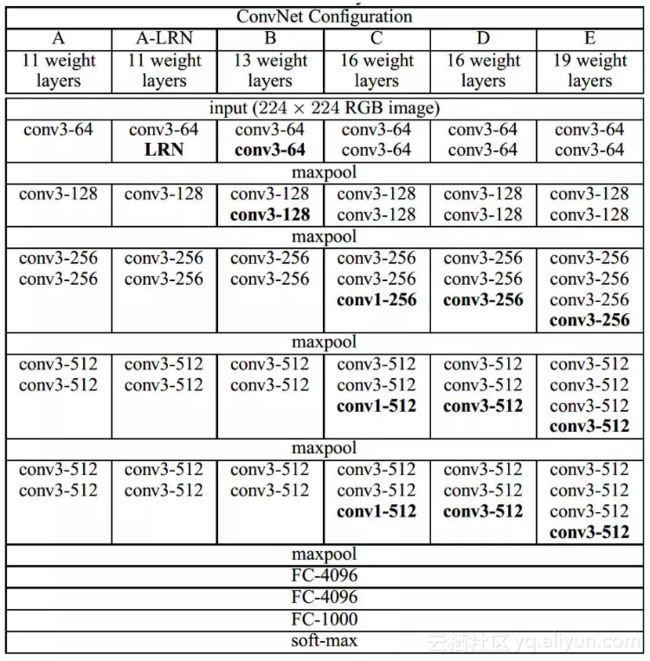
VGG-16的网络结构如下所示(第D列)。网络从左到右有5个卷积块,两个卷积块之间通过MaxPooling层区分。每个卷积块有2~3个卷积层,每一个卷积层后面都跟着一个ReLU激活层。上面的relu2_2表示第2个卷积块的第2个卷积层的激活层(ReLU)输出。

Fast Neural Style的训练步骤如下。
(1)输入一张图片 x x x到 f w fw fw中得到结果 y ^ \hat y y^。
(2)将 y ^ \hat y y^和 y c y_c yc(其实就是 x x x)输入到loss network(VGG-16)中,计算它在relu3_3的输出,并计算它们之间的均方误差作为content loss。
(3)将 y ^ \hat y y^和 y s y_s ys(风格图片)输入到loss network中,计算它在relu1_2、relu2_2、relu3_3和relu4_3的输出,再计算它们的Gram Matrix的均方误差作为style loss。
(4)两个损失相加,并反向传播。更新 f w fw fw参数,固定loss network不动。
(5)跳回第一步,继续训练 f w fw fw。
在讲解如何用PyTorch实现风格迁移之前,我们先来了解全卷积网络的结构。我们知道风格迁移网络的输入是图片,输出也是图片,对这种网络我们一般实现为一个全部都是卷积层而没有全连接层的网络结构。对于卷积层,当输入feature maps(或者图片)的尺寸为 C i n × H i n × W i n C_{in} \times H_{in} \times W_{in} Cin×Hin×Win,卷积核有 C o u t C_{out} Cout个,卷积核尺寸为 K K K,padding大小为 P P P,步长为 S S S时,输出feature maps的形状为KaTeX parse error: Undefined control sequence: \tiimes at position 9: C_{out} \̲t̲i̲i̲m̲e̲s̲ ̲H_{out} \times …,其中
H o u t = f l o o r ( H i n + 2 ∗ P − K ) / S + 1 H_{out} = floor(H_{in} + 2 * P - K) / S + 1 Hout=floor(Hin+2∗P−K)/S+1
W o u t = f l o o r ( W i n + 2 ∗ P − K ) / S + 1 W_{out} = floor(W_{in} + 2 * P - K) / S + 1 Wout=floor(Win+2∗P−K)/S+1
举例来说,如果我们输入的图片尺寸是3 x 256 x 256,第一层卷积的卷积核大小为3,padding为1,步长为2,通道数为128,那么输出的feature maps形状,按照上述公式计算的结果就是:
H o u t = f l o o r ( 256 + 2 ∗ 1 − 3 ) / 2 + 1 = 128 H_{out} = floor(256 + 2 * 1 - 3) / 2 + 1 = 128 Hout=floor(256+2∗1−3)/2+1=128
W o u t = f l o o r ( 256 + 2 ∗ 1 − 3 ) / 2 + 1 = 128 W_{out} = floor(256 + 2 * 1 - 3) / 2 + 1 = 128 Wout=floor(256+2∗1−3)/2+1=128
所以最后的输出是 C o u t × H o u t × W o u t = 128 × 128 × 128 C_{out} \times H_{out} \times W_{out} = 128 \times 128 \times 128 Cout×Hout×Wout=128×128×128,即尺寸缩小一倍,通道数增加。如果把步长由2改成1,则输出的形状就是128 x 256 x 256,即尺寸不变,只是通道数增加。
除卷积层之外,还有一种叫做转置卷积层(Transposed Convolution),也有人称之为反卷积(DeConvolution),它可以看成是卷积操作的逆运算。对于卷积操作,当步长大于1时,执行的是类似于上采样的操作。全卷积网络的一个重要优势在于对输入的尺寸没有要求,这样在进行风格迁移时就能够接受不同分辨率的图片。
论文中提到的风格迁移结构全部由卷积层、Batch Normalization和激活层组成,不包含全连接层。在这里我们不使用Batch Normalization,取而代之的是Instance Normalization。Instance Normalization和Batch Normalization的唯一区别就在于InstanceNorm只对每一个样本求均值和方差,而BatchNorm则会对一个batch中所有的样本求均值。例如对于一个 B × C × H × W B \times C \times H \times W B×C×H×W的tensor,在Batch Normalization中计算均值时,就会计算 B × H × W B \times H \times W B×H×W个数的均值,共有 C C C个均值;而Instance Normalization会计算 H × W H \times W H×W个数的均值,即共有 B × C B \times C B×C个均值。在Dmitry Ulyanov的论文《Instance Normalization:The Missing Ingredient for Fast Stylization》中提到过,用InstanceNorm代替BatchNorm能显著地提升风格迁移的效果。
8.2 用PyTorch实现风格迁移
本章所有代码和图片数据:百度网盘下载,提取码:nyf9。
我们先来看看本次实验的文件组织:
checkpoints/
data/coco/
main.py
PackedVGG.py
style.jpg
transformer_net.py
utils.py
上述各个文件的主要内容和作用如下。
- checkpoints/:用来保存模型。
- data/:用于保存数据,可以把数据直接保存于coco文件夹下。
- main.py:主函数,包括训练和测试。
- PackedVGG.py:预训练好的VGG-16,为了提取中间层的输出,所以做了一些修改简化。
- transformer_net.py:风格迁移网络。输入一张图片,输出一张图片。
- utils.py:工具集合,主要是可视化工具visdom的封装和计算Gram Matrix等。
首先来看看如何使用预训练的VGG,这部分代码保存在PackedVGG.py中。在torchvision的仓库中有预训练好的VGG-16网络,使用十分方便,但在风格迁移网络中,我们需要获得中间层的输出,因此需要修改网络的前向传播过程,将相应层的输出保存下来。同时有很层不再需要,可删除以节省内存占用。实现的代码如下。
# coding:utf8
import torch
import torch.nn as nn
from torchvision.models import vgg16
from collections import namedtuple
class Vgg16(torch.nn.Module):
def __init__(self):
super(Vgg16, self).__init__()
features = list(vgg16(pretrained=True).features)[:23]
# features的第3,8,15,22层分别是: relu1_2,relu2_2,relu3_3,relu4_3
self.features = nn.ModuleList(features).eval()
def forward(self, x):
results = []
for ii, model in enumerate(self.features):
x = model(x)
if ii in {3, 8, 15, 22}:
results.append(x)
vgg_outputs = namedtuple("VggOutputs", ['relu1_2', 'relu2_2', 'relu3_3', 'relu4_3'])
return vgg_outputs(*results)
在torchvision中,VGG的实现由两个nn.Sequential对象组成,第一个是features,包含卷积、激活和MaxPool等层,用来提取图片特征,另一个是classifier,包含全连接层等,用来分类。用以通过vgg.features直接获得对应的nn.Sequential对象。这样在前向传播时,当计算完指定层的输出后,将结果保存于一个list中,然后再使用namedtuple进行名称绑定,这样可以通过output.relu1_2访问第一个元素,更为方便和直观。当然也可以利用layer.register_forward_hook的方式获取相应层的输出,但是在本例中相对比较麻烦。
接下来要实现的是风格迁移网络,其代码在transformer_net.py中,实现时参考了PyTorch的官方示例,其网络结构如下图所示。

图中(b)是网络的总体结构,左边(d)是一个残差单元的结构图,右边(c)和(d)分别是下采样和上采样单元的结构图。网络结构总结起来有以下几个特点。
- 先下采样,然后上采样,这种做法使计算量变小,详细说明请参考论文。
- 使用残差结构使网络变深。
- 边缘补齐的方式不再是传统的补0,而是采用一种被称为Reflection Pad的补齐策略:上下左右反射边缘的像素进行补齐。
- 上采样不再是使用传统的ConvTranspose2d,而是先用Upsample,然后用Conv2d,这种做法能避免Checkboard Artifacts现象。
- Batch Normalization全部改成Instance Normalization。
- 网络中没有全连接层,线性 操作是卷积。因此对输入和输出图片的尺寸没有要求,这里我们输入和输出图片的尺寸都是3 * 256 * 256(其他尺寸的一样可以)。
在第6章中我们提到过,对于常见的网络结构,可以实现为nn.Module对象,作为一个特殊的层。在本例中,Conv、UpConv和Residual Block都可以如此实现。
例如Conv,可以实现为:
class ConvLayer(nn.Module):
"""
add ReflectionPad for Conv
默认的卷积的padding操作是补0,这里使用边界反射填充
"""
def __init__(self, in_channels, out_channels, kernel_size, stride):
super(ConvLayer, self).__init__()
reflection_padding = int(np.floor(kernel_size / 2))
self.reflection_pad = nn.ReflectionPad2d(reflection_padding)
self.conv2d = nn.Conv2d(in_channels, out_channels, kernel_size, stride)
def forward(self, x):
out = self.reflection_pad(x)
out = self.conv2d(out)
return out
UpConv和Residual Block的实现也是类似的,这里不再细说,具体内容请看本章配套代码。
主模型主要包含三个部分:下采样的卷积层、深度残差层和上采样的卷积层。实现时充分利用了nn.Sequential,避免在forward中重复写代码,其代码如下。
class TransformerNet(nn.Module):
def __init__(self):
super(TransformerNet, self).__init__()
# 下卷积层
self.initial_layers = nn.Sequential(
ConvLayer(3, 32, kernel_size=9, stride=1),
nn.InstanceNorm2d(32, affine=True),
nn.ReLU(True),
ConvLayer(32, 64, kernel_size=3, stride=2),
nn.InstanceNorm2d(64, affine=True),
nn.ReLU(True),
ConvLayer(64, 128, kernel_size=3, stride=2),
nn.InstanceNorm2d(128, affine=True),
nn.ReLU(True),
)
# Residual layers(残差层)
self.res_layers = nn.Sequential(
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128),
ResidualBlock(128)
)
# Upsampling Layers(上卷积层)
self.upsample_layers = nn.Sequential(
UpsampleConvLayer(128, 64, kernel_size=3, stride=1, upsample=2),
nn.InstanceNorm2d(64, affine=True),
nn.ReLU(True),
UpsampleConvLayer(64, 32, kernel_size=3, stride=1, upsample=2),
nn.InstanceNorm2d(32, affine=True),
nn.ReLU(True),
ConvLayer(32, 3, kernel_size=9, stride=1)
)
def forward(self, x):
x = self.initial_layers(x)
x = self.res_layers(x)
x = self.upsample_layers(x)
return x
搭建完网络之后,我们还要实现一些工具函数,这部分的代码保存于utils.py中。代码如下:
# coding:utf8
from itertools import chain
import visdom
import torch as t
import time
import torchvision as tv
import numpy as np
IMAGENET_MEAN = [0.485, 0.456, 0.406]
IMAGENET_STD = [0.229, 0.224, 0.225]
def gram_matrix(y):
"""
输入 b,c,h,w
输出 b,c,c
"""
(b, ch, h, w) = y.size()
features = y.view(b, ch, w * h)
features_t = features.transpose(1, 2)
gram = features.bmm(features_t) / (ch * h * w)
return gram
class Visualizer():
"""
封装了visdom的基本操作,但是你仍然可以通过`self.vis.function`
调用原生的visdom接口
"""
def __init__(self, env='default', **kwargs):
import visdom
self.vis = visdom.Visdom(env=env, use_incoming_socket=False, **kwargs)
# 画的第几个数,相当于横座标
# 保存(’loss',23) 即loss的第23个点
self.index = {}
self.log_text = ''
def reinit(self, env='default', **kwargs):
"""
修改visdom的配置
"""
self.vis = visdom.Visdom(env=env,use_incoming_socket=False, **kwargs)
return self
def plot_many(self, d):
"""
一次plot多个
@params d: dict (name,value) i.e. ('loss',0.11)
"""
for k, v in d.items():
self.plot(k, v)
def img_many(self, d):
for k, v in d.items():
self.img(k, v)
def plot(self, name, y):
"""
self.plot('loss',1.00)
"""
x = self.index.get(name, 0)
self.vis.line(Y=np.array([y]), X=np.array([x]),
win=name,
opts=dict(title=name),
update=None if x == 0 else 'append'
)
self.index[name] = x + 1
def img(self, name, img_):
"""
self.img('input_img',t.Tensor(64,64))
"""
if len(img_.size()) < 3:
img_ = img_.cpu().unsqueeze(0)
self.vis.image(img_.cpu(),
win=name,
opts=dict(title=name)
)
def img_grid_many(self, d):
for k, v in d.items():
self.img_grid(k, v)
def img_grid(self, name, input_3d):
"""
一个batch的图片转成一个网格图,i.e. input(36,64,64)
会变成 6*6 的网格图,每个格子大小64*64
"""
self.img(name, tv.utils.make_grid(
input_3d.cpu()[0].unsqueeze(1).clamp(max=1, min=0)))
def log(self, info, win='log_text'):
"""
self.log({'loss':1,'lr':0.0001})
"""
self.log_text += ('[{time}] {info}
'.format(
time=time.strftime('%m%d_%H%M%S'),
info=info))
self.vis.text(self.log_text, win=win)
def __getattr__(self, name):
return getattr(self.vis, name)
def get_style_data(path):
"""
加载风格图片,
输入: path, 文件路径
返回: 形状 1*c*h*w, 分布 -2~2
"""
style_transform = tv.transforms.Compose([
tv.transforms.ToTensor(),
tv.transforms.Normalize(mean=IMAGENET_MEAN, std=IMAGENET_STD),
])
style_image = tv.datasets.folder.default_loader(path)
style_tensor = style_transform(style_image)
return style_tensor.unsqueeze(0)
def normalize_batch(batch):
"""
输入: b,ch,h,w 0~255
输出: b,ch,h,w -2~2
"""
mean = batch.data.new(IMAGENET_MEAN).view(1, -1, 1, 1)
std = batch.data.new(IMAGENET_STD).view(1, -1, 1, 1)
mean = (mean.expand_as(batch.data))
std = (std.expand_as(batch.data))
return (batch / 255.0 - mean) / std
可以看出utils.py中主要包含以下三个功能。
- 计算Gram Matrix:利用矩阵转置的乘法即可实现,但是这里我们要对batch中的每一个样本计算Gram Matrix,因此用的是tensor.bmm(tensor2),而不是tensor.mm(tensor2)。
- 获取图片风格:根据文件名读取图片,并将它转化成tensor。这里图片的均值和标准差不是0.5和0.5,而是使用他人专门计算的ImageNet上所有图片的均值和标准差,更符合真实世界的图片的分布。人们发现按照这个数值处理的图片比简单地使用0.5作为均值和标准差效果更好。
- 将分布在0 ~ 255的图片进行标准化,和上述对风格图片的处理类似,需要注意,这里是针对Variable对象的处理。
除此之外,还有对visdom操作的封装,这里不再展示。
当我们将上述网络定义和工具函数写完之后,就可以开始训练网络了。首先来看看在config.py中都有哪些可以配置的参数。
class Config(object):
image_size = 256 # 图片大小
batch_size = 8
data_root = 'data/' # 数据集存放路径:data/coco/a.jpg
num_workers = 4 # 多线程加载数据
use_gpu = True # 使用GPU
style_path = 'style.jpg' # 风格图片存放路径
lr = 1e-3 # 学习率
env = 'neural-style' # visdom env
plot_every = 10 # 每10个batch可视化一次
epoches = 2 # 训练epoch
content_weight = 1e5 # content_loss 的权重
style_weight = 1e10 # style_loss的权重
model_path = None # 预训练模型的路径
debug_file = 'debug/debug.txt' # touch $debug_fie 进入调试模式
content_path = 'input.png' # 需要进行分割迁移的图片
result_path = 'output.png' # 风格迁移结果的保存路径
论文中训练用的图片是MS COCO数据集,读者可以从官网下载。其训练集中包含超过8万张图片,超过13GB。笔者认为COCO的数据比ImageNet的数据更复杂,更像是日常生活的照片。读者如果有ImageNet的图片,也一样可以用。获取数据之后,将数据解压到data/coco/文件夹下,或放到任意位置,然后在训练时指定对应路径。
我们可以在main.py中直接利用ImageFolder和DataLoader加载数据。
# 数据加载
transfroms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size),
tv.transforms.CenterCrop(opt.image_size),
tv.transforms.ToTensor(),
tv.transforms.Lambda(lambda x: x * 255)
])
dataset = tv.datasets.ImageFolder(opt.data_root, transfroms)
dataloader = data.DataLoader(dataset, opt.batch_size)
# 转换网络
transformer = TransformerNet()
if opt.model_path:
transformer.load_state_dict(t.load(opt.model_path, map_location=lambda _s, _: _s))
transformer.to(device)
# 损失网络 Vgg16
vgg = Vgg16().eval()
vgg.to(device)
for param in vgg.parameters():
param.requires_grad = False
# 优化器
optimizer = t.optim.Adam(transformer.parameters(), opt.lr)
# 获取风格图片的数据
style = utils.get_style_data(opt.style_path)
vis.img('style', (style.data[0] * 0.225 + 0.45).clamp(min=0, max=1))
style = style.to(device)
# 风格图片的gram矩阵
with t.no_grad():
features_style = vgg(style)
gram_style = [utils.gram_matrix(y) for y in features_style]
# 损失统计
style_meter = tnt.meter.AverageValueMeter()
content_meter = tnt.meter.AverageValueMeter()
训练步骤在8.1节已经讲过,按照训练步骤,很容易写出如下训练代码:
for epoch in range(opt.epoches):
content_meter.reset()
style_meter.reset()
for ii, (x, _) in tqdm.tqdm(enumerate(dataloader)):
# 训练
optimizer.zero_grad()
x = x.to(device)
y = transformer(x)
y = utils.normalize_batch(y)
x = utils.normalize_batch(x)
features_y = vgg(y)
features_x = vgg(x)
# content loss
content_loss = opt.content_weight * F.mse_loss(features_y.relu2_2, features_x.relu2_2)
# style loss
style_loss = 0.
for ft_y, gm_s in zip(features_y, gram_style):
gram_y = utils.gram_matrix(ft_y)
style_loss += F.mse_loss(gram_y, gm_s.expand_as(gram_y))
style_loss *= opt.style_weight
total_loss = content_loss + style_loss
total_loss.backward()
optimizer.step()
完整的代码请查看本书的配套源码。这个程序中容易让人混淆的是图片的尺度,有时是0 ~ 1,有时是-2 ~ 2,还有时是0 ~ 255,统一说明如下。
- 图片每个像素的取值范围为0 ~ 255。
- 调用torchvision的transforms.ToTensor()操作,像素会被转换到0 ~ 1。
- 这时如果进行标准化(减去均值、除以标准差),均值和标准差均为0.5,那么标准化之后图片的分布就是-1 ~ 1,但在本次实验中使用的均值和标准差不是0.5,而是[0.485, 0.456, 0.406]和[0.229, 0.224, 0.225],这时在ImageNet 100万张图片上计算得到的图片的均值和标准差,可以估算得知这时图片的分布范围大概在 ( 0 − 0.485 ) 0.229 ≈ − 2.1 \frac{(0-0.485)}{0.229} \approx -2.1 0.229(0−0.485)≈−2.1和 ( 1 − 0.406 ) 0.225 ≈ 2.7 \frac{(1-0.406)}{0.225} \approx 2.7 0.225(1−0.406)≈2.7之间。尽管这时它的分布在-2.1 ~ 2.7,但是它的均值接近0,标准差接近1,采用ImageNet图片的均值和标准差作为标准化参数的目的是图像的各个像素的分布接近标准分布。
- VGG-16网络的输入图像数值大小为使用ImageNet均值和标准差进行标准化之后的图片数据,即-2.1 ~ 2.7。
- TransformerNet网络的输入图片的像素值是0 ~ 255,输出的像素值也希望是0 ~ 255,但是由于没有做特殊处理,所以可能出现小于0和大于255的像素。
- 使用visdom images进行可视化和使用torchvision.utils.save_image保存图片时,希望tensor的数据位于0 ~ 1。
当我们掌握了上述内容后,就不难理解为什么在代码中时不时地出现各种尺度变换(乘以标准差、加上均值)和截断操作。尺度变换是为了从一个尺度变成另一个尺度,截断是为了确保数值在一定范围之内(0 ~ 1或者0 ~ 255)。
除了训练模型,我们还希望能加载预训练好的模型对指定的图片进行风格迁移的操作,这部分的代码实现如下。
@t.no_grad()
def stylize(**kwargs):
opt = Config()
for k_, v_ in kwargs.items():
setattr(opt, k_, v_)
device=t.device('cuda') if opt.use_gpu else t.device('cpu')
# 图片处理
content_image = tv.datasets.folder.default_loader(opt.content_path)
content_transform = tv.transforms.Compose([
tv.transforms.ToTensor(),
tv.transforms.Lambda(lambda x: x.mul(255))
])
content_image = content_transform(content_image)
content_image = content_image.unsqueeze(0).to(device).detach()
# 模型
style_model = TransformerNet().eval()
style_model.load_state_dict(t.load(opt.model_path, map_location=lambda _s, _: _s))
style_model.to(device)
# 风格迁移与保存
output = style_model(content_image)
output_data = output.cpu().data[0]
tv.utils.save_image(((output_data / 255)).clamp(min=0, max=1), opt.result_path)
这样,我们就可以通过命令行的方式训练,或者加载预训练好的模型进行风格迁移。
# 训练,使用GPU,数据存放于data/下的一个文件夹中
python main.py train \
--use-gpu \
--data-root=data \
--batch-size=2
# 风格迁移,不使用GPU
python main.py stylize \
--model-path='transformer.pth' \
--content-path='amber.jpg' \
--result-path='output.png' \
--use-gpu=False
8.3 实验结果分析
在本例中我们只训练了一个风格的模型,风格图片如下图所示。

风格迁移的结果所下图所示。上面一行是原始图片,下面一行是风格迁移的结果。

随书附带代码中带有这个预训练的模型,读者可以用其他图片查看风格迁移的效果,图片分辨率越高,风格迁移的效果越好。另外读者也可以通过指定–style-path=my_style.png训练不同风格的迁移图片。
例如:我们有一张高清美女图片如下,使用自己训练出来的模型迁移风格,效果如下。
python main.py stylize \
--model-path='checkpoints/1_style.pth' \
--content-path='amber.jpg' \
--result-path='output.png' \
--use-gpu=False

除了风格迁移,类似的应用还有Google DeepDream,可以输入一张图片生成神经网络眼中的这张图片的样子,网络越深,生成的图片包含的奇幻东西越多,效果如下所示。

2017年有两个比较吸引人的风格迁移项目,一个是来自Adobe的图片风格深度迁移(Deep Photo Style Transfer),这是由康奈尔大学的中国留学生和Adobe公司的工程师共同合作的一个新项目,通过深度学习的图片处理方法,直接提取了参考图片的风格,并转换为相对应的滤镜,其效果如下图所示,最左边是原图,中间是目标风格图片,最右边是将中间的风格迁移到左边的结果。
另一个项目是来自UC Berkeley的CycleGAN,它能够胜任任何的图像转换和图像翻译任务,在风格迁移上的效果尤其令人瞩目。CycleGAN的网络结构和Fast Neural Style的transformer类似,但它采用了GAN的训练方式,能够实现风格的双向转换,更加通用。

在本章,我们学会了如何实现一个深度学习中很酷的应用:风格迁移。不仅讲解了它的原理、风格损失和内容损失的实现,还用PyTorch实现了相应的代码。