数据存储方式之 TXT 文本
Java 操作文件输入流与输出流,具体内容包括 File 类、文件字节流与字符流、缓冲流。最后以网络爬虫实战案例,讲解其具体的使用方式。
输入流、输出流简介
在 Java 中,流是从源到目的地的字节的有序序列。Java 中有两种基本的流——输入流和输出流。输入流与输出流提供了一条通道,使用该通道可以读取源中的数据或者把数据传送到目的地。示意图如下:

Java 中 java.io 包几乎包含了所有操作输入、输出需要的类。Java 把 InputStream 抽象类的子类创建的流对象称作为字节输入流(FileInputStream)、OutputStream 抽象类的子类创建的流对象是字节输出流(FileOutputStream)。再者,Java 把 Reader 的抽象类的子类创建的流对象称作为字符输入流(FileReader),将 Writer 抽象子类创建的流对象称之为输出流(FileWriter);另外,Java 中也提供了更高级的流——缓冲输入流 BufferedReader、输出流 BufferedWriter。在本篇中,将讲解这些操作的使用。
File 类的使用
File 对象主要用来获取文件本身的一些信息,包括文件所在的目录、文件是否可读、文件是否存在、文件长度等等,不会涉及到文件的具体读写操作。
以下是 File 类经常使用的一些方法:

在使用 File 类时,第一步需要创建一个文件对象,使用如下方式进行创建:
File file = new File("data/");
以下是一个具体的案例,大家可以看看该类中一些方法的使用。
File root = new File("data/");
//判断文件是否问一个目录
Boolean is_directory = root.isDirectory();
System.out.println(root.isDirectory());
//如果是一个目录
if (is_directory) {
//获取目录下所有文件和目录的绝对路径,得到的是File数组
File[] files = root.listFiles();
for ( File file : files ){
System.out.println("文件名称为:" + file.getName());
System.out.println("文件可读否:" + file.canRead());
System.out.println("绝对路径:"+file.getAbsolutePath());
System.out.println("文件的长度为:" + file.length());
}
}
在上述程序中,data/ 为一个目录,该目录中有两个文件(1.txt 和 2.txt),执行上述程序可得到如下结果:

文件字节流
字节流,处理的单元为1个字节,用于操作字节和字节数组,其能够很好的处理图片、PDF、音频等文件。但使用字节流处理中文,经常会出现乱码,主要原因是一个中文汉字占用了2个字节。因此,在操作包含中文字符的字符串时,不建议使用字节流操作。在 Java 中,字节流类继承自 InputStream 和 OutputStream,其子类主要有 FileInputStream 和 FileOutputStream。
下面显示了四个构造方法,分别是创建文件字节输入流以及文件字节输出流的方法:
//创建文件字节输入流的两种方式
FileInputStream inputStream = new FileInputStream("data/1.txt");
FileInputStream inputStream = new FileInputStream(new File("data/1.txt"));
//创建文件字节输出流的两种方式
FileOutputStream outputStream = new FileOutputStream("data/out.txt");
FileOutputStream outputStream = new FileOutputStream(new File("data/out.txt"));
其中,以字节为单位读写文件主要用到的方法有:
read(); //顺序读取文件的单个字节
read(byte b[]); //byte数值用于临时成块存放字节
write(byte b[]);//字节写入文件
write(byte b[], int off, int len); //从给定字节数组中起始于偏移量off处写len个字节
读写操作完成之后,需要使用 close() 方法,关闭打开的流。以下给出了一个简单的使用案例:
//创建文件字节输入流与输出流
//FileInputStream inputStream = new FileInputStream("data/1.txt");
FileInputStream inputStream = new FileInputStream(new File("data/1.txt"));
FileOutputStream outputStream = new FileOutputStream("data/out.txt");
//FileOutputStream outputStream = new FileOutputStream(new File("data/out.txt"));
int temp;
//读写操作
while ((temp = inputStream.read()) != -1) {
System.out.print((char)temp);
outputStream.write(temp);
}
//流的关闭
outputStream.close();
inputStream.close();
文件字符流
在上面一小节中,提到文件字节流不能很好地处理中文字符,这时可以使用字符流操作。与 FileInputStream 和 FileOutputStream 字节流相对应的是 FileReader 和 FileWriter,它们分别继承自 Reader 和 Writer 这两个抽象类。其基本构造方法如下:
//两种文件字符输入流创建方式
FileReader fileReader = new FileReader("data/1.txt");
//FileReader fileReader = new FileReader(new File("data/1.txt"));
//两种文件字符输出流创建方式
FileWriter fileWriter = new FileWriter("data/outtest.txt");
//FileWriter fileWriter = new FileWriter(new File("data/outtest.txt"));
字符输入流和输出流的 read 和 write 方法,以字符为单位读写数据。其基本使用方法与字节流相同。
read(); //顺序读取文件的单个字符
read(char b[]); //用于临时成块存放字符
write(char b[]);//字符写入文件
write(char b[], int off, int len); //从给定字符数组中起始于偏移量off处写len个字符
以下给出了一个具体的案例程序,其中读和写的文本皆为中文字符:
//两种文件字符输入流创建方式
FileReader fileReader = new FileReader("data/3.txt");
//FileReader fileReader = new FileReader(new File("data/1.txt"));
//两种文件字符输出流创建方式
FileWriter fileWriter = new FileWriter("data/outtest.txt");
//FileWriter fileWriter = new FileWriter(new File("data/outtest.txt"));
int temp;
while ((temp = fileReader.read()) != -1) {
System.out.print((char)temp);
fileWriter.write((char)temp);
}
fileWriter.close();
fileReader.close();
缓冲流
字节流与字符流都是无缓冲的输入、输出流,每一次的读写都涉及到磁盘的读写操作,相比于内存操作要慢得多。所以,使用字节流和字符流的操作效率要比缓冲流操作低。另外,缓冲流提供了很好的 readLine 操作,即按行操作。在一些机器学习算法的输入中,经常使用到缓冲流的按行读取操作,例如,分词与句子情感计算、主题模型(每一行表示一个文档)等。在网络爬虫中,经常使用到缓冲流来读取需要爬取的 URL 列表以及保存爬取的字符型数据。
Java 中,经常使用到的是 BufferedReader 和 BufferedWriter(缓冲流中的字符流)。其主要构造方法如下:
//输入流
BufferedReader(Reader in, int sz) //创建一个使用指定大小输入缓冲区的缓冲字符输入流。
BufferedReader(Reader in) //创建一个使用默认大小输入缓冲区的缓冲字符输入流
//输出流
BufferedWriter(Writer out, int sz) //创建一个使用给定大小输出缓冲区的新缓冲字符输出流
BufferedWriter(Writer out) //建一个使用默认大小输出缓冲区的缓冲字符输出流
经常使用到的方法是 readLine() 操作,即读取一行。而写操作主要是 write(),下面通过程序带大家了解它们的具体使用方法:
/****** 文件读取第一种方式 ******/
File file = new File("data/3.txt");
//FileReader读取文件
FileReader fileReader = new FileReader(file);
//根据FileReader创建缓冲流
BufferedReader bufferedReader = new BufferedReader(fileReader);
String s = null;
//按行读取
while ((s = bufferedReader.readLine())!=null) {
System.out.println(s);
}
//流关闭
bufferedReader.close();
fileReader.close();
/****** 文件读取第二种方式 ******/
//这里简写了,已成了一行。可以添加字符编码
BufferedReader reader = new BufferedReader( new InputStreamReader( new FileInputStream( new File( "data/3.txt")),"utf-8"));
String s1=null;
while ((s1 = reader.readLine())!=null) {
System.out.println(s1);
}
//流关闭
reader.close();
/****** 文件写入第一种方式 ******/
/*File file1 = new File("data/bufferedout.txt","gbk");
FileOutputStream fileOutputStream = new FileOutputStream(file1);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(fileOutputStream);
BufferedWriter bufferedWriter1 = new BufferedWriter(outputStreamWriter);*/
/****** 文件写入快捷方式******/
BufferedWriter writer = new BufferedWriter( new OutputStreamWriter( new FileOutputStream( new File("data/bufferedout.txt")),"gbk"));
Map map = new HashMap();
map.put(0, "http://pic.yxdown.com/list/2_0_2.html");
map.put(1, "http://pic.yxdown.com/list/2_0_3.html");
map.put(2, "http://pic.yxdown.com/list/2_0_4.html");
//map遍历数据
for( Integer key : map.keySet() ){
writer.append("key:"+key+"\tvalue:"+map.get(key));
writer.newLine(); //写入换行操作
}
//流关闭
writer.close();
网络爬虫中的文本存储实例
接下来,我们将通过一个具体实战案例,讲解网络爬虫中涉及到的文本操作。爬取的网站为网易汽车某论坛(网址为:http://baa.bitauto.com/CS55/)。
在爬取数据前,应确定要爬取的数据内容,例如我要爬取的是该网页的帖子 ID 以及帖子标题。
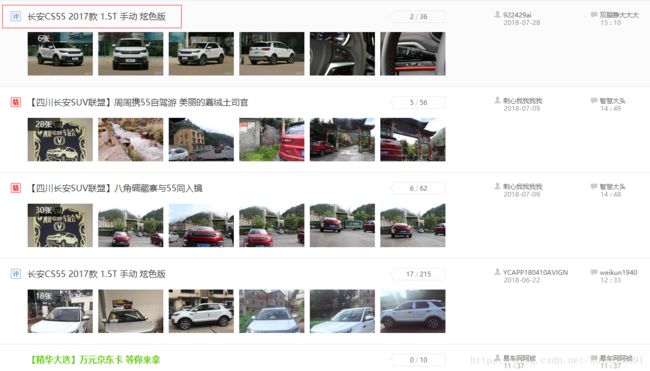
接着,根据自己所要爬取的内容,创建 Bean 对象。具体程序如下:
public class PostModel {
private String post_id; //帖子id
private String post_title; //帖子标题
public String getPost_id() {
return post_id;
}
public void setPost_id(String post_id) {
this.post_id = post_id;
}
public String getPost_title() {
return post_title;
}
public void setPost_title(String post_title) {
this.post_title = post_title;
}
}
下一步,确定需要使用的网页请求工具,这里使用较为简单的 jsoup 请求(通过如下 Maven 配置所需 Jar 包):
org.jsoup
jsoup
1.11.3
在浏览器中,定位所要爬取内容对应的标签(当然,网络抓包是有必要的),如下:
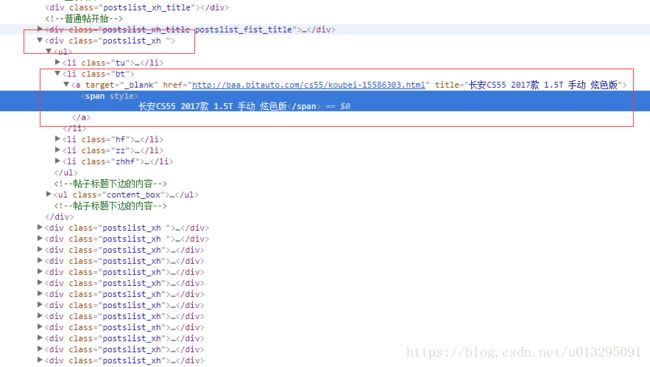
最后,编写获取数据,解析数据,保存数据的程序:
public class CrawlerTest {
public static void main(String[] args) throws IOException {
//缓冲流的创建,以utf-8写入文本
BufferedWriter writer = new BufferedWriter( new OutputStreamWriter( new FileOutputStream( new File("data/crawlerbitauto.txt")),"utf-8"));
List data = crawerData("http://baa.bitauto.com/CS55/");
for (PostModel model : data) {
//所爬数据写入文本
writer.write(model.getPost_id() + "\t" + model.getPost_title() + "\r\n");
}
//流的关闭
writer.close();
}
static List crawerData(String url) throws IOException{
//所爬数据封装于集合中
List datalist = new ArrayList();
//获取URL对应的HTML内容
Document doc = Jsoup.connect(url).timeout(5000).get();
//定位需要采集的每个帖子
Elements elements = doc.select("div[class=line-bg]").select("div[class=postslist_xh]");
//遍历每一个帖子
for (Element ele : elements) {
String post_id = ele.select("li.bt").select("a").attr("href").split("-")[1].replaceAll("\\D", "");
String post_title = ele.select("li.bt").select("a").text();
//创建对象和封装数据
PostModel model = new PostModel();
model.setPost_id(post_id);
model.setPost_title(post_title);
datalist.add(model);
}
return datalist;
}
}
上述程序执行后,便会发现所爬取采集的数据,已成功保存到了工程目录下的 data/crawlerbitauto.txt 文本中。该文本中的数据截图为:

网络爬虫下载图片实战案例
在采集数据时,有时需要采集图片、Zip 等文件,此时便可以通过字节写入的方式下载这些内容。
以下我们将通过一个实战案例进行说明,所爬取的数据为游讯图库的数据(网址为:http://pic.yxdown.com/list/204.html)。
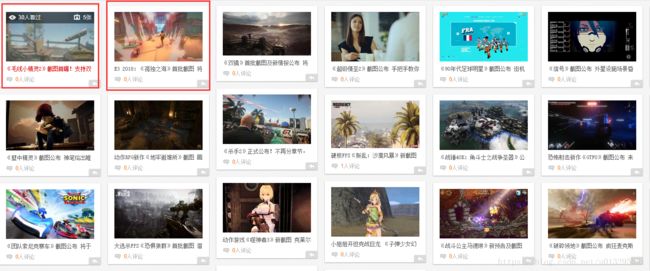
首先,需要通过抓包确认所爬取的每一张图片对应的 URL 地址。我们发现抓包对应的地址和浏览器检查图片元素对应的地址有所差异,但通过两个地址都可正常访问图片。

下载图片,我们使用的是 HttpClient 请求网页内容的方式(Maven 配置 Jar 包),如下:
org.apache.httpcomponents
httpclient
4.5.5
请求某个具体的 URL,获取实体 HttpEntity,对应的方法如下:
//请求某一个URL,获得请求到的内容
public static HttpEntity getEntityByHttpGetMethod(String url){
HttpGet httpGet = new HttpGet(url);
//获取结果
HttpResponse httpResponse = null;
try {
httpResponse = httpClient.execute(httpGet);
} catch (IOException e) {
e.printStackTrace();
}
HttpEntity entity = httpResponse.getEntity();
return entity;
}
其中,HttpClient 设置成 private static 变量:
private static HttpClient httpClient = HttpClients.custom().build();
下面,我写了一个方法,通过给定的图片地址,实现相应图片下载及保存的功能。该方法调用了 getEntityByHttpGetMethod(String url) 方法,具体程序如下:
//任意输入地址便可以下载图片
static void saveImage(String url, String savePath) throws IOException{
//图片下载保存地址
File file=new File(savePath);
//如果文件存在则删除
if(file.exists()){
file.delete();
}
//缓冲流
BufferedOutputStream bw = new BufferedOutputStream(new FileOutputStream(savePath));
//请求图片数据
try {
HttpEntity entity = getEntityByHttpGetMethod(url);
//以字节的方式写入
byte[] byt= EntityUtils.toByteArray(entity);
bw.write(byt);
System.out.println("图片下载成功!");
} catch (ClientProtocolException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//关闭缓冲流
bw.close();
}
可以看出,下载图片,这里使用的是缓冲流 BufferedOutputStream,并且写入的是字节数组。
最后,是程序的主方法。在主方法中,给定待爬的地址(http://pic.yxdown.com/list/204.html),获取该地址对应的 HTML 内容,解析 HTML 内容获取所有图片的链接地址,即图片对应的 URL。针对每个图片的 URL,调用 saveImage() 图片下载方法,便可成功爬取该页面中的所有图片。具体程序如下:
public static void main(String[] args) throws IOException{
String url = "http://pic.yxdown.com/list/2_0_4.html";
HttpEntity entity = getEntityByHttpGetMethod(url);
//获取所有图片链接
String html = EntityUtils.toString(entity);
Elements elements = Jsoup.parse(html).select("div.cbmiddle > a.proimg > img");
for (Element ele : elements) {
String pictureUrl = ele.attr("src");
saveImage(pictureUrl,"image/" + pictureUrl.split("/")[7] );
}
//测试程序
// saveImage("http://i-4.yxdown.com/2018/6/11/KDE5Mngp/ae0c2d4d-04fb-4066-872c-a8c7a7c4ea4f.jpg","image/1.jpg");
}
使用该主方法,便可成功将图片下载到指定目录下:

便于读者学习,这里提供了另外一种下载任意图片的操作方法,对应的程序如下:
//另外,一种操作方式
static void saveImage1(String url, String savePath) throws UnsupportedOperationException, IOException {
//获取图片信息,作为输入流
InputStream in = getEntityByHttpGetMethod(url).getContent();
byte[] buffer = new byte[1024];
BufferedInputStream bufferedIn = new BufferedInputStream(in);
int len = 0;
//创建缓冲流
FileOutputStream fileOutStream = new FileOutputStream(new File(savePath));
BufferedOutputStream bufferedOut = new BufferedOutputStream(fileOutStream);
//图片写入
while ((len = bufferedIn.read(buffer, 0, 1024)) != -1) {
bufferedOut.write(buffer, 0, len);
}
//缓冲流释放与关闭
bufferedOut.flush();
bufferedOut.close();
}
代码:https://github.com/soberqian/FileProcessInCrawler