1、Keras输出的loss,val这些值如何保存到文本中去:
Keras中的fit函数会返回一个History对象,它的History.history属性会把之前的那些值全保存在里面,如果有验证集的话,也包含了验证集的这些指标变化情况,具体写法:
hist=model.fit(train_set_x,train_set_y,batch_size=256,shuffle=True,nb_epoch=nb_epoch,validation_split=0.1) with open('log_sgd_big_32.txt','w') as f: f.write(str(hist.history))
我觉得保存之前的loss,val这些值还是比较重要的,在之后的调参过程中有时候还是需要之前loss的结果作为参考的。
2.关于优化方法使用的问题:
开始总会纠结哪个优化方法好用,但是最好的办法就是试,无数次尝试后不难发现,Sgd的这种学习率非自适应的优化方法,调整学习率和初始化的方法会使它的结果有很大不同,但是由于收敛确实不快,总感觉不是很方便,我觉得之前一直使用Sgd的原因一方面是因为优化方法不多,其次是用Sgd都能有这么好的结果,说明你网络该有多好啊。其他的Adam,Adade,RMSprop结果都差不多,Nadam因为是adam的动量添加的版本,在收敛效果上会更出色。所以如果对结果不满意的话,就把这些方法换着来一遍吧。
有很多初学者人会好奇怎么使sgd的学习率动态的变化,其实Keras里有个反馈函数叫LearningRateScheduler,具体使用如下:
def step_decay(epoch):
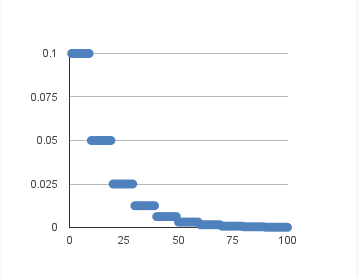
initial_lrate = 0.01 drop = 0.5 epochs_drop = 10.0 lrate = initial_lrate * math.pow(drop,math.floor((1+epoch)/epochs_drop)) return lrate lrate = LearningRateScheduler(step_decay) sgd = SGD(lr=0.0, momentum=0.9, decay=0.0, nesterov=False) model.fit(train_set_x, train_set_y, validation_split=0.1, nb_epoch=200, batch_size=256, callbacks=[lrate])上面代码是使学习率指数下降,具体如下图:
当然也可以直接在sgd声明函数中修改参数来直接修改学习率,学习率变化如下图:
sgd = SGD(lr=learning_rate, decay=learning_rate/nb_epoch, momentum=0.9, nesterov=True)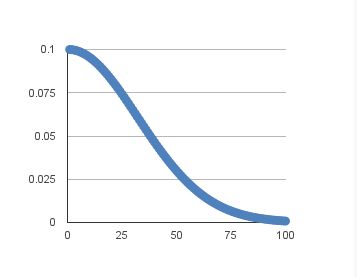
具体可以参考这篇文章Using Learning Rate Schedules for Deep Learning Models in Python with Keras
3.关于过拟合问题的讨论:
我现在所知道的解决方法大致只有两种,第一种就是添加dropout层,dropout的原理我就不多说了,主要说一些它的用法,dropout可以放在很多类层的后面,用来抑制过拟合现象,常见的可以直接放在Dense层后面,对于在Convolutional和Maxpooling层中dropout应该放置在Convolutional和Maxpooling之间,还是Maxpooling后面的说法,我的建议是试!这两种放置方法我都见过,但是孰优孰劣我也不好说,但是大部分见到的都是放在Convolutional和Maxpooling之间。关于Dropout参数的选择,这也是只能不断去试,但是我发现一个问题,在Dropout设置0.5以上时,会有验证集精度普遍高于训练集精度的现象发生(??),但是对验证集精度并没有太大影响,相反结果却不错,我的解释是Dropout相当于Ensemble,dropout过大相当于多个模型的结合,一些差模型会拉低训练集的精度。当然,这也只是我的猜测,大家有好的解释,不妨留言讨论一下。
当然还有第二种就是使用参数正则化,也就是在一些层的声明中加入L1或L2正则化系数,正则化的原理什么的我就不细说了,具体看代码:
C1 = Convolution2D(20, 4, 4, border_mode='valid', init='he_uniform', activation='relu',W_regularizer=l2(regularizer_params))其中W_regularizer=l2(regularizer_params)就是用于设置正则化的系数,这个对于过拟合有着不错的效果,在一定程度上提升了模型的泛化能力。
4.Batchnormalization层的放置问题:
BN层是真的吊,简直神器,除了会使网络搭建的时间和每个epoch的时间延长一点之外,但是关于这个问题我看到了无数的说法,对于卷积和池化层的放法,又说放中间的,也有说池化层后面的,对于dropout层,有说放在它后面的,也有说放在它前面的,对于这个问题我的说法还是试!虽然麻烦。。。但是DL本来不就是一个偏工程性的学科吗。。。还有一点是需要注意的,就是BN层的参数问题,我一开始也没有注意到,仔细看BN层的参数:
keras.layers.normalization.BatchNormalization(epsilon=1e-06, mode=0, axis=-1, momentum=0.9, weights=None, beta_init='zero', gamma_init='one')-
mode:整数,指定规范化的模式,取0或1
-
0:按特征规范化,输入的各个特征图将独立被规范化。规范化的轴由参数axis指定。注意,如果输入是形如(samples,channels,rows,cols)的4D图像张量,则应设置规范化的轴为1,即沿着通道轴规范化。输入格式是‘tf’同理。
-
1:按样本规范化,该模式默认输入为2D
我们大都使用的都是mode=0也就是按特征规范化,对于放置在卷积和池化之间或之后的4D张量,需要设置axis=1,而Dense层之后的BN层则直接使用默认值就好了。
-
reference:深度学习框架Keras使用心得