一.环境的搭建
1.安装配置mysql
rpm –ivh MySQL-server-5.6.14.rpm
rpm –ivh MySQL-client-5.6.14.rpm
启动mysql
创建hive用户
grant all on *.* to hadoop@’%’ identified by ‘hadoop’;
grant all on *.* to hadoop@’localhost’ identified by ‘hadoop’;
grant all on *.* to hadoop@’master’ identified by ‘hadoop’;
创建hive数据库
create database hive_1;
2. hive的安装
tar –zxvf apache-hive-0.13-1-bin.tar.gz
3. hive的配置
vi /apache-hive-0.13-1-bin/conf/hive-site.xml
4. tar -zxvf mysql-connector-java-5.1.27.tar.gz
5. 将java connector复制到依赖库中
cp mysql-connector-java-5.1.27-bin.jar ~/apache-hive-0.13-1-bin/lib/
6. 配置环境变量
vi .bash_profile
HIVE_HOME = /home/gdou/apache-hive-0.13-1-bin
PATH=$PATH:$HIVE_HOME/bin
二.搜狗日志数据分析
1. sogou.500w.utf8预处理
数据格式
访问时间\t 用户ID \t 关键词 \t 排名\t \页数 \t URL
2.查看数据
less sogou.500w.utf8
wc -l sogou.500w.utf8
head -100 sogou.500w.utf8 sogou.tmp
3. 数据扩展
将时间字段拆分并拼接,添加年 月 日 小时字段
bash sogou-log-extend.sh sogou.500w.utf8 sogou.500w.utf8.ext
4. 数据过滤
过滤第二字段UID和第三个字段关键字为空的行
bash sogou-log-filter.sh sogou.500w.utf8.ext sogou.500w.utf8 sogou.500w.utf8.flt
5.将文件sogou.500w.utf8和sogou.500w.utf8.flt上传至HDFS上。
6.HiveQL
基本操作
hive > show databases;
hive > create database sogou;
hive > use sogou;
hive > show tables;
hive > create external table sogou.sogou20111230(timestamp string, uid string, keyword string , rank int, order int, url string)
> comment 'this is a sogou table'
> row format delimited
> fields terminated by '\t'
> stored as textfile
> location 'hdfs://master:9000/sogou/20111230';
hive>show create table sogou.sogou20111230;
hive>describe sogou.sogou20111230;
hive> select * from sogou.sogou20111230 limit 3;
select count(*) from sogou.sogou20111230;
select count(distinct uid) from sogou.sogou20111230;
7.用hiveQL完成下列查询(写出HiveQL语句)
1)统计关键字非空查询的条数;
select count(*) from sogou.sogou20111230 where keyword is not null;
结果为:5000000
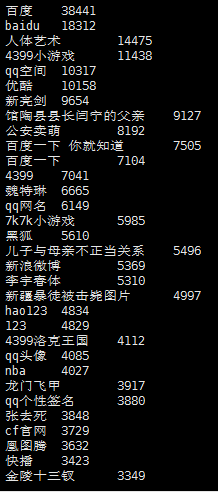
2)查询频度最高的前五十个关键字;
select keyword,count(keyword) as num from sogou.sogou20111230 group by keyword order by num desc limit 50;
3)统计每个uid的平均查询次数
select avg(bb.num) from (select count(b.uid) as num from sogou.sogou20111230 b group by b.uid) as bb;

输出结果:3.69
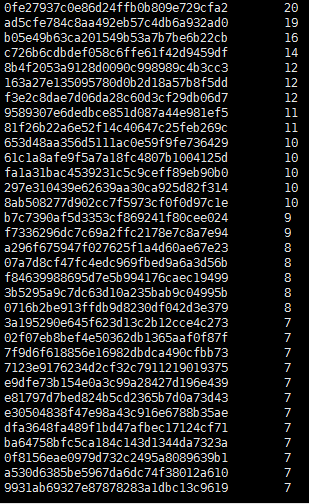
4)搜索关键字内容包含‘仙剑奇侠’超过三次的用户id
select tt.uid,tt.num from(select t.uid,count(t.uid) as num from (select * from sogou.sogou20111230 where keyword like concat('%','仙剑奇侠','%')) as t group by t.uid order by num desc) tt where tt.num > 3 limit 50;
输出结果:
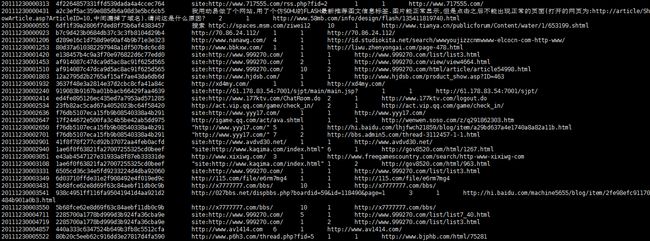
5)查找直接输入URL作为关键字的条目;
select * from sogou.sogou20111230 where keyword rlike '[a-zA-z]+://[^\s]*' limit 50;
6)统计不重复的uid的行数;
select count(DISTINCT uid) from sogou.sogou20111230;
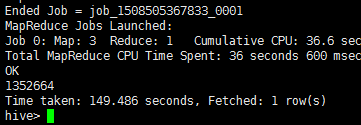
输出结果:1352664
相关资料:
链接:http://pan.baidu.com/s/1dFD7mdr 密码:xwu8