hadoop 3.X超详细搭建集群
之前集群搭建过hadoop2.6和2.7,但是听说hadoop3.x有新特性,减少了IO的次数,据介绍并行计算能力是spark的10倍。所以,笔者开始尝试搭建,找网上找了好多资料,结合自己的经验,终于搭建成功,从虚拟机安装到搭建hadoop框架花了两天时间,着实不容易哈哈。接下来,将一一介绍精简的配置搭建hadoop。
准备步骤
-
你需要准备3或者3台以上的机器来进行集群搭建,这里推荐使用多台虚拟机来搭建hadoop3.x框架。(前期工作准备好之后就可以进行下一步)
-
然后我们需要为虚拟机配置免密登陆,前提是在虚拟机需要设置内部网络,并给每台虚拟机设置一个虚拟ip用于之间相互通信。
我使用的是virtual box,在每台虚拟机有个设置,点击设置,然后选择网络,如图:
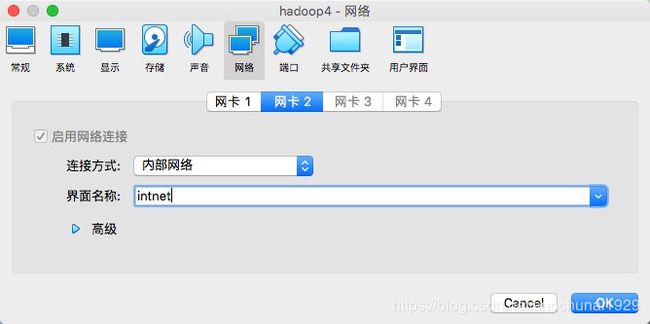
(1)打开配置虚拟IP的文件,进行如下配置:
vi /etc/network/interfaces- 1
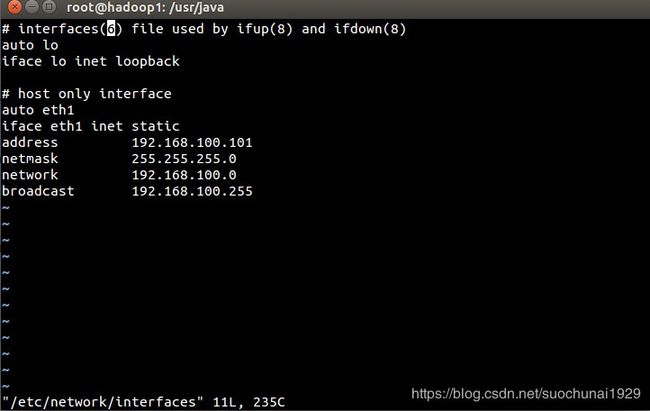
# host only interface auto eth1 iface eth1 inet static address 192.168.100.101 netmask 255.255.255.0 network 192.168.100.0 broadcast 192.168.100.255
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
adress: 设置的是虚拟IP,这个可以自己设置
network:子网掩码
network: 是设置ip地址的网关
broadcast: 按照上述格式配置
(2)接下来配置主机名
vi /etc/hostname
- 1
修改自己的主机名,如图:

我这里配置了4台主机,名称分别为:hadoop1,hadoop2,hadoop3,hadoop4
hadoop1作为namenode节点,其余三台作为datanode节点
配置各台虚拟机的IP映射
vi /etc/hosts
- 1
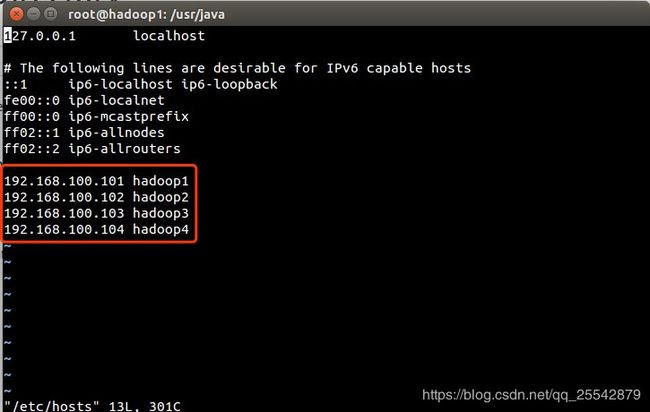
尝试每台虚拟机使用主机名ping通,如果ping不通,则重启之后再尝试。
ping命令:
ping hadoop2 #使用自己配置的主机名
- 1
重启命令:
reboot
- 1
(注:我使用的是ubuntu系统,配置虚拟IP的方式与其他版本的linux有所不同,如果有centos版本或者其他的linux版本请到别处浏览如何配置虚拟IP。不要慌,其实只要每个虚拟机的IP地址能相互ping通就可以忽略上述步骤。)
(3)配置免密登陆
- 生成密钥
ssh-keygen
- 1
然后一直回车,默认生成密钥文件
2)执行命令,将公钥复制到其余3台机器上
ssh-copy-id hadoop2 #其余三台的主机名
ssh-copy-id hadoop3
ssh-copy-id hadoop4
- 1
- 2
- 3
3)检查hadoop1连接其余三台的连接情况
ssh hadoop2 //免密登陆hadoop2,第一次操作会让你选择,输入yes
exit //退出,回到hadoop1
ssh hadoop3
exit
ssh hadoop4
exit
- 1
- 2
- 3
- 4
- 5
- 6
注:这里只是配置了hadoop1与其余三台的ssh免密登陆,如果上述操作顺利,hadoop2,hadoop3,hadoop4也要依次重复上述步骤,否则请重复上述步骤
检查防火墙状态,关闭防火墙
sudo ufw status #检查防火墙状态
- 1

sudo ufw disable #关闭防火墙
- 1

(注: 以上是使用ubuntu版本的操作命令,其他linux版本的操作请参考其他资料)
下载jdk1.8并进行安装配置(hadoop3.x只支持1.8版本或以上)
(1) 先到oracle官网下载jdk-8uXXX-linux-x64.tar.gz (或自己手动到网上搜索下载)
(2) 在主机上创建文件夹用来存放解压的jdk1.8
mkdir -p /usr/java
- 1
(3) 切换到下载jdk的位置,解压jdk1.8安装包,并解压到指定目录
tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/java
- 1

cd jdk1.8.0_211 //切换到jdk目录下
pwd //复制此路径,用于配置环境变量
- 1
- 2
(4)配置环境变量
vi /etc/profile //打开配置文件
- 1
滚动到最底下, 按住shift+i,进入编辑状态,配置如下:
export JAVA_HOME=/usr/java/jdk1.8.0_211
export JRE_HOME=/usr/java/jdk1.8.0_211/jre
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/ tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
- 1
- 2
- 3
- 4
- 5
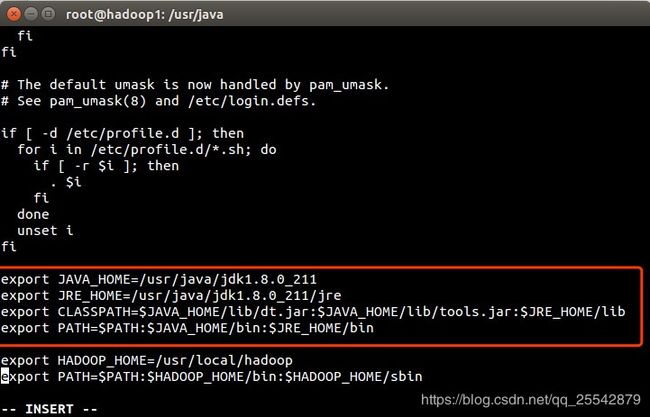
让环境变量立即生效
source /etc/profile
- 1
(4)检验配置是否成功
java -version
- 1

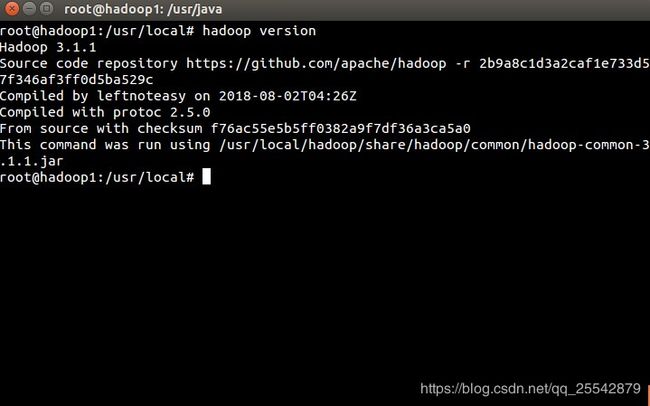
如果出现上图类似得版本信息,说明配置成功!!!
hadoop3.x安装搭建
这里我下载hadoop的版本是3.1.1,下载地址:
https://archive.apache.org/dist/hadoop/core/hadoop-3.1.1/
-
切换到想要下载的目录,使用命令下载到虚拟机上,前提是要确保虚拟机能够连接上外网。
wget https://archive.apache.org/dist/hadoop/core/hadoop-3.1.1/hadoop-3.1.1.tar.gz- 1
-
创建一个存放hadoop文件的目录
mkdir -p /usr/local/hadoop- 1
-
切换到hadoop安装包路径,解压hadoop安装包到创建的目录
tar -zxvf hadoop-3.1.1.tar.gz -C /usr/local/hadoop- 1
-
开始配置hadoop环境变量
vi /etc/profile- 1
进入编辑状态,配置下列信息:
export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin- 1
- 2
让环境变量立即生效
source /etc/profile- 1
检验hadoop 环境变量配置是否生效
hadoop version- 1
-
开始进行hadoop的集群文件配置,在配置前,我们只需要对一台虚拟机(节点)配置就可以,其余3台虚拟机(3个节点)只需要将配置好的那台虚拟机复制过来就可以了。
配置文件目录 (在安装目录 /usr/local/hadoop/etc/hadoop/ 下)
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- workers
hadoop文件配置
-
首先,配置hadoop-env.sh文件,如图所示:

找到已经注释了"export JAVA_HOME"的代码行,按照上图写入对应的变量。参考代码
export JAVA_HOME=/usr/java/jdk1.8.0_211 export HADOOP_PID_DIR=/usr/local/hadoop/hadoop_data/tmp/pids export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_SECONDARYNAMENODE_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root- 1
- 2
- 3
- 4
- 5
- 6
- 7
配置注意事项
1.JAVA_HOME的路径一定要填写绝对路径!
2.HADOOP_PID_DIR的值可以先填上去,后面再去创建,创建的时候最好放在hadoop安装目录下,而且只需要创建到tmp文件夹就行,pids会自动生成,方便拷贝到其他节点(虚拟机)上
3.其余的KEY对应的值都是root,按照上图配置就好了
-
配置core-site.xml文件,如图所示:
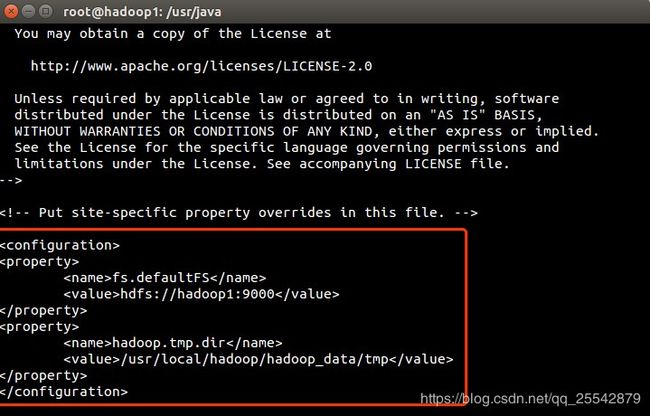
参考代码
fs.defaultFS hdfs://hadoop1:9000 hadoop.tmp.dir /usr/local/hadoop/hadoop_data/tmp - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
配置说明
- fs.defaultFS 配置哪个节点来启动hdfs
- hadoop.tmp.dir 配置hadoop存储数据的路径,
- 我们需要手动创建这个目录,上面的步骤已经说明了
-
配置hdfs-site.xml文件,如图所示:
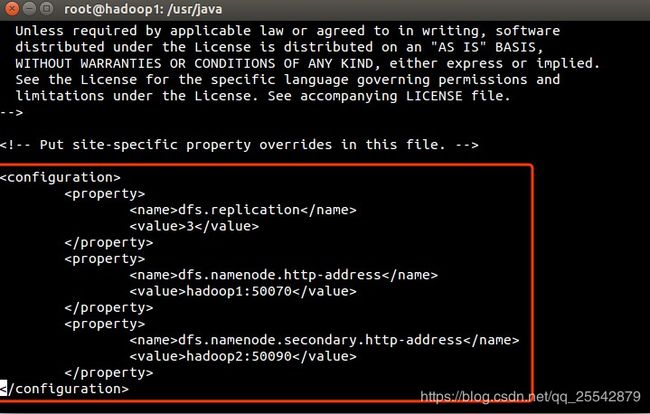
参考代码
dfs.replication 3 dfs.namenode.http-address hadoop1:50070 dfs.namenode.secondary.http-address hadoop2:50090
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
配置说明
- dfs.replication 设置文件的备份数量
- dfs.namenode.http-address 设置哪台虚拟机作为namenode节点
- dfs.namenode.secondary.http-address 设置哪台虚拟机作为冷备份namenode节点,用于辅助namenode
配置mapred-site.xml文件,如图所示:
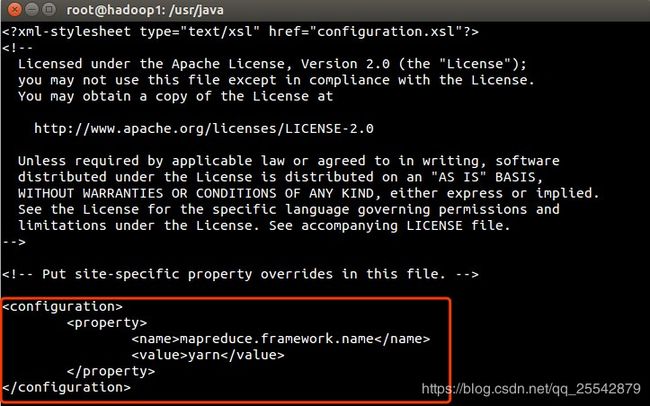
参考代码
mapreduce.framework.name
yarn
- 1
- 2
- 3
- 4
- 5
- 6
配置说明
- mapreduce.framework.name 配置yarn来进行任务调度
配置yarn-site.xml文件,如图所示:
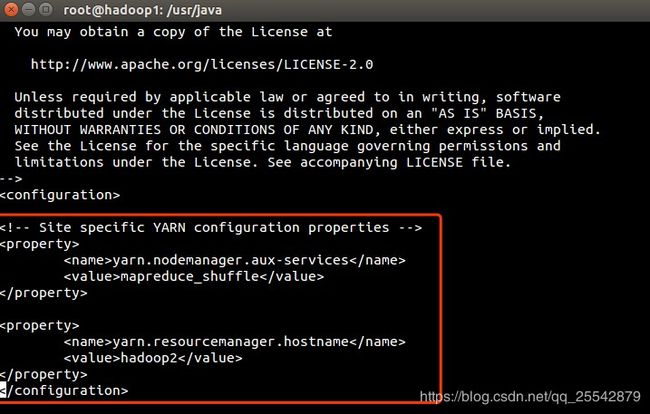
参考代码
yarn.nodemanager.aux-services mapreduce_shuffle <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop2</value> </property> <property> <name>yarn.application.classpath</name> <value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
配置说明
- yarn.resourcemanager.hostname 配置yarn启动的主机名,也就是说配置在哪台虚拟机上就在那台虚拟机上进行启动
- yarn.application.classpath 配置yarn执行任务调度的类路径,如果不配置,yarn虽然可以启动,但执行不了mapreduce。执行hadoop classpath命令,将出现的类路径放在
标签里
(注:其他机器启动是没有效果的)
配置workers文件,如图所示:
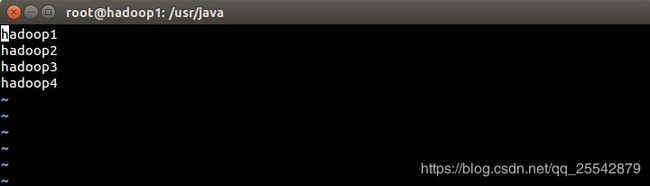
参考代码
hadoop1
hadoop2
hadoop3
hadoop4
- 1
- 2
- 3
- 4
配置说明
- workers 配置datanode工作的机器,而datanode主要是用来存放数据文件的,我这里配置了4台,可能你会疑惑,hadoop1怎么也可以配置进去。其实,hadoop1我既配置作为namenode,它也可以充当datanode。当然你也可以选择不将namenode节点也配置进来。
以上文件配置完毕之后,我们就可以用这台配置好的节点进行远程拷贝了。
1. 首先,我们需要前期准备工作,先把其余有安装过hadoop的机器进行清除,在安装路径统一的情况下,这样方便我们前期的清理。
假设我配置好的文件放在hadoop1节点上,我将执行如下步骤:
-
免密登陆到节点hadoop2,执行清理hadoop安装目录(其他机器没有安装的朋友可以不用操作此步骤)
ssh hadoop2 rm -rf /usr/local/hadoop exit- 1
- 2
- 3
同理,按照上述步骤清理其余机器hadoop的安装目录
2. 然后,我们进行远程拷贝操作,有两份需要拷贝,一份是环境变量,一份是hadoop的安装文件
-
我们在当前配置过的节点hadoop1上执行远程拷贝命令
``` scp -r /usr/local/hadoop hadoop2:/usr/local scp -r /etc/profile hadoop2:/etc ```- 1
- 2
- 3
- 4
-
拷贝完成之后,我们远程到hadoop2上,让环境变量立即生效
``` ssh hadoop2 source /etc/profile hadoop version ```- 1
- 2
- 3
- 4
- 5
如果控制台显示出hadoop版本信息,则环境变量生效,执行退出
exit -
同理,按照上述步骤去远程拷贝其余节点
3. 搭建工作已经全部就绪,现在我们要来启动hadoop。如果有将hadoop的sbin和bin路径配置到环境变量PATH路径上则不用切换到如下路径:
cd /usr/local/hadoop/bin
- 1
-
首先,我们要对namenode进行格式化:
hdfs namenode -format- 1
-
如果严格按照上述配置执行,那格式化namenode是不会失败的,如果失败,请到各个节点的tmp路径进行删除操作,然后重新格式化namenode。
切换到sbin路径上,启动hdfs:
cd /usr/local/hadoop/sbin
./start-dfs.sh
- 1
- 2
- 3
启动成功之后,使用jps可以看到各个节点的进程。
hadoop1的进程,如图:

hadoop2的进程,如图:

hadoop3的进程,如图:

hadoop4的进程,如图:

4.接下来,我们可以打开hadoop自带的管理也页面。在浏览器上输入:
hadoop1:50070
- 1
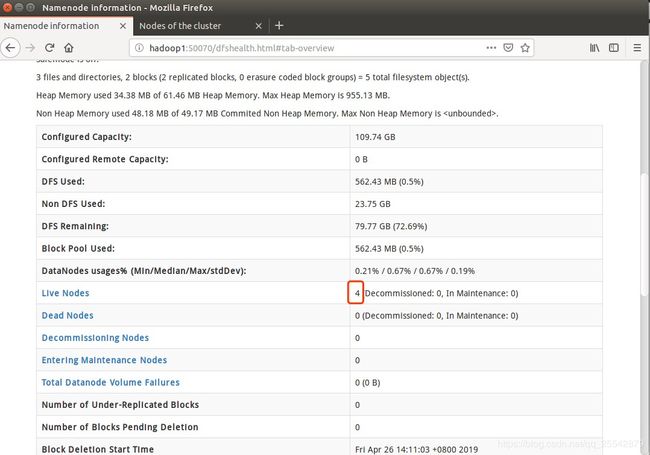
如图:
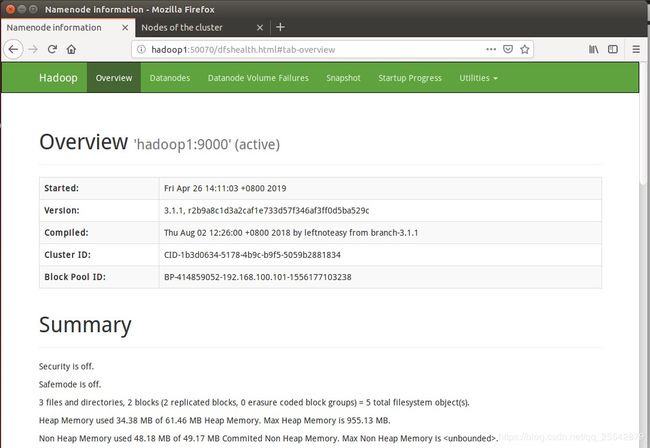
想要检查是否4台机器已经做了集群也可以在上面看,如图红框部分显示4个存活节点:
5.这还不算搭建完成,还需要启动yarn来进行任务调度,我们远程到hadoop2街店切换到sbin路径下:
ssh hadoop2
cd /usr/local/hadoop/sbin
./start-yarn.sh
- 1
- 2
- 3
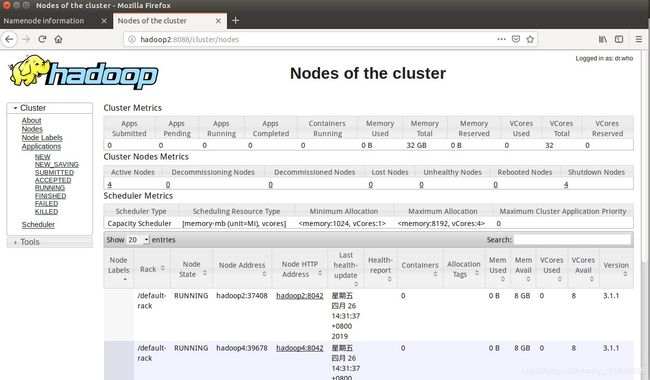
启动成功之后,hadoop2的进程界面如图:

在浏览器上输入:
hadoop2:8088
- 1
yarn的管理界面:
6. 最后,hadoop搭建大功告成,接下来就可以进行hadoop命令进行文件操作和并行计算了。