【python3网络爬虫/笔记】个人学习记录【1】-------爬取小说!
参考资料:B站小甲鱼视频,csdn内的大神前辈Jack-Cui
同时参考了各种杂乱的网站与视频hh
内容更多的是自己的笔记与总结
Python版本: Python3
运行平台: Windows
IDE: pycharm
目标:爬取小说!!
目标网址:http://www.biqukan.net/
一,爬取小说内容
先随便选了一篇简单的【小说内容】进行爬取
#coding = utf-8
import urllib.request
from bs4 import BeautifulSoup
url = 'http://www.biqukan.net/book/116945/40009955.html'
html = urllib.request.urlopen(url).read().decode('gbk')
bf = BeautifulSoup(html, 'html5lib') #此处有warning
title = bf.find_all('h1', class_ = 'readTitle') #获取标题
text = bf.find_all('div', class_ = 'panel-body') #获取内容
print(text[0].text.replace('\xa0'*4, ''))

针对以上代码所作的笔记:
- \xa0 是不间断空白符
- bf = BeautifulSoup(html),若没有加上’html5lib’会出现warning,可以用pip进行安装
- Beautiful Soup 4.4.0 中文官方文档
二,爬取章节链接+题目
def get_url():
url = 'http://www.biqukan.net/book/116945/'
html = urllib.request.urlopen(url).read().decode('gbk')
reg = re.compile(r'.*? ')
data = re.findall(reg, html)
for i in data:
book_url = url + i[0]
print(i[1] + ': ' + book_url)
笔记:
- 用beautifulsoup模块,恕我不才,不能爬取链接,用了简单的正则
- import re
三,整合代码v0.1
#coding = utf-8
import urllib.request
from bs4 import BeautifulSoup
import re
import os
def url_open(url):
html = urllib.request.urlopen(url).read().decode('gbk')
return html
#获取小说内容
def get_content(url):
html = url_open(url)
bf = BeautifulSoup(html, 'html5lib') #此处有warning
text = bf.find_all('div', class_ = 'panel-body') #获取内容
content = text[0].text.replace('\xa0'*4, '')
return content
#获取章节链接+标题
def get_book_url():
url = 'http://www.biqukan.net/book/116945/'
html = url_open(url)
book_title = []
book_url = []
book_num = 0
reg = re.compile(r'.*? ')
book_name_reg = re.compile(r'(.*?)
')
book_name = re.findall(book_name_reg, html)
data = re.findall(reg, html)
for i in data:
book_num += 1
book_url.append(url + i[0])
book_title.append(i[1])
return book_title,book_url,book_name[0],book_num
if __name__ == '__main__':
book_title = []
book_url = []
book_title, book_url, book_name, book_num = get_book_url()
path = book_name +'(共' + str(book_num) + '章)'
if not os.path.exists('./' + path):
print('当前路径下创建【'+ path +'】文件夹,\r开始下载文件')
os.mkdir(path)
os.chdir(path)
for i in range(book_num - 1):
print('下载进度:%.3f%%'% float(i/book_num) )
with open(str(i) + '.' + book_title[i] + '.txt', 'a', encoding='utf-8') as f: #笔记①
f.write(get_content(book_url[i])) #笔记②
print('下载完成!')
针对以上所作笔记:
- 笔记①:一定要改变目标文件的编码,加上encode(‘gbk’),不然会报错:’gbk’ codec can’t encode character ‘\xa0’ in position 相关网页
- 笔记②:python write和writelines的区别
- file.write(str)的参数是一个字符串,就是你要写入文件的内容.
- file.writelines(sequence)的参数是序列,比如列表,它会迭代帮你写入文件。
- 看到的效果是我用pyinstaller打包成的一个exe运行的,我觉得很帅就学了一下蛤,主要还是得用pip安装pyinstaller,再配合以下cmd命令(在py文件所在文件夹哦)
installer -F demo.py
升级前的小总结
自己动手做还是很有趣的,蛤蛤,为什么第二阶段用了re呢,因为我认为正则的(.*?)取数据有的时候不要太方便了!而且我beautifulsoup没怎么用过,摸着摸着用的hh,不过还是有问题出来了,上面的截图认真看也能看出来,以4为倍数的章节被吃掉了!!!
我尝试了很多次,都无法还原那些章节
在此也求助一下能路过看下的朋友,到底是为什么啊啊啊,崩溃
之后又小小研究了一下bs,优化了一下代码,v2.0献丑了(捂脸)
笔趣网爬虫v2.0
#coding = utf-8
import urllib.request
from bs4 import BeautifulSoup
import os
def url_open(url):
html = urllib.request.urlopen(url).read().decode('gbk') #

笔记:beautifulsoup4模块
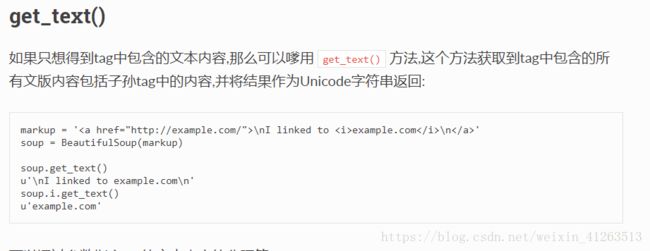
应该还有v3.0?
上面的v2.0还是略显蹩脚的,但哈哈哈哈懒得改了,刚才宿舍外面有人表白我就到外面看了
哈哈哈哈看欢呼声应该是成功了,3.0随缘吧,这次都用了bs4的模块,舍弃了正则,感觉bs4还是挺好用的
上面的功能的话就是能爬取小说啦,笔趣网上什么小说都能爬取的啵,提示也有了,不过用户需要比较繁琐的操作的,以后改进!