【HIVE】UDAF之截尾均值
一、背景
最近在做分析时,一旦数据含有极端值,均值常常失效,对此,试图通过截尾均值解决此问题。
于是提出:在hive中新建一个UDAF(聚类函数),计算一组数值的截尾均值。
二、方案
参考percentile()函数MR计算逻辑,通过截尾比例计算出有效数据区间,对有效数据区间求均值。
三、实现
1.函数源码:UDAFTrimAvg.java
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Set;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.hive.serde2.io.DoubleWritable;
import org.apache.hadoop.hive.shims.ShimLoader;
import org.apache.hadoop.io.LongWritable;
@Description(name = "trim_avg",
value = "_FUNC_(expr, pct) - Returns the trimmed mean of expr, expr should be integer, pc should be double (range: (0, 0.5)).")
public class UDAFTrimAvg extends UDAF {
private static final Comparator COMPARATOR;
static {
COMPARATOR = ShimLoader.getHadoopShims().getLongComparator();
}
// 定义state类,收集中间聚合结果
public static class State {
private Map counts; // key计数
private DoubleWritable pct; //单边截尾比例
}
// 重写compare方法, 比较两个key的大小
public static class MyComparator implements Comparator> {
@Override
public int compare(Map.Entry o1,
Map.Entry o2) {
return COMPARATOR.compare(o1.getKey(), o2.getKey());
}
}
// 定义计数器,以o为key,i为步长递增(相当于将数据去重压缩)
private static void increment(State s, LongWritable o, long i) {
if (s.counts == null) {
s.counts = new HashMap();
}
LongWritable count = s.counts.get(o);
if (count == null) {
// We have to create a new object, because the object o belongs
// to the code that creates it and may get its value changed.
LongWritable key = new LongWritable();
key.set(o.get());
s.counts.put(key, new LongWritable(i));
} else {
count.set(count.get() + i);
}
}
// 定义截尾均值计算方法,list为按key大小排序后的列表,[lower, higher]则定义了截尾后的有效统计区范围
private static double getTrimAvg(List> entriesList,
long lower, long higher) {
long sum = 0; //有效统计区和
long start = 0; //key开始位置
for (int i = 0; i < entriesList.size(); i++) {
long cumcount = entriesList.get(i).getValue().get(); //累计频次
long key = entriesList.get(i).getKey().get(); //当前key
long count = cumcount - start; //当前key频次
if (cumcount >= lower && start <= higher) { //有效统计区
if (lower > start) { // 临界端需做特殊判断
sum += (cumcount - lower) * key;
} else if (cumcount > higher) {
sum += (higher - start) * key;
} else {
sum += count * key;
}
}
start += count;
}
return sum * 1.0 / (higher - lower);
}
// 实现UDAFEvaluator类(正餐)
public static class TrimAvgEvaluator implements UDAFEvaluator {
private final State state;
public TrimAvgEvaluator() {
state = new State();
}
// 初始化计算函数,并重设内部状态
public void init() {
if (state.counts != null) {
// We reuse the same hashmap to reduce new object allocation.
// This means counts can be empty when there is no input data.
state.counts.clear();
}
}
// map端,聚集过程,迭代传入单值,统计该key出现的次数,同时更新state
public boolean iterate(LongWritable o, Double percentile) {
if (o == null && percentile == null) {
return false;
}
if (state.pct == null) {
if (percentile < 0.0 || percentile >= 0.5) {
throw new RuntimeException("Percentile value must be within the range of 0 to 0.5.");
}
state.pct = new DoubleWritable();
state.pct.set(percentile);
}
if (o != null) {
increment(state, o, 1);
}
return true;
}
// map端,以一种可持久化的方法返回当前聚计结果
public State terminatePartial() {
return state;
}
// reduce端,将terminatePartial返回的中间部分聚合结果合并到当前聚合中
public boolean merge(State other) {
if (other == null || other.counts == null || other.pct == null) {
return false;
}
if (state.pct == null) {
state.pct = new DoubleWritable(other.pct.get());
}
for (Map.Entry e: other.counts.entrySet()) {
increment(state, e.getKey(), e.getValue().get());
}
return true;
}
// 定义返回值
private DoubleWritable result;
// reduce端,对最终聚集结果进行计算,返回实例变量result,即最终结果
public DoubleWritable terminate() {
// No input data.
if (state.counts == null || state.counts.size() == 0) {
return null;
}
// Get all items into an array and sort them.
Set> entries = state.counts.entrySet();
List> entriesList =
new ArrayList>(entries);
Collections.sort(entriesList, new MyComparator()); //对key排序
// 计算key累计频次
long total = 0;
for (int i = 0; i < entriesList.size(); i++) {
LongWritable count = entriesList.get(i).getValue();
total += count.get();
count.set(total); //累积频次
}
// 实例化result
if (result == null) {
result = new DoubleWritable();
}
// 计算截尾均值
long lower = (long) Math.floor(state.pct.get() * total); //lower = floor(单侧截尾比例 * key总数)
long higher = total - lower; // 为了保持两端截掉相同数量,higher = key总数 - lower
result.set(getTrimAvg(entriesList, lower, higher));
return result;
}
}
} 2.编译UDAFTrimAvg.java,生成.class
3.将UDAFTrimAvg*.class,打包成UDAFTrimAvg.jar
4.进入hive cli中,add UDAFTrimAvg.jar
5.创建函数trim_avg
四、应用
1.hive sql
select
trim_avg(cast(col*10 as int), 0.1)/10 as res --需将原始数据转换为整形,类似percentile()函数的使用
from (
select 0.0 as col
union all select 0.2 as col
union all select 0.2 as col
union all select 0.3 as col
union all select 0.3 as col
union all select 0.3 as col
union all select 0.3 as col
union all select 0.3 as col
union all select 0.3 as col
union all select 0.3 as col
union all select 1.0 as col
) as a2.数据流
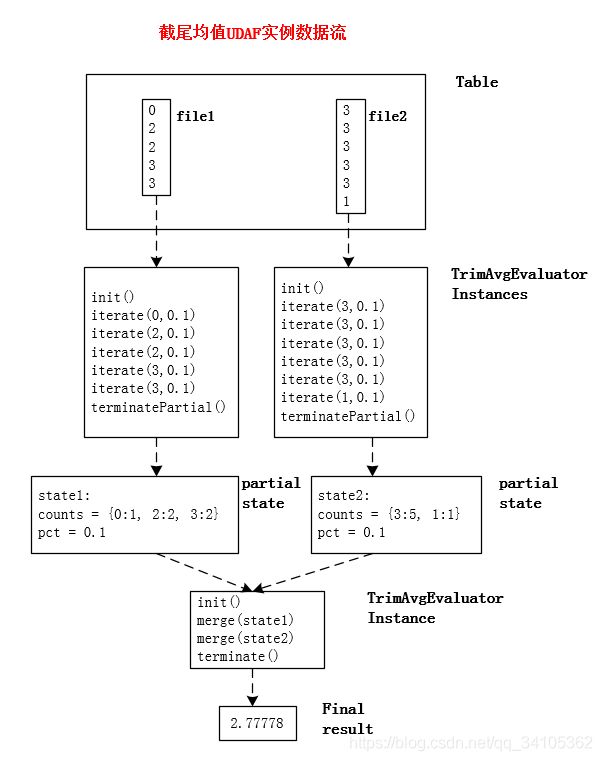
五、问题与总结
1.为了应对大的数据量,会限制传入函数的数据列为离散的整数,这样会损失一定的精度;
2.getTrimAvg()方法中,对临界值的取舍细节需要优化;
[参考]
1.《Hadoop权威指南》第12章,用户自定义函数
2.《Hive编程指南》第13章,函数
3.Hive源码