分析obj文件,理解重定位过程以及obj文件在程序中扮演的角色
一、待分析的程序源代码
#include
#include
typedef void (*TestFunc)();
void test()
{
printf("hello world!");
};
int gi = 0x12345678;
void test2()
{
printf("to prove compiler will generate a code-section for each {} ");
}
void main()
{
gi = 0;
TestFunc ptrFunc = test;
test();
return ;
} 二、使用PEView开始分析编译成的.obj文件,.obj 文件使用的是COFF 格式
如图:
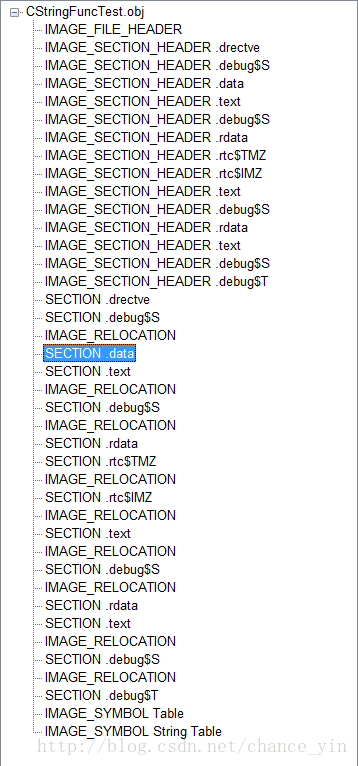
各字段介绍:
是个程序员都知道,程序在运行时内存中会分为好几个区域:代码段、数据段、堆、栈
开始今天的分析:堆栈段在程序运行时变化。而代码段和数据段则是在程序运行时被加载到内存后就确定了的。
在 .obj 文件中,SECTION.txt 即代码段, SECTION.data 即数据段,SECTION.rdata 即只读数据段。这些数据段中的数据在程序根据IMAGE_BASE加载到内存指定位置后,会经过重定位直接加载到内存中指定位置。(这一步骤就是我们常说的全局变量在程序开始执行的时候就分配了空间,并在程序结束时释放空间)
再贴出来各字段对应的内容和含义
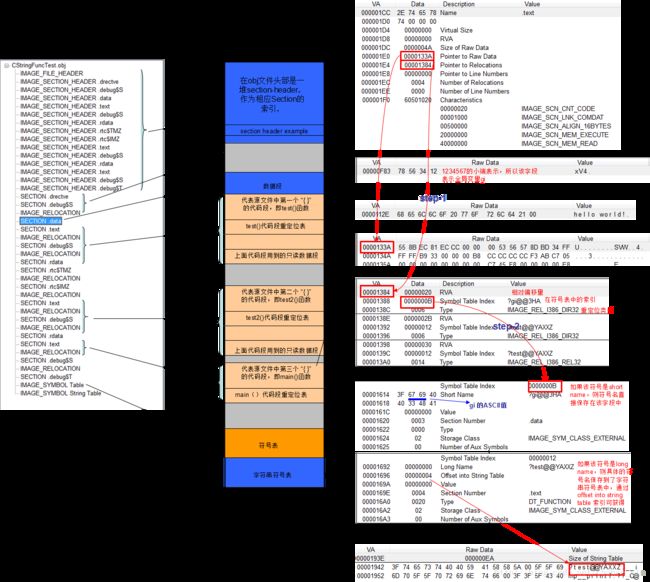
上面的图已经列出来了大部分字段的含义和作用。下面再需要讲的就是重定位具体步骤。
三、COFF文件格式下的重定位方法
将 机器码(obj文件)中所有需要使用符号地址的位置全部置零,并将这些位置作为一个重定位元素记录到属于该代码段的重定位表中。在程序链接时,链接器会根据重定位元
素等相关信息计算好运行时的偏移量或地址然后回填到相关机器码中。

典型的如上图,E8是call指令的操作码,它后面需要使用函数入口地址的相对偏移量,所以在编译时,编译器将它们全部置成0.
链接器在将所有的obj文件组合完成后,会生成一个全局表,从该表中可以查到所有符号的绝对地址 SymbolAddress,链接器是通过符号名为索引查找该表的。
接着链接器会重复做以下工作
1、从当前obj文件中,以每个section header的 pointer to relocations 字段作为索引,找到相应的relocationtables(重定位表IMAGE_RELOCATION),过程见Step-1
2、 遍历重定位表中的每个元素relocationtables[i],
(1)计算addressToBeRelocate = relocationtables[i].rva (相对段的偏移量) + 段偏移,addressToBeRelocate 即需要重定位的字段在机器码中的地址。
(2)以Symbol Table index作为索引去符号表中找到相应的符号元素symbolTable[i],从SymbolTable[i] 获取到符号名symbolName,并用symbolName作为索引到全局表中找到该符号的绝对地址symbolAddress
流程如下:

3、if( relocationtables[i].type 是绝对定位) //全局变量,函数指针需要使用绝对地址
{
*(addressToBeRelocate) = symbolAddress
}
else //是相对定位 //call 指令使用相对地址
{
*(addressToBeRelocate) = symbolAddress - (重定位地址+4) //+4是因为相对转移指令call jmp从该指令的下一条指令处计算偏移
}
四、注
1、实际上如果给重定位表的元素足够多的字段(记录相对偏移,符号名等信息),那么重定位表完全能够履行符号表的作用。COFF引入符号表的目的是考虑到源代码中可能多处要引用某个符号,多处引用,就需要为每个引用都生成重定位项,这显然造成了空间浪费,所以为了能够重用这些信息达到减少使用空间的目的,COFF只是在重定位表的元素中保存一个索引(4个字节),然后通过索引去引用符号表中的元素。
2、Symbol table 元素中一些字段的解释

3、编译产生OBJ文件时,遇到全局变量名或函数名(统称符号名),则编译器只在机器码中留下一个占位符(00 00 00 00 )代表之后需要进行重定位处理。同时,把该符号存到符号表。等到链接时从本OBJ文件或其他OBJ文件中找到该符号使用的section,并把此section合并到当前执行程序中。如果找不到,就会报符号未定义的错误。
4、分析情景 有一个test()函数定义在header.h 中,并在该文件中实现。
另有两个cpp文件 A.cpp 和 B.cpp 他们都引用了header.h,这样编译后,在A.obj 和 B.obj 中都会有一个test()函数的section节。好了编译后再链接,会出现符号已经定义的错误。通过上面的内容我们就可以分析这一错误深层次的原因:链接器在进行重定位时,需要在test符号的占位符中填入实际地址,但整个程序中有2个section定义了该符号,到底是用哪个section?链接器无法判断,所以报错。
解决方法一:将test()函数的实现放到某个cpp文件中去。
解决方法二(不推荐):将test函数的实现还是放到header.h头文件中,但test函数用static修饰。
用static修饰一个函数表示,该函数只在本CPP中可见。这样A.cpp 和 B.cpp都引入这个头文件,同样,经过编译后,在生成的A.obj 和 B.obj 中都出现了包含test函数的section节,由于该section节只对本cpp可见,所以A.cpp 中对test函数的调用只会定位到A.obj中test的section节,B.cpp亦然。
不推荐此方法的原因是:同一份包含test函数的section节会在内存中存在两份,浪费了内存资源。
最后,在解决方法一中,如果在两个CPP文件中打印test函数的入口地址,值是相同的。但在方法二中,打印结果不同。
五、局部变量虚拟地址是否应该是固定的?
按照常理,如果程序每次都被加载到一个起始地址处,那么局部变量的虚拟地址应该是一样的。但在linux下做过测试后,结果通常是局部变量的地址会随着程序的每次启动而变化。
原因就是为了防止“缓冲区溢出”导致的安全漏洞,内核通常会随机的给程序的栈分配一个起始地址。这样攻击者就无法依靠固定的地址来找到栈了。
要想随机的分配内核栈起始地址,需要对内核进行配置,具体方法是 echo 2 > /proc/sys/kernel/randomize_va_space。如果想关闭,则将该值设置成0即可。