嵌入式和Linux知识总结
嵌入式和Linux基础知识
- 1. C语言基础
- 1.1 数据类型
- 1.1.1 static和extern
- 1.1.2 volatile
- 1.1.3 typedef
- 1.1.4 union
- 1.1.5 inline内联函数
- 1.2 数据与指针
- 1.3 printf函数和i++
- 2. Linux基础
- 2.1 内存管理
- 2.1.1 Linux虚拟地址空间
- 2.1.2 内存存储空间
- 2.1.3 内存分配方式
- 2.1.4 段错误以及调试方法
- 2.2 进程与多进程
- 2.2.1 多进程
- 2.2.2 Linux进程的三态
- 2.2.3 进程创建(进程的实现)
- 2.2.4 僵尸进程
- 2.3 进程间的通信方式
- 2.3.1 管道(Pipe)和有名管道(Named Pipe或FIFO)
- 2.3.2 信号(Signal)
- 2.3.3 消息队列(Message Queue)
- 2.3.4 信号量(灯)(Semaphore)
- 2.3.5 共享内存(Shared Memory)
- 2.3.6 套接字(Socket)
- 2.4 线程与多线程
- 2.4.1 多线程
- 2.4.2 多线程的实现
- 2.4.3 线程同步机制
- 2.4.4 锁机制
- 3. 硬件接口和协议
- 3.1 ARM架构
- 3.2 RAM和ROM的区别
- 3.3 硬件接口
- 3.3.1 UART
- 3.3.2 SPI
- 3.3.3 I2C
- 3.3.4 USB
- 3.3.5 CAN
- 3.3.6 RS485
- 3.4 无线通信方式和协议
- 3.4.1 WiFi协议
- 3.4.2 BLE协议
- 3.4.3 ZigBee协议
- 3.4.4 LoRa协议
- 3.4.5 NB-IoT
- 3.5 网络通信协议
- 3.5.1 TCP
- 3.5.1 IP
- 3.5.3 UDP
- 3.5.4 HTTP
- 3.5.5 HTTPS
- 3.5.6 CoAP
- 3.5.7 MQTT
- 3.5.8 MQTT和TCP的区别
- 3.5.9 OpenSSL加密
- 3.5.9 RTSP
- 4. 数据结构
- 4.1 线性表
- 4.1.1 线性表的顺序结构
- 4.1.2 线性表的链式结构
- 4.2 栈(stack)
- 4.2.1 栈的顺序结构
- 4.2.2 两栈共享空间
- 4.2.3 栈的链式结构
- 4.3 队列(queue)
- 4.3.1 顺序队列
- 4.3.2 链式队列
- 4.4 字符串(string)
- 4.4.1 KMP模式匹配算法
- 4.5 树(tree)
- 5. 算法
- 5.1 冒泡排序和选择排序
- 5.2 查找特定数据
- 5.3 牛客网题目
- 5.3.1 数据结构
- 5.4 C语言的经典问题
- 5.4.1 汉诺塔问题
说明:本文的目的是为了简单总结嵌入式和Linux常见知识点,在本文中你可以快速将不同的知识点串起来,形成一个更加清晰的知识网络。
1. C语言基础
1.1 数据类型
1.1.1 static和extern
1.static修饰变量
(1)修饰局部变量
局部变量:存储在栈区,生命周期在该语句块执行结束时便结束。
static局部变量:存储在静态数据区,生命周期一直持续到整个程序执行结束为止。作用域没有改变,仍然是一个局部变量。
(2)修饰全局变量
static全局变量的作用域由原来的整个工程可见变为本源文件可见。
(3)修饰函数
与修饰全局变量大同小异。
2.extern
extern可以修改变量或函数,表示该变量或函数不是在本源文件内声明的。多个源文件中只能有一处对其进行初始化。
1.1.2 volatile
volatile修饰的变量表示该变量的值很容易由于外部因素发生变化。不管它的值有没有变化,每次对其值进行访问时,都会从内存里、寄存器里读取,从而保证数据的一致。
在线程间通信时由于多个线程可能更改全局变量,因此全局变量最好声明为volatile。
1.1.3 typedef
举例:
typedef struct tag_node {
char *p_item;
struct tag_node *p_next;
} *p_node;
#define和typedef的区别:
(1)#define 只是简单的字符串替换。
(2)typedef 是为一个类型起新名字。
struct和typedef struct的区别:
(1)在C中定义一个结构体类型,
第一种:
struct Student {
int a;
};
struct Student stu1;
第二种:
typedef struct Student {
int a;
} Stu;
Stu stu1; 或:struct Student stu1;
第三种:
typedef struct {
int a;
} Stu;
Stu stu1;
(2)在C++中定义一个结构体类型,
第一种:
struct Student {
int a;
};
(struct )Student stu1; // struct可省略
第二种:
struct Student {
int a;
} stu1;
第三种:
typedef struct Student {
int a;
} Stu;
Stu stu1;
1.1.4 union
union联合体:在联合体中各成员共享一段内存空间,一个联合变量的长度等于各成员中最长的长度
小端模式和大段模式:x86系列CPU都是Little endian的字节序,PowerPC通常是Big endian。
举例:
int CheckCPUType() {
union w {
int a;
char b;
} c;
c.a = 1;
return (c.b == 1); /* 若等于1,则为Little endian */
}
1.1.5 inline内联函数
一个函数被调用时,会有函数入栈(即函数栈),会造成栈空间或栈内存的消耗。
inline修饰的函数为内联函数,在调用该函数时会直接复制函数体内容,减少函数栈的开销。
void Foo(int x, int y);
inline void Foo(int x, int y)
{
}
1.2 数据与指针
xxxxxx
1.3 printf函数和i++
C语言中函数参数的执行顺序 – 从右到左;
C语言中逗号运算符的执行顺序 – 从左到右。
i++为先赋值再递增,++i为递增后再赋值。
参考:https://blog.csdn.net/gongluck93/article/details/68069194
例子1:
#include 例子2:
#include 2. Linux基础
C语言程序的过程:编辑 -> 预处理 -> 编译 -> 汇编 -> 链接 -> 执行。
2.1 内存管理
2.1.1 Linux虚拟地址空间
采用虚拟地址空间的好处:
(1)扩大地址空间(4G);
(2)每个进程独立占用空间;
(3)公用库只需保存一份在物理内存,进程拷贝到虚拟地址内存中使用;
(4)进程通信时可以采用虚拟内存共享的方式;
(5)等等。
2.1.2 内存存储空间
(1)未初始化的全局变量(.bss段)
(2)初始化过的全局变量(.data段)
(3)常量数据(.rodata段)
(4)代码(.text段)
(5)栈(stack) - 函数调用和函数内的局部变量
(6)堆(heap) - 由用户动态分配
2.1.3 内存分配方式
(1)从静态存储区分配。如全局变量、static变量等。
(2)在栈上创建。函数调用和函数局部变量等。
(3)从堆上分配。动态分配。
2.1.4 段错误以及调试方法
(1)gdb
(2)core文件
(3)backtrace和objdump进行分析
2.2 进程与多进程
2.2.1 多进程
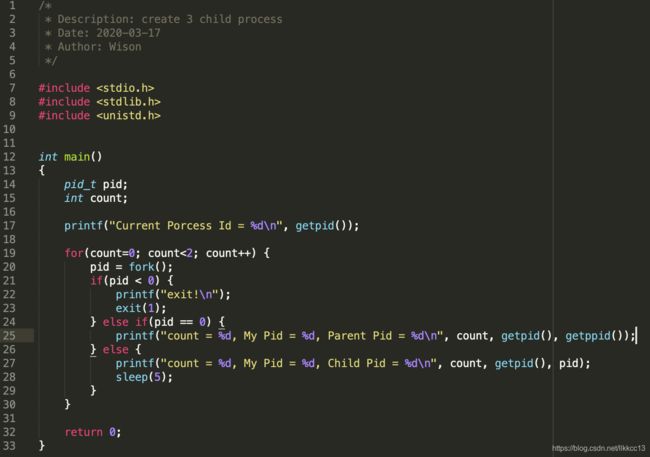
fork():由fork函数创建的新进程被称为子进程。fork函数被调用一次,但是返回两次。父进程返回的值是新进程的进程ID,而子进程返回的值是0。创建新进程成功后,系统中出现两个基本完全相同的进程,这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略
getpid():获取当前进程ID。
getppid():获取父进程ID。
例子:创建3个子进程:
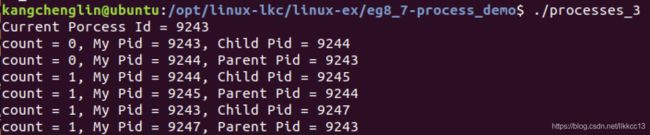

2.2.2 Linux进程的三态
。。。。。
2.2.3 进程创建(进程的实现)
(1)pid_t fork();
(2)pid_t vfork();
fork()调用执行一次返回2个值,对于父进程,fork()返回子进程的进程号,而对于子进程,fork()则返回0。
在fork()之后,子进程和父进程都会执行fork()调用之后的指令。
fork()和vfork()的区别:
fork()创建的子进程会复制父进程的数据和堆栈空间等资源,不包含task_struct和PID;而vfork()创建的子进程与父进程共享地址空间,只有当其中一进程试图修改欲复制的空间时才会做真正的复制动作,另外,vfork()的子进程先运行,运行完后并推出后父进程才运行。
2.2.4 僵尸进程
僵尸进程:已经结束但还没有从进程表中删除的进程。僵尸进程太多会导致进程表的条目满了,进而导致系统崩溃,倒是不占用系统资源。
产生原因:fork()创建一个新进程后,核心进程会在进程表中给它分配一个进入点(Entry),然后将相关信息存储在该进入点所对应的进程表中,这些信息中有一项时其父进程的识别码。子进程结束后,原来进程表中的数据会被取代为退出码、执行时间等数据,子进程已经结束但父进程尚未读取这些数据之前,子进程就会变成僵尸进程。
如何避免:
(1)处理子进程结束
父进程通过wait()和waitpit()等待子进程结束,但这会导致父进程挂起。
如果父进程很忙,可以使用signal函数为SIGCHLD安装handler处理函数,当子进程结束后就在handler中调用wait()进行回收。
(2)让系统接管
设置signal(SIGCHLD, SIG_IGN)忽略子进程的结束,由内核进行回收。
fork()两次,子进程退出后,孙进程被init接管,其中子进程的回收需要自己处理。
2.3 进程间的通信方式
2.3.1 管道(Pipe)和有名管道(Named Pipe或FIFO)
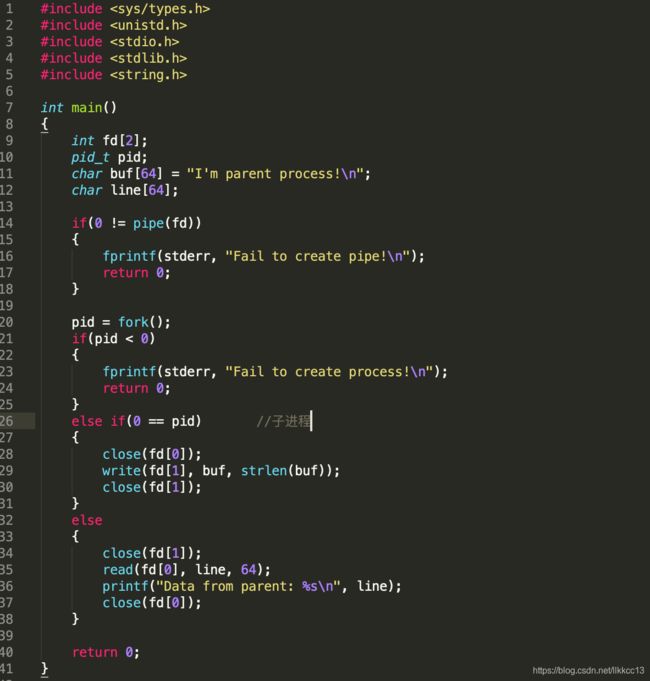
pipe管道是一种最基本的IPC机制,作用于有血缘关系的进程之间,完成数据传递。管道只能承载无格式字节流。
管道的原理: 管道实为内核使用环形队列机制,借助内核缓冲区(4k)实现。其本质是一个伪文件(实为内核缓冲区)。
例程:其中fd[0]为读端,fd[1]为写端。
2.3.2 信号(Signal)
信号:用于通知进程有某种事件发生。如果一个信号被设置为阻塞,则该信号的传递被延迟,直到其阻塞被取消时才传递给进程。
信号值小于32(SIGRTMIN)的为不可靠信号/非实时信号,例如SIGINT、SIGQUIT、SIGKILL、SIGSTOP,进程对这些信号的响应设置为默认动作。
信号值在32(SIGRTMIN)和63(SIGRTMAX)之间的为可靠信号/实时信号,支持排队,信号不会丢失。
信号的安装(处理)函数:signal() 和 sigaction()
signal()函数主要用于前32种非实时信号的安装;而
sigaction()函数有3个参数,支持信号带有参数传递信息。
2.3.3 消息队列(Message Queue)
消息队列:消息的链接表。消息队列链表由系统内核维护,每个消息队列用消息队列描述符来区分。
可以使用 ipcs -q 查看系统当前使用的消息队列。
(1)消息队列API
1.创建:msgget
int msgget(key_t key, int msgflg);
2.发送:msgsnd
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
3.接收:msgrcv
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
msgtyp = 0: 读取队列中的第一条消息。
msgtyp > 0: 读取队列中类型为msgtyp的第一条消息,除非在msgflg中指定了MSG_EXCEPT,否则将读取类型不等于msgtyp的队列中的第一条消息。
msgtyp < 0: 读取队列中最小类型小于或等于msgtyp绝对值的第一条信息。
4.删除及控制:msgctl
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
实例参考:https://www.jianshu.com/p/7598e5ed5200
2.3.4 信号量(灯)(Semaphore)
信号量主要提供对进程间共享资源访问控制机制,作为进程间以及同一进程不同线程之间的同步手段。信号灯有两种类型:二值信号灯和计算信号灯。
信号可以类比于单线铁路上火车通过的信号,用于同步通过该轨道的火车。火车在进入单一轨道之前必须等待信号灯变为允许通行的状态。火车进入轨道后,会改变信号状态(信号灯值-1,P()或sem_wait(),表示占用资源),防止其他火车进入轨道;火车离开这段轨道时,必须再次改变信号的状态(信号灯值+1,V()或sem_post(),表示释放资源),以便允许其他火车进入轨道。
详细阅读:https://docs.oracle.com/cd/E19253-01/819-7051/sync-95982/index.html
(1)信号灯API
1.文件名到健值
key_t ftok(char *pathname, char proj); 返回与路径pathname相对应的一个键值。
2.Linux特有的ipc()调用
int ipc(unsigned int call, int second, int third, void *ptr, long fifth);
参数call为SEMOP、SEMGET、SEMCTL时对应信号灯的三个系统调用:
int semop(int semid, struct sembuf *sops, unsigned nsops);
int semget(key_t key, int nsems, int semflg);
int semctl(int semid, int semnum, int cmd, union semum arg);
3.系统V信号灯API
int semget(key_t key, int nsems, int semflg); 创建和初始化信号灯,返回信号灯集描述字。
int semop(int semid, struct sembuf *sops, unsigned nsops); 完成对信号灯的P操作或V操作。
int semctl(int semid, int semnum, int cmd, union semum arg); 实现对信号灯的各种控制操作。
(2)竞争问题
竞争状态:当第一个创建信号灯的进程在初始化信号灯时,第二个进程又调用semget,并且发现信号灯已经存在,此时,第二个进程必须具有判断是否有进程正在对信号灯进行初始化的能力。
解决方法:当semget创建一个新的信号灯时,信号灯结构semid_ds的sem_otime成员初始化后的值为0。因此,第二个进程在成功调用semget后,可再次以IPC_STAT命令调用semctl,等待sem_otime变为非0值,此时可判断该信号灯已经初始化完毕。(这种解决方法时基于一个假定:第一个创建信号灯的进程必须在初始化完信号灯后调用semop,这样sem_otime才能变为非0值。)
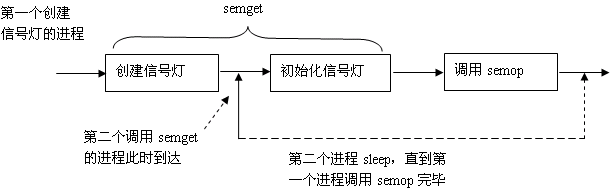
实例参考:
https://www.iteye.com/blog/kenby-1165042
https://www.ibm.com/developerworks/cn/linux/l-ipc/part4/index.html
– 以上主要指的是System V信号量。
(3)区别System V信号量和POSIX信号量
信号量有2种实现:传统的System V信号量和新的POSIX信号量。主要区别有:
① 对于所有System V信号量函数,在它们的名字里面没有下划线,而POSIX信号量函数都有一个下划线。
② 对于POSIX信号量,可以有命名的信号量(有名信号量),例如,信号量有一个文件关联它们。
System V信号量,常用于进程的同步。POSIX信号量来源于POSIX技术规范的实时扩展方案(POSIX Realtime Extension),常用于线程。
| System V信号量 | POSIX信号量 | |
|---|---|---|
| 头文件 | #include |
#include |
| API函数 | semget(), semctl(), semop() | sem_getvalue(), sem_post(), semtimewait(), sem_trywait(), sem_wait() |
| sem_init(), sem_destroy() | ||
| sem_open(), sem_close(), sem_unlink() |
使用区别:
1.System V的信号量一般用于进程同步,且是内核持续,函数为:
semget(), semctl(), semop()
2.POSIX的有名信号量一般用于进程同步,有名信号量是内核持续的,函数为:
sem_open(), sem_close(), sem_unlink()
3.POSIX的无名信号量一般用于线程同步,无名信号量是进程持续的,函数为:
sem_init(), sem_destroy()
举例:
(1)System V 二值信号量 + 共享内存:
/*
* Description: semaphore to control share resources
* (1) 使用信号灯(二值信号灯)来同步共享内存的操作
* (2) 程序创建一块共享内存,然后父子进程采用信号灯共同修改共享内存
* Date: 2019-08-31
*/
#include (2)posix信号量 + 共享内存:
/*
* Description: semaphore to control share resources
* (1) 使用信号灯(POSI有名信号量)来同步共享内存的操作
* (2) 程序创建一块共享内存,然后父子进程采用信号灯共同修改共享内存
* Date: 2019-08-31
* make: gcc posix_semaphore.c -o posix_semaphore -pthread
* (posix库不包含在Linux默认库中)
*/
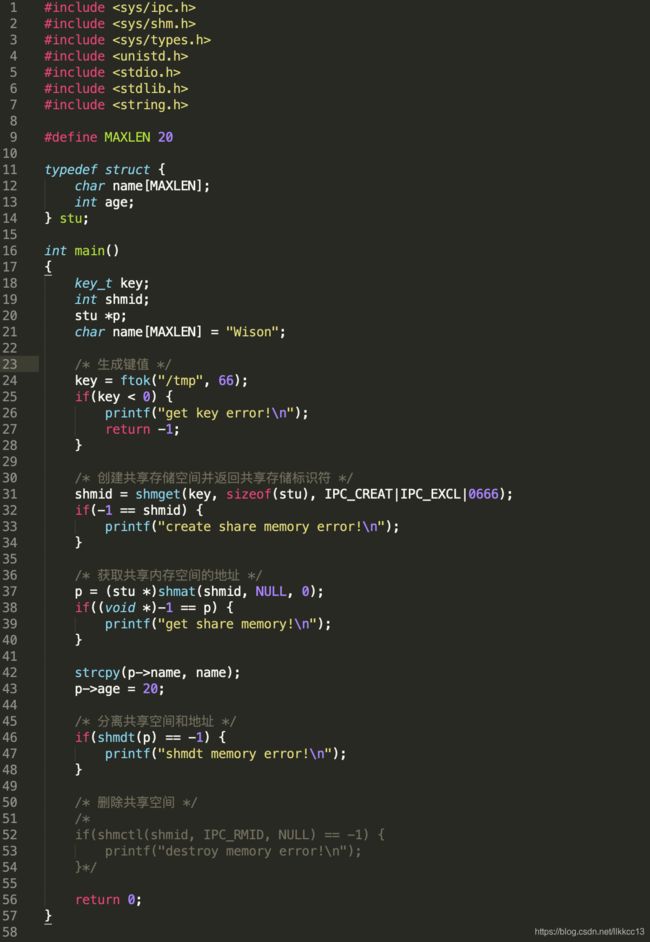
#include 2.3.5 共享内存(Shared Memory)
共享内存:多个进程共享一块内存空间,进程可以直接读写内存,效率高(进程间通信最快的方式),读写前需要某种同步机制(如互斥锁和信号量)。
参考:https://blog.csdn.net/qq_27664167/article/details/81277096
共享内存的使用流程:
① ftok函数生成键值,key_t ftok(const char *path, int id);
② shmget函数创建共享内存空间并返回共享内存标识符,int shmget(key_t key, size_t size, int flag);
③ shmat函数根据共享内存标识符获取共享内存空间的地址,void *shmat(int shmid, const void *addr, int flag);
④ shmdt函数进行分离(不是从系统中删除共享内存和结构),int shmdt(const void *addr);
⑤ shmctl函数进行删除共享存储空间,int shmctl(shmid, IPC_RMID, NULL);
示例:
(1)创建一个新的共享内存,并写入一个数据。
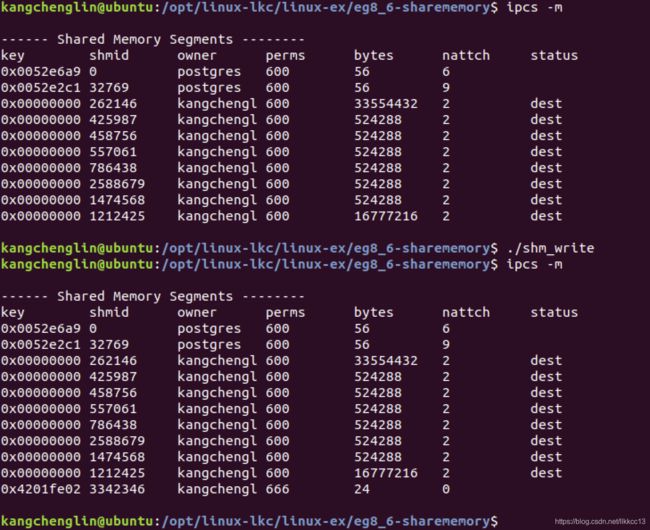
(2)创建共享内存空间(如果已经存在,则直接使用),并读取其中的数据。


2.3.6 套接字(Socket)
套接字:可用于不同机器之间的进程通信。
2.4 线程与多线程
线程:进程的一个实体,是CPU调度和分派的基本单位。
2.4.1 多线程
2.4.2 多线程的实现
pthread_create(),例如:
pthread_t thread1;
ret = pthread_create(&thread1, NULL, (void *)myThread1, NULL);
2.4.3 线程同步机制
(1)互斥锁(也称互斥量)可以用来同步同一进程中的多个线程,用于保护临界区(共享资源),以保证在任何时刻只有一个线程能够访问共享的资源。
互斥锁的操作流程:
1)定义一个全局的锁;pthread_mutext_t
2)初始化锁;pthread_mutex_init()
3)创建线程;
4)上锁、操作共享资源、解锁;pthread_mutex_unlock(), pthread_mutex_lock()
5)线程退出,释放资源(销毁锁)。pthread_mutex_destroy()
例子:

如果线程thread1或线程thread2访问g_value资源前不上锁,则这2个线程的运行会不同步,导致g_value数据计算结果不是预期的。
(2)条件锁(也称条件变量):用于在线程之间同步共享数据的值。条件变量提供一种线程间通信机制:当某个共享数据达到某个值时,唤醒等待这个共享数据的一个/多个线程。即,当某个共享变量等于某个值时,调用 signal/broadcast。此时操作共享变量时需要加锁。
主要的系统调用为:
1)初始化条件变量;pthread_cond_init()
2)唤醒一个等待目标条件变量的线程;pthread_cond_signal()
3)等待目标条件变量,需要一个加锁的互斥锁确保操作的原子性;pthread_cond_wait()
4)销毁条件变量;pthread_cond_destroy()
2.4.4 锁机制
Linux的4种锁:
(1)互斥锁:在任何时刻都只能有一个线程访问该对象。当获取锁操作失败时,线程会进入睡眠,直到锁被释放。
(2)读写锁:分为读锁和写锁。同一时刻只能有一个线程获得写锁,但处于读操作时可以允许多个线程同时获得读锁。
(3)自旋锁:在任何时刻都只能有一个线程访问该对象。但当获取锁操作失败时,会原地自旋,直到锁被释放。
(4)RCU:在修改数据时,首先需要读取数据,然后生成一个副本,对副本进行修改。修改完成后,再将老数据update成新的数据。
死锁产生的4个必要条件:
(1)互斥条件:进程对所分配到的资源不允许其他进程访问。
(2)不可剥夺条件:进程已获得的资源,在未完成使用之前,不可被剥夺,只能在使用后自己释放。
(3)请求和保持条件:进程获得一定的资源后,又对其他资源发出请求,但是该资源可能被其他进程占有,此时请求阻塞,但该进程不会释放自己已经占有的资源。
(4)环路等待条件:进程发生死锁后,必然存在一个进程 - 资源之间的环形链。
死锁消除的方法:
(1)可剥夺资源:即当进程新的资源未得到满足时,释放已占有的资源,从而破坏不可剥夺的条件。
(2)剥夺请求和保持条件:资源一次性分配。
(3)资源有序分配法:系统给每类资源赋予一个序号,每个进程按编号递增的请求资源,释放则相反,从而破坏环路等待的条件。
3. 硬件接口和协议
3.1 ARM架构
。。。。。
3.2 RAM和ROM的区别
ROM:(Read Only Memory)断电不丢失数据。只读存储器在单片机中用来存储程序数据、常量数据或变量数据。
RAM:(Rondom Access Memory)断电丢失数据。随机访问存储器用来存储程序中用到的变量。凡是整个程序中,所用到的需要被改写的量,都存储在RAM中,“被改写的量”包括全局变量、局部变量、堆栈段。
单片机运行时需要调用某个程序/函数/固定函数时就需要读取ROM,然后在RAM中执行这些程序/函数的功能,所产生的临时数据也都存在RAM中,断电后这些临时数据就丢失了。
3.3 硬件接口
3.3.1 UART
3.3.2 SPI
SPI:(Serial Peripheral Interface)是一种同步的、全双工的串行接口。
参考: https://blog.csdn.net/weiqifa0/article/details/82765892
- SCLK: 时钟信号,由主设备产生
- MOSI: 主设备输出从设备输入
- MISO: 主设备输入从设备输出
- CS: 片选信号
MOSI/MISO数据的传输是根据SCLK的时钟脉冲来一位一位传输的(普通串行通信一次传输 至少8位),数据在时钟上升沿或下降沿时改变,在紧接着的下降沿或上升沿被读取。支持数据的输出和输入同时进行,即全双工。
SCLK信号线只由主设备控制。
SPI接口的一个缺点:没有指定的流控制,没有应答机制确认是否接收到数据。
SCLK时钟的极性和相位:
- CPOL: 时钟极性选择,0:SPI总线空闲为低电平,1:SPI总线空闲为高电平。
- CPHA: 时钟相位选择,0:在SCK第一个跳变沿采样,1:在SCK第二个跳变沿采样。
3.3.3 I2C
3.3.4 USB
3.3.5 CAN
CAN总线标准之规定了物理层和数据链路层,不同的CAN标准仅物理层不同。
物理层和数据链路层:ISO11898;
应用层:不同的应用领域使用不同的应用层标准。

参考:https://zhuanlan.zhihu.com/p/32221140
CAN总线特征:
CAN总线采用差分信号传输。
当处于逻辑1,CAN_High和CAN_Low的电压差小于0.5V时,称为隐性电平(Recessive);
当处于逻辑0,CAN_High和CAN_Low的电压差大于0.9V时,称为显性电平(Dominant)。
CAN总线通信原理可简单描述为多路载波侦听+基于消息优先级的冲突检测和非破坏性的仲裁机制(CSMA/CD+AMP),CSMA(Carrie
Sense Multiple Access),CD+AMP(Collision
Detection + Arbitration on Message Priority)。
数据帧:
数据帧以一个显性位(逻辑0)开始,以7个连续的隐性位(逻辑1)结束。CAN总线的数据帧有标准格式(Standard Format)和扩展格式(Extended Format)的区分。

数据帧可以分为七段:
(1)帧起始(SOF)
标识一个数据帧的开始,固定一个显性位。

用于同步, 总线空闲期间的任何隐性到显性的跳变都将引起节点进行硬同步。只有总线在空闲期间节点才能够发送SOF。
(2)仲裁段(Arbitration Field)
仲裁段的内容主要为本数据帧的ID信息,另外还有RTR, IDE, SRR位。在CAN协议中,ID决定着数据帧发送的优先级,也决定着其他设备是否会接收这个数据帧(根据ID过滤报文)。
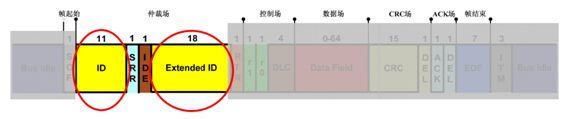
(3)控制段
最主要的是DLC(Data Length Code)段,它是用二进制编码表示本报文中的数据段包含多少个字节。

(4)数据段
数据帧的核心内容,有0-8个字节长度,由DLC确定。

(5)CRC段
CAN的报文包含了一段15位的CRC校验码,一旦接收端计算出的CRC码跟接收到的CRC码不同,就会向发送端反馈出错信息以及重新发送。
在CRC校验码之后,有一个CRC界定符(DEL),它为隐性位,主要作用是把CRC校验码与后面的ACK段隔开。

(6)ACK段
包含确认位(ACK slot)和界定符(Delimiter, DEL)。ACK在发送节点发送时,为隐性位。当接收节点正确接收到报文时,对其用显性位覆盖。DEL界定符同样为隐性位,用于隔开。
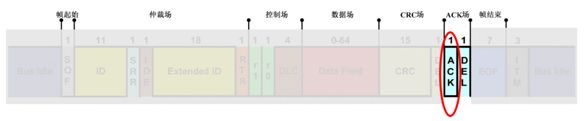
(7)帧结束段(End-of-Frame, EOF)
帧结束段由发送端发送7个隐性位表示结束。

参考(转载)来自:https://zhuanlan.zhihu.com/p/32221140
同步:
CAN总线使用位同步的方式来确保通信时序,以及对总线的电平进行正确采样。
3.3.6 RS485
3.4 无线通信方式和协议
3.4.1 WiFi协议
WiFi配网有两种方式:
(1)AP-mode
(2)smartconfig(airkiss)
WiFi是指WLAN中的802.11,是MAC层协议。
802.11.n:因为传输速率在很大的程度上取决于Channel(信道)的ChannelWidth有多宽,而802.11n中采用了一种技术,可以在传输数据的时候将两个信道合并为一个,再进行传输,极大地提高了传输速率(这又称HT-40,high through)。
在802.11中的帧有三种类型:
(1)管理帧(Management Frame,例如Beacon帧、Association帧):主要用来加入或退出无限网络,以及处理基站之间的连接转移。
(2)控制帧(Control Frame,例如RTS帧、CTS帧、ACK帧):负责区域的清空、信道的获得和载波监听的维护;与数据帧搭配使用,收到数据时给予应答。
(3)数据帧(Data Frame,承载数据的载体,其中的DS字段用来标识方向很重要):负责在工作站之间的数据传输。
参考链接:https://wenku.baidu.com/view/51b4aedbdd88d0d233d46aaa.html
管理帧:

控制帧:
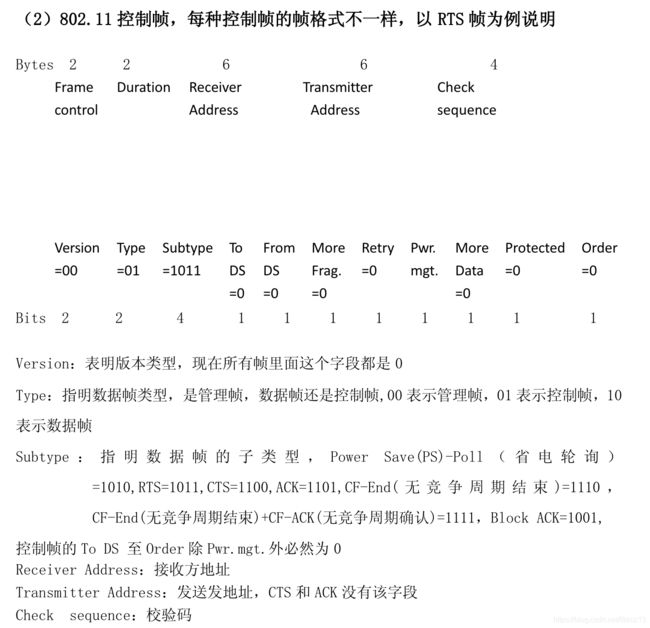
数据帧:


其他链接:
https://blog.csdn.net/leho666/article/details/89136542
https://www.jianshu.com/p/6cc4ea0dc0bc
3.4.2 BLE协议
3.4.3 ZigBee协议
ZigBee 3.0基于IEEE 802.15.4标准,2.4 GHz频段,并且使用ZigBee PRO标准网络层协议,即使最小、功耗最低的设备也能实现可靠的通信。
ZigBee稳定可靠,使用多跳网状网络消除单点故障和扩大网络覆盖范围。
ZigBee非常安全,使用各种安全机制,如AES-128加密标准,设备网络密钥以及帧计数器。
ZCL : Zigbee Cluster Library,Zigbee簇群库
ZDO : Zigbee Device Object
3.4.4 LoRa协议
LoRa:仅包含链路层协议,并且非常适用于节点间的P2P通信。
LoRaWAN:也包含网络层,因此可以将信息发送到任何已连接到云平台的基站。
几种LoRa通信方式的对比:
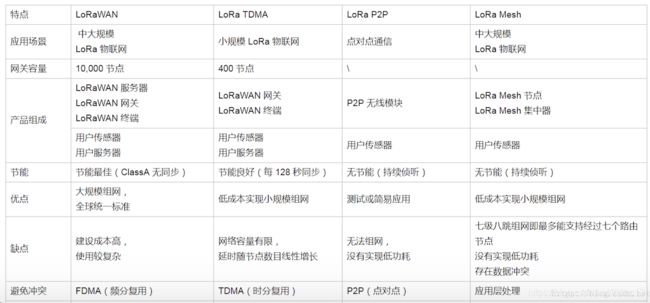
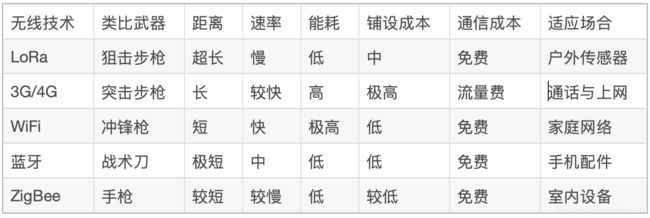
LoRa和其他无限通信方式的对比:
LoRaWAN节点的入网:
End Node要加入LoRaWAN网络,首先需要赋值和激活。一般说来,有2种方法完成入网:ABP(Activation by Personalization,个性化激活)和OTAA(Over-the-Air Activation,空中激活)。
(1)ABP是一种简单的入网机制,同时,它也不太安全,适合于建设私网。
它的核心原理是,LoRaWANServer和End Nodes双方都保存相同的3个参数:DevAddr、NwkSKey和AppSKey。
(2)OTAA是一种安全系统很高的入网机制,当然,它的代价是较复杂。
OTAA方式入网的node,在刚上电的时候,是不处于入网状态的,此时就需要进行入网操作。
如果我们简单的把服务器看做一个整体,那么入网操作的流程是这样的:
1. node 发送入网请求,即join_request message
2. GW 收到 node 的数据,上传给服务器
3. 服务器收到入网请求,同意入网,并且将设备在服务器注册,建立长地址与短地址之间的联系,生成通讯密钥,将通讯密钥的参数打包下发给GW,即 Join-accept message
4. GW 收到服务器的数据,下发给 node
5. node 根据下发的数据包,得到 DevAddr、APPSKEY、NWKSKEY
LoRaWAN协议层次:
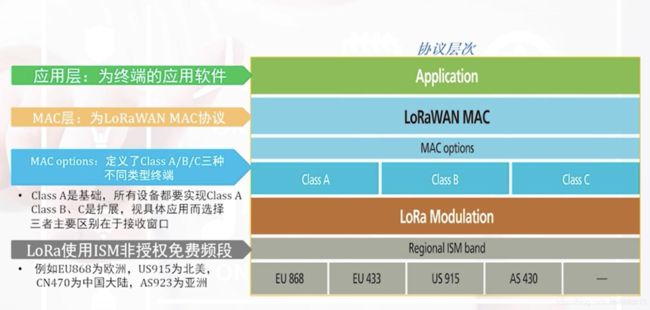
Class A: 终端在每次上行后紧跟2个短暂的下行接收窗口;
Class B: 除了Class A的接收窗口,设备还会通过网关接收时间同步的信标(Beacon)在指定时间打开接收窗口
Class C: 终端基本是一直开着接收窗口,只在发送时短暂关闭
LoRaWAN协议:
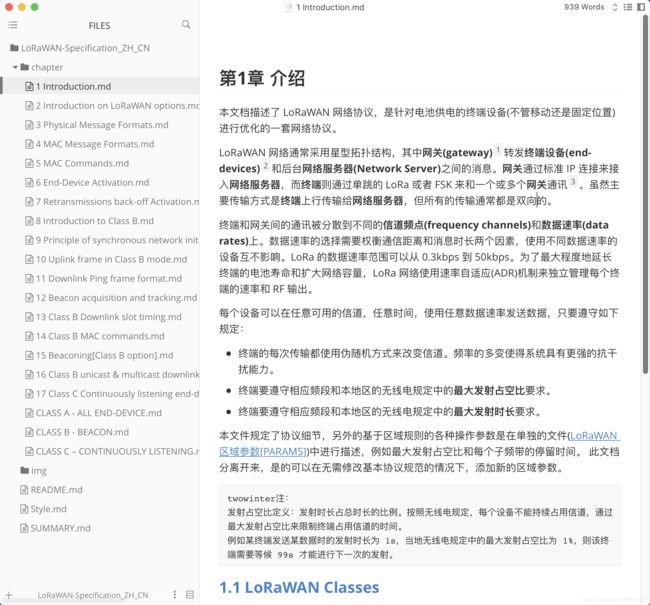
1.LoRa 的数据速率范围可以从 0.3kbps 到 50kbps。为了最大程度地延长终端的电池寿命和扩大网络容量,LoRa 网络使用速率自适应(ADR)机制来独立管理每个终端的速率和 RF 输出。
2.PHY帧格式

3.MAC帧格式

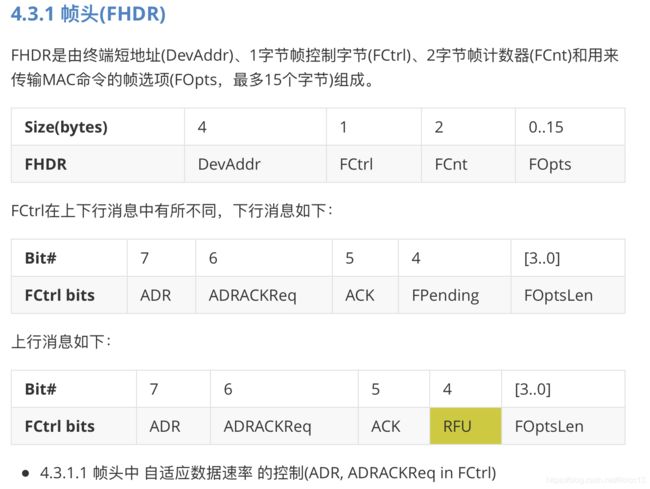
4.MAC指令
3.4.5 NB-IoT
NB模组:移远BC-26、芯讯通SIM7020、龙尚A9600R2
物联网设备管理平台:OceanConnect、中移物联
3.5 网络通信协议
3.5.1 TCP
参考链接:https://developer.51cto.com/art/201906/597961.htm
下图为TCP/IP协议模型的数据组成结构。
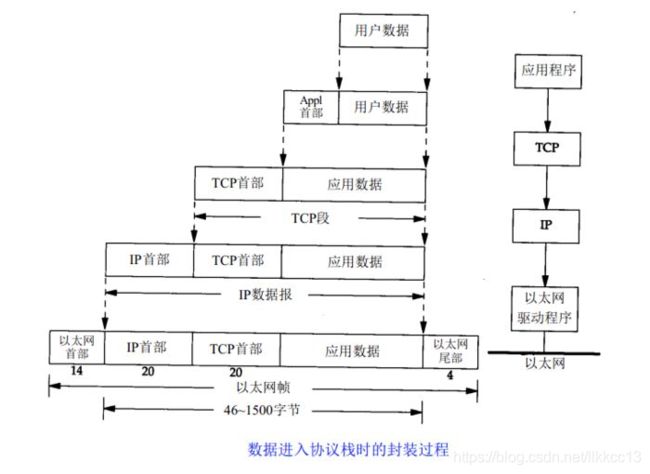
TCP:是面向连接的、可靠的流协议。TCP通过序列号、检验和、确认应答、重发控制等提供可靠性传输。TCP处于OSI 参考模型的第4层 - 传输层。
TCP报文格式:
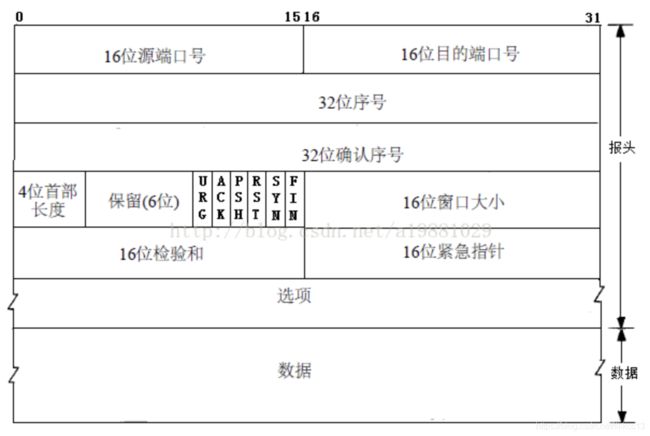
TCP的3次握手和4次挥手:


Linux socket的TCP连接:
Server:
Client:
3.5.1 IP
IP(IPV4、IPV6)协议处于 OSI 参考模型中的第3层 - 网络层(主要是实现终端节点之间的通信,可以跨越不同的数据链路)。
IP 大致分为三大作用模块,它们是 IP 寻址、路由(最终节点为止的转发)以及 IP 分包与组包。
IP报文格式:

IP地址分类:
- A类IP地址(首位为0): 0.0.0.0 ~ 127.255.255.255
- B类IP地址(首位为10): 128.0.0.0 ~ 191.255.255.255
- C类IP地址(首位为110): 192.0.0.0 ~ 223.255.255.255
- D类IP地址(首位为1110): 224.0.0.0 ~ 239.255.255.255
与IP相关的其他协议:
- ARP及RARP协议
ARP是一种地址解析协议,根据IP地址获取MAC地址。
RARP是将ARP反过来,从MAC地址定位IP地址的一种协议。 - ICMP协议
ICMP是网络控制报文协议。当传送IP数据包发生错误,比如主机不可达、路由不可达等,ICMP协议将会把错误信息封包,然后传送回给主机。
ping是ICMP的最著名的应用,利用ICMP协议包来侦测另一个主机是否可达。原理是用类型码为0的ICMP发请求,受到请求的主机则用类型码为8的ICMP回应。 - DNS协议
DNS(Domain Name System),用来将域名转换为IP地址(也可以将IP地址转换为相应的域名地址)。 - DHCP协议
DHCP(Dynamic Host Configuration Protocol),动态主机配置协议,是运行在UDP协议之上。DHCP通常被用于局域网环境,主要作用是集中的管理、分配IP地址。 - NAT协议
NAT(Network Address Translator),在私有地址和全局地址之间转换的协议。
3.5.3 UDP
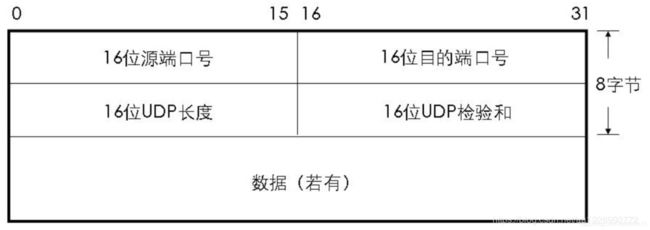
UDP(User Datagram Protocol),用户数据报协议,是处于OSI模型的第4层 - 传输层。
UDP是无连接的、不保证可靠的、面向报文的。
UDP报文格式:
3.5.4 HTTP
3.5.5 HTTPS
3.5.6 CoAP
CoAP:受限制的应用协议(Constrained Application Protocol),是一种基于消息请求/响应模型的应用协议。CoAP是基于UDP的第7层应用层协议。
1. CoAP协议的报文组成:

(1)Ver: 版本编号。
(2)T: 报文类型(CON、NON、ACK、RST)。
(3)TKL: CoAP标识符长度。一种标识符是Message ID(报文编号),一种标识符是Token(标识符)。
(4)Code: 功能码/响应码。
(5)Message ID:
参考:https://www.jianshu.com/p/7fec0916a0d3
CoAP的DTLS介绍:
3.5.7 MQTT
MQTT:消息队列遥测传输协议(Message Queuing Telemetry Transport),是一种基于发布/订阅模式的“轻量级”通讯协议。MQTT是基于TCP协议的第7层应用层协议。
MQTT的数据包组成:固定头 + 可变头(部分MQTT数据包存在) + 消息体(部分MQTT数据包存在)

1. MQTT固定头

(1)MQTT数据包类型

(2)标识位

QoS(服务质量):
0: 至多一次,不确保消息到达,可能会丢失或重复。
1: 至少一次,确保消息到达,但可能会重复。
2: 只有一次,确保消息到达,并只有一次。
(3)剩余长度
用来保存可变头和Payload消息体的总大小,bits 0 ~ 6。bit 7为1时,表示长度不够,将使用2个Bytes来保存长度。
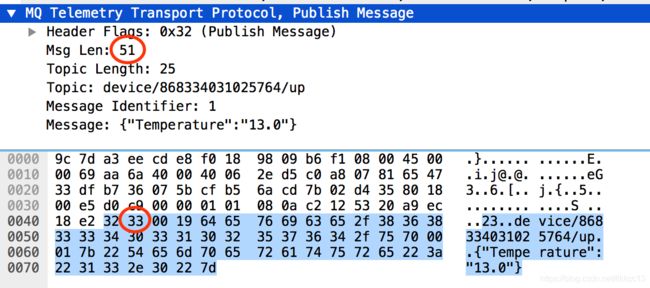
2. MQTT可变头

另外:很多控制报文的可变报头部分包含一个2字节的报文标识符(数据包标识Packet Identifier),用来识别一个唯一的数据包。这些报文是PUBLISH(QoS > 0时),PUBACK,PUBREC,PUBREL,PUBCOMP,SUBSCRIBE, SUBACK,UNSUBSCRIBE,UNSUBACK。
例如,PUBLISH的数据包标识:数据包标识只需要保证在从 Sender 到 Receiver 的一次消息交互(比如发送、应答为一次交互)中保持唯一就好,只在QoS大于1的消息中使用,因为QoS大于1的消息有应答流程。
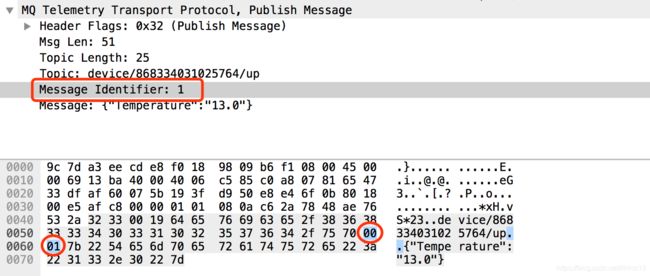
报文标识符的规定参考:https://mcxiaoke.gitbooks.io/mqtt-cn/content/mqtt/02-ControlPacketFormat.html
3. Payload消息体

参考:
https://www.jianshu.com/p/5c42cb0ed1e9
MQTT的TLS的介绍:
3.5.8 MQTT和TCP的区别
(1)协议位置
TCP是OSI模型的第四层传输层协议;MQTT是基于TCP的第七层应用层协议。
(2)协议定位
TCP是面向连接的、可靠的、基于字节流的传输层通信协议;MQTT则是在旨在低带宽、高延迟、不可靠的网络下相对可靠传输数据的应用层协议。
(3)设计思想
TCP的核心思想是分组交换;MQTT的核心思想是简单并适应物联网环境。
(4)传输单位
TCP的传输单位是packet,当应用层发送字节流,TCP将其分割成合适的报文段,最大传输段(MSS)受最大传送单元(MTU)限制;MQTT的传输单元是消息,在MQTT Broker代理服务器中可以设置超过1M大小的消息上限。
(5)服务质量
TCP是一个可靠的流传输服务,通过ACK确认和重传机制;MQTT的QoS服务质量有3种,MQTT客户端和MQTT Broker之间通过session机制保证消息的传输可靠性。
参考:
https://www.zhihu.com/question/23373904
3.5.9 OpenSSL加密
3.5.9 RTSP
4. 数据结构
程序设计 = 数据结构 + 算法
数据结构:是相互之间存在一种或多种特定关系的数据元素的集合。
算法:描述解决问题的方法。
算法的特性:有穷性、确定性、可行性、输入、输出;算法设计的要求:正确性、可读性、健壮性、高效率和低存储。
算法时间复杂度(大O阶)推导方法:
- 用常数1取代运行时间中的所有加法常数;
- 在修改后的运行次数函数中,只保留最高阶项;
- 如果最高阶项存在且不是1,则去除与这个项相乘的常数。
4.1 线性表
4.1.1 线性表的顺序结构
线性表(list):零个或多个数据元素的有限序列。
线性表的顺序存储结构优缺点:
优点:(1)无须为表示表中元素之间的逻辑关系而增加额外的存储空间;(2)可以快速地存取表中任一位置的元素。
缺点:(1)插入和删除操作需要移动大量元素;(2)当线性表长度变化较大时,难以确定存储空间的容量;(3)造成存储空间的“碎片”。
(1)线性表的顺序存储结构:
typedef struct
{
int data[MAXSIZE];
int length;
}SqList;
(2)添加和删除元素:
/*
* 线性表中插入一个元素
* 时间复杂度为O(n)
*/
int ListInsert(SqList *L, int i, ElemType e)
{
int k;
if (L->length == MAXSIZE)
return ERROR;
if (i < 1 || i > L->length + 1)
return ERROR;
if (i <= L->length)
{
for (k = L->length - 1; k > i-1; k--)
L->data[k+1] = L->data[k];
}
L->data[i - 1] = e;
L->length++;
return OK;
}
/*
* 线性表中删除一个元素
* 时间复杂度为O(n)
*/
int ListDelete(SqList *L, int i, ElemType *e)
{
int k;
if (L->length == 0)
return ERROR;
if (i < 1 || i > L->length)
return ERROR;
*e = L->data[i - 1];
if (i < L->length)
{
for (k = i; k < L->length; k++)
L->data[k - 1] = L->data[k];
}
L->length--;
return OK;
}
4.1.2 线性表的链式结构
(1)线性表的链式存储结构:数据域 + 指针域
typedef struct Node
{
int data;
struct Node *next;
}Node;
typedef struct Node *LinkList;
(2)初始化链表
int InitList(LinkList *L) {
*L = (LinkList)malloc(sizeof(Node)); // 产生头结点,并使L指向此头结点
if(!(*L))
return ERROR;
(*L)->next = NULL; // 头结点的指针域为空
return OK;
}
头结点:
为了更方便地对链表进行操作,会在单链表的第一个结点前附设一个结点(头结点)。头结点的数据域可以不存储任何信息,也可以存储如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针。
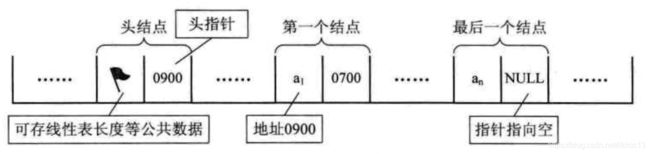
有了头结点,对在第一元素结点前插入结点和删除第一结点,其操作与其他结点的操作就统一了。头结点不一定是链表必须要素。
(3)添加和删除元素:
/*
* 链表中插入一个元素
*/
int ListInsert(LinkList *L, int i, ElemType e)
{
LinkList p, s;
int j;
p = *L;
j = 1;
while (p && j < i)
{
p = p->next;
j++;
}
if (!p || j > i)
return ERROR;
s = (LinkList)malloc(sizeof(Node)); // 产生新的结点
s->data = e;
s->next = p->next;
p->next = s;
return OK;
}
/*
* 链表中删除一个元素
*/
int ListDelete(LinkList *L, int i, ElemType *e)
{
LinkList p, q;
int j;
p = *L;
j = 1;
while (p->next && j < i)
{
p = p->next;
j++;
}
if (!(p->next) || j > i)
return ERROR;
q = p->next;
p->next = q->next;
*e = q->data;
free(q);
return OK;
}
4.2 栈(stack)
栈是限定仅在表尾(栈顶)进行插入和删除操作的线性表。
4.2.1 栈的顺序结构
(1)顺序结构的栈:
typedef int SElemType;
typedef struct {
SElemType data[MAXSIZE];
int top;
} SqStack;
(2)压栈和出栈:
/*
* 从栈顶中插入一个元素
*/
int Push(SqStack *S, SElemType e)
{
if(S->top == MAXSIZE - 1)
return ERROR;
S->top++;
S->data[S->top] = e;
return OK;
}
/*
* 删除栈顶的元素
*/
int Pop(SqStack *S, SElemType *e)
{
if(S->top == -1)
return ERROR;
*e = S->data[S->top];
S->top--;
return OK;
}
4.2.2 两栈共享空间
(1)两栈共享空间结构
typedef struct {
SElemType data[MAXSIZE];
int top1;
int top2;
} SqDoubleStack;
(2)压栈和出栈
/*
* 向栈1或栈2中插入一个元素
*/
int Push(SqDoubleStack *S, SElemType e, int stackNumber)
{
if(S->top1+1 == S->top2) // 栈满
return ERROR;
if(stackNumber == 1) // 栈1
S->data[++S->top1] = e;
else if(stackNumber == 2) // 栈2
S->data[--S->top2] = e;
return OK;
}
/*
*
*/
int Pop(SqDoubleStack *S, SElemType *e, int stackNumber)
{
if(stackNumber == 1) {
if(S->top1 == -1)
return ERROR;
*e = S->data[S->top1--];
}
else if(stackNumber == 2) {
if(S->top2 == MAXSIZE)
return ERROR;
*e = S->data[S->top2++];
}
return OK;
}
4.2.3 栈的链式结构
【易混淆点】通常,对于链式栈来说,是不需要头结点的。
(1)链式结构栈:
typedef int SElemType;
typedef struct StackNode {
SElemType data;
struct StackNode *next;
} StackNode, *LinkStackPtr;
typedef struct {
LinkStackPtr top;
int count;
} LinkStack;
(2)压栈和出栈:
/*
* 从栈顶中插入一个元素
*/
int Push(LinkStack *S, SElemType e)
{
LinkStactPtr s = (LinkStackPtr)malloc(sizeof(StackNode));
s->data = e;
s->next = S->top;
S->top = s;
S->count++;
return OK;
}
/*
* 删除栈顶的元素
*/
int Pop(LinkStack *S, SElemType *e)
{
LinkStackPtr q;
if(S->count == 0)
return ERROR;
*e = S->top->data;
q = S->top;
S->top = q->next;
free(q);
S->count--;
return OK;
}
4.3 队列(queue)
队列是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。队列是一种先进先出(FIFO)的线性表。
4.3.1 顺序队列
顺序队列:头尾相接的顺序存储结构的队列。
(1)循环队列的顺序存储结构:
typedef int QElemType;
typedef struct {
QElemType data[MAXSIZE];
int front; // 头指针
int rear; // 尾指针
} SqQueue;
(2)入队和出队:
/*
* 若队列未满,则插入元素e为队列的新的队尾元素
*/
int EnQueue(SqQueue *Q, QElemType e)
{
if((Q->rear + 1) % MAXSIZE == Q->front)
return ERROR;
Q->data = e;
Q->rear = (Q->rear + 1) % MAXSIZE;
return OK;
}
/*
* 若队列不空,则删队列中队头的元素
*/
int DeQueue(SqQueue *Q, QElemType *e)
{
if(Q->rear == Q->front)
return ERROR;
*e = Q->data;
Q->front = (Q->front + 1) % MAXSIZE;
return OK;
}
(3)循环队列的长度:
int QueueLength(SqQueue Q)
{
return (Q.rear - Q.front + MAXSIZE) % MAXSIZE;
}
4.3.2 链式队列
链式队列,是特殊的线性单链表,只能尾进头出的单链表。
【易混淆点】通常,对于链式队列来说,为了操作上的方便,会将队头指针指向链式队列的头结点。
(1)链式队列的结构:
typedef int QElemType;
typedef struct QNode {
QElemType data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct {
QueuePtr front, rear;
} LinkQueue;
(2)入队和出队:
/*
* 在队尾插入一个元素
*/
int EnQueue(LinkQueue *Q, QElemType e)
{
QueuePtr s = (QueuePtr)malloc(sizeof(QNode));
if(!s)
exit(OVERFLOW);
s->data = e;
s->next = NULL; // 队尾指向空指针
Q->rear->next = s;
Q->rear = s;
return OK;
}
/*
* 删除队头的一个元素(队列不为空)
*/
int DeQueue(LinkQueue *Q, QElemType *e)
{
QueuePtr q;
if(Q->front == Q->rear)
return ERROR;
q = Q->front->next;
*e = q->data;
Q->front->next = q->next;
if(Q->rear == q)
Q->rear = Q->front;
free(q);
return OK;
}
4.4 字符串(string)
4.4.1 KMP模式匹配算法
KMP模式匹配算法的关键在于:主串S、子串T,若T中后部分中存在与前m个字符(m不是固定值)重复的字符,则将重复个数+1(重复个数其实是前m个字符的位置)记录在next数组中。当T后部分在和S在比较不匹配时,则让T的指针跳到前m个字符的位置,继续从T中与S部分匹配的位置开始继续比较(虽然T最后几个字符和S中的不匹配,但T前面部分k个字符(k < T最后部分不匹配时的指针位置,k可能等于m)可能会存在与S当前指针前k个相同,其中k为next数组中T中重复字段的情况)。
next数组中的值计算时,后部分总是与前m个字符进行比较,以计算重复情况。
改良后的KMP模式匹配算法:
改良后,next数组变化了:“若T中后部分中存在与前m个字符(m不是固定值)重复的字符,则将重复个数+1(重复个数其实是前m个字符的位置)记录在next数组中”。改良的关键是:从T中后部分与第前m+1位不相同的那一位开始,把T中后部分与前m+1位值相同的位所对应的next数组值降低,以减少已匹配过但也不相同的重复情况。
举例:改变next[6]前面3个值,其他情况类似。

书中的描述:

4.5 树(tree)
二叉树
遍历
5. 算法
5.1 冒泡排序和选择排序
(1)冒泡排序
时间复杂度:O(n^2)
冒泡排序的原理是:每相邻的2个数比较,把大的放在两者中的后面,每一轮的循环就会把一个当前最大的数排在当前的最后(即重的沉下去)。
#include (2)选择排序
时间复杂度:O(n^2)
它的工作原理是:第 i 个与第 i+1 ~ N-1个来比较,把最小的数放在第 i 位,如此循环知道倒数第2个。
选择排序是不稳定的排序方法(比如序列[5, 5, 3]第一次就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)
#include 5.2 查找特定数据
(1)一个整型数组中有且仅有一个数字出现1次,其他都出现2次,找出只出现一次的数字。(*顶科技面试)
#include (2)100 ~ 999的3位数整型数组中,查找符合以下条件的数据:3位数中有2位的数字相同,且3位数为某个数的平方,如144。(*为嵌入式C面试)
5.3 牛客网题目
5.3.1 数据结构
(1)链表从尾到头打印所有元素
C语言:
/* 从尾到头输出列表的元素 */
int LinkListPrintFromTailToHead(LinkList L)
{
LinkList p;
int buff[1024];
int i = 0, j;
p = L->next;
while(p) {
buff[i++] = p->data;
p = p->next;
}
for(j=i-1; j>=0; j--) {
printf("%d ", buff[j]);
}
printf("\n");
return OK;
}
C++:
class Solution {
public:
vector<int> printListFromTailToHead(ListNode* head) {
vector<int> result;
stack<int> arr;
int len;
ListNode *p = head;
while(p != NULL) {
arr.push(p->val);
p = p->next;
}
len = arr.size();
for(int i=0; i<len; i++) {
result.push_back(arr.top());
arr.pop();
}
return result;
}
};
(2)使用2个栈实现队列
class Solution
{
public:
void push(int node) {
stack1.push(node); // 栈1保存新压栈的那一部分数据
}
int pop() {
int result;
if(stack2.empty()) {
while(!stack1.empty()) {
stack2.push(stack1.top()); // 栈2为空的时候剪切栈1中当前所有数据
stack1.pop();
}
}
result = stack2.top(); // 栈2的栈顶元素即为队列的队头元素
stack2.pop();
return result;
}
private:
stack<int> stack1;
stack<int> stack2;
};
5.4 C语言的经典问题
5.4.1 汉诺塔问题
https://www.zhihu.com/question/24385418
#include 其他一些常见问题:
1.字节对齐
2.如何比较2个结构体是否相等,是否可以用memcmp来比较
3.符合判断2个float类型数据是否相等
4. 野指针
野指针不是NULL指针,是指向“垃圾”内存的指针。野指针的成因:
(1)指针变量没有被初始化。任何指针变量刚被创建时不会自动成为NULL指针,它的默认值是随机的,它会乱指一气。
(2)指针p被free或者delete之后,没有置为NULL,让人误以为p是个合法的指针。free或delete指针p后,只是把指针所指的内存给释放调,但并没有把指针本身干掉(p的地址仍然不变)。
5.怎样定位栈溢出
阅读书籍:
《高质量嵌入式Linux编程》
《大话数据结构》