做语音识别这块的呢,国内领先的有科大讯飞,BAT这几家公司,鉴于使用科大讯飞的接口需要付费,腾讯云的语音识别申请了几天也没给通过,比较了一下阿里和百度的,个人觉得阿里云的好用一些,这篇博客来讲讲怎么讲阿里云的语音识别应用到项目中。
首先是一些链接
阿里云语音识别官网:https://help.aliyun.com/document_detail/30416.html
语音识别demo下载:http://download.taobaocdn.com/freedom/33762/compress/RealtimeDemo.zip?spm=a2c4g.11186623.2.6.5F8mxh&file=RealtimeDemo.zip
语音识别(ASR)使用手册:http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/pdf/IntelligentSpeechInteraction-intro_asr-cn-zh-2016-12-23.pdf?spm=a2c4g.11186623.2.3.gMkFE3&file=IntelligentSpeechInteraction-intro_asr-cn-zh-2016-12-23.pdf
项目中的应用
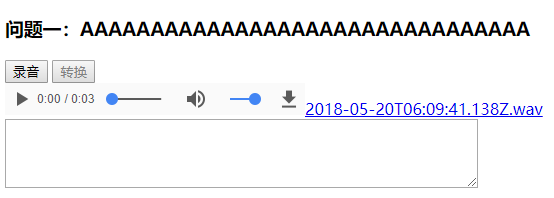
要实现的功能:前端浏览器录取用户说话的录音,然后转换为文字显示在浏览器。例如回答问题后,回答的答案显示在下方

流程分析:实现这个功能流程很简单就是浏览器收集到用户的语音输入流后,发送给后台,后台继续将数据发送到阿里云的服务器端,进行语音转文字,完成后将返回的结果进行处理,再返回到前台。
本例中主要分为两个模块,(1)前台获得麦克风的权限进行录音;(2)录制完成将数据发送到后台进行语音转文字的处理。
(1)前台录音
前台的功能是,点击录音,获取浏览器麦克风权限后,开始录音。点击转换按钮,停止录音,将数据发送到后台进行转换,转换后的结果显示在下方的文本域中,同时出现audio元素标签和文件下载链接,可回放录音和保存文件到本地。
录音相关的js文件来源其他大神,本人将其代码进行部分修改以满足需求。
JSP页面的代码
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>
<%
String path = request.getContextPath();
String basePath = request.getScheme() + "://" + request.getServerName() + ":" + request.getServerPort() + path + "/";
%>
DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<title>Insert title heretitle>
head>
<body>
<form id="questions">
<div><h1>回答问题h1>div>
<input type="hidden" name="records[0].question" value="AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA">
<div><h3>问题一:AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAh3>div>
<div>
<button onclick="startRecording(this)" >录音button>
<button onclick="uploadAudio(this,1)" disabled>转换button>
<div id="recordingslist1">div>
div>
<textarea id="audioText1" name="records[0].answer" rows="3" cols="50" style="font-size:18px">textarea>
<input type="hidden" name="records[1].question" value="BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB">
<div><h3>问题二:BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBh3>div>
<div>
<button onclick="startRecording(this)" >录音button>
<button onclick="uploadAudio(this,2)" disabled>转换button>
<div id="recordingslist2">div>
div>
<textarea id="audioText2" name="records[1].answer" rows="3" cols="50" style="font-size:18px">textarea>
<input type="hidden" name="records[2].question" value="CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCC">
<div><h3>问题三:CCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCCh3>div>
<div>
<button onclick="startRecording(this)" >录音button>
<button onclick="uploadAudio(this,3)" disabled>转换button>
<div id="recordingslist3">div>
div>
<textarea id="audioText3" name="records[2].answer" rows="3" cols="50" style="font-size:18px">textarea>
<br>
<input type="button" onclick="save()" value="保存录音"/>
form>
<a href="<%=path %>/audio/getAllRecord">查看记录详情a>
<form action="<%=path %>/audio/getaudio" method="post" enctype="multipart/form-data">
<h2>文件上传h2>
文件:<input type="file" name="audioData"/><br/><br/>
<input type="submit" value="上传"/>
form>
<script type="text/javascript" src="resources/js/HZRecorder.js">script>
<script type="text/javascript" src="resources/js/jquery-1.11.1.js">script>
<script>
function save() {
$.ajax({
type: "POST",
dataType: "json",
url: "<%=path %>/audio/saveRecord",
data: $('#questions').serialize(),
success: function (result) {
if (result) {
alert("添加成功");
}else {
alert("添加失败");
}
},
error : function() {
alert("异常!");
}
});
}
var recorder;
var audio = document.querySelector('audio');
// 开始录音
function startRecording(button) {
button.disabled = true;
button.nextElementSibling.disabled = false;
HZRecorder.get(function (rec) {
recorder = rec;
recorder.start();
});
}
// 播放录音
function playRecording() {
recorder.play(audio);
}
// 转换录音
function uploadAudio(button,num) {
button.disabled = true;
button.previousElementSibling.disabled = false;
recorder.stop();
recorder.upload("<%=path %>/audio/getaudio", num);
createDownloadLink(num);
}
// 创建下载链接
function createDownloadLink(num) {
var blob = recorder.getBlob();
var url = URL.createObjectURL(blob);
var div = document.createElement('div');
var au = document.createElement('audio');
var hf = document.createElement('a');
var record = "recordingslist"+num;
au.controls = true;
au.src = url;
hf.href = url;
hf.download = new Date().toISOString() + '.wav';
hf.innerHTML = hf.download;
div.appendChild(au);
div.appendChild(hf);
document.getElementById(record).appendChild(div);
}
script>
body>
html>
引用的js文件 HZRecorder.js
(function (window) {
//兼容
window.URL = window.URL || window.webkitURL;
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia;
var HZRecorder = function (stream, config) {
config = config || {};
config.sampleBits = config.sampleBits || 16; //采样数位 8, 16
config.sampleRate = config.sampleRate || (16000); //采样率(1/6 44100)
var context = new (window.webkitAudioContext || window.AudioContext)();
var audioInput = context.createMediaStreamSource(stream);
var createScript = context.createScriptProcessor || context.createJavaScriptNode;
var recorder = createScript.apply(context, [4096, 1, 1]);
var audioData = {
size: 0 //录音文件长度
, buffer: [] //录音缓存
, inputSampleRate: context.sampleRate //输入采样率
, inputSampleBits: 16 //输入采样数位 8, 16
, outputSampleRate: config.sampleRate //输出采样率
, oututSampleBits: config.sampleBits //输出采样数位 8, 16
, input: function (data) {
this.buffer.push(new Float32Array(data));
this.size += data.length;
}
, compress: function () { //合并压缩
//合并
var data = new Float32Array(this.size);
var offset = 0;
for (var i = 0; i < this.buffer.length; i++) {
data.set(this.buffer[i], offset);
offset += this.buffer[i].length;
}
//压缩
var compression = parseInt(this.inputSampleRate / this.outputSampleRate);
var length = data.length / compression;
var result = new Float32Array(length);
var index = 0, j = 0;
while (index < length) {
result[index] = data[j];
j += compression;
index++;
}
return result;
}
, encodeWAV: function () {
var sampleRate = Math.min(this.inputSampleRate, this.outputSampleRate);
var sampleBits = Math.min(this.inputSampleBits, this.oututSampleBits);
var bytes = this.compress();
var dataLength = bytes.length * (sampleBits / 8);
var buffer = new ArrayBuffer(44 + dataLength);
var data = new DataView(buffer);
var channelCount = 1;//单声道
var offset = 0;
var writeString = function (str) {
for (var i = 0; i < str.length; i++) {
data.setUint8(offset + i, str.charCodeAt(i));
}
}
// 资源交换文件标识符
writeString('RIFF'); offset += 4;
// 下个地址开始到文件尾总字节数,即文件大小-8
data.setUint32(offset, 36 + dataLength, true); offset += 4;
// WAV文件标志
writeString('WAVE'); offset += 4;
// 波形格式标志
writeString('fmt '); offset += 4;
// 过滤字节,一般为 0x10 = 16
data.setUint32(offset, 16, true); offset += 4;
// 格式类别 (PCM形式采样数据)
data.setUint16(offset, 1, true); offset += 2;
// 通道数
data.setUint16(offset, channelCount, true); offset += 2;
// 采样率,每秒样本数,表示每个通道的播放速度
data.setUint32(offset, sampleRate, true); offset += 4;
// 波形数据传输率 (每秒平均字节数) 单声道×每秒数据位数×每样本数据位/8
data.setUint32(offset, channelCount * sampleRate * (sampleBits / 8), true); offset += 4;
// 快数据调整数 采样一次占用字节数 单声道×每样本的数据位数/8
data.setUint16(offset, channelCount * (sampleBits / 8), true); offset += 2;
// 每样本数据位数
data.setUint16(offset, sampleBits, true); offset += 2;
// 数据标识符
writeString('data'); offset += 4;
// 采样数据总数,即数据总大小-44
data.setUint32(offset, dataLength, true); offset += 4;
// 写入采样数据
if (sampleBits === 8) {
for (var i = 0; i < bytes.length; i++, offset++) {
var s = Math.max(-1, Math.min(1, bytes[i]));
var val = s < 0 ? s * 0x8000 : s * 0x7FFF;
val = parseInt(255 / (65535 / (val + 32768)));
data.setInt8(offset, val, true);
}
} else {
for (var i = 0; i < bytes.length; i++, offset += 2) {
var s = Math.max(-1, Math.min(1, bytes[i]));
data.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7FFF, true);
}
}
return new Blob([data], { type: 'audio/wav' });
}
};
//开始录音
this.start = function () {
audioInput.connect(recorder);
recorder.connect(context.destination);
}
//停止ֹ
this.stop = function () {
recorder.disconnect();
}
//获取音频文件
this.getBlob = function () {
this.stop();
return audioData.encodeWAV();
}
//回放
this.play = function (audio) {
audio.src = window.URL.createObjectURL(this.getBlob());
}
//转换
this.upload = function (url, num) {
var id = "audioText"+num;
var fd = new FormData();
fd.append("audioData", this.getBlob());
var xhr = new XMLHttpRequest();
xhr.open("POST", url);
xhr.send(fd);
xhr.onreadystatechange = function () {
if (xhr.readyState == 4 && xhr.status == 200) {
document.getElementById(id).value += xhr.responseText;
}
};
}
//音频采集
recorder.onaudioprocess = function (e) {
audioData.input(e.inputBuffer.getChannelData(0));
//record(e.inputBuffer.getChannelData(0));
}
};
//抛出异常
HZRecorder.throwError = function (message) {
alert(message);
throw new function () { this.toString = function () { return message; } }
}
//是否支持录音
HZRecorder.canRecording = (navigator.getUserMedia != null);
//获取录音机
HZRecorder.get = function (callback, config) {
if (callback) {
if (navigator.getUserMedia) {
navigator.getUserMedia(
{ audio: true } //只启用音频
, function (stream) {
var rec = new HZRecorder(stream, config);
callback(rec);
}
, function (error) {
switch (error.code || error.name) {
case 'PERMISSION_DENIED':
case 'PermissionDeniedError':
HZRecorder.throwError('用户拒绝提供信息。');
break;
case 'NOT_SUPPORTED_ERROR':
case 'NotSupportedError':
HZRecorder.throwError('浏览器不支持硬件设备。');
break;
case 'MANDATORY_UNSATISFIED_ERROR':
case 'MandatoryUnsatisfiedError':
HZRecorder.throwError('无法发现指定的硬件设备。');
break;
default:
HZRecorder.throwError('无法打开麦克风。异常信息:' + (error.name));
break;
}
});
} else {
HZRecorder.throwErr('当前浏览器不支持录音功能。'); return;
}
}
}
window.HZRecorder = HZRecorder;
})(window);
页面中也没有多少要注意的问题。注意的是每一个问题上方都有一个隐藏域,里面的值是问题的内容,这样做是为了将问题和答案一起存放在数据库中,因为form只能提交input中的内容,所以想出了这个办法,不知道还有没有其他方式。
(2)后台转换(SSM框架)
录音文件流以文件上传的方式传到后台(这里不必将文件流转换成音频文件,因为阿里云的实时语音识别Demo中是将文件转化为InputStream,再进行转文字,可直接获得MultipartFile的InputStream传给语音转换)
录音文件时长超过13分钟左右,在转换的过程中,通信会被关闭(即录音20分钟,只会转换10分钟的内容,本人目前不清楚具体的原因)暂时的解决办法是将上传的录音文件分割成两部分,分别执行转换的方法。
RecordController.java
package cn.com.sysystem.controller;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.util.List;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.multipart.MultipartFile;
import cn.com.sysystem.base.util.RealtimeAsr;
import cn.com.sysystem.entity.RecordEntity;
import cn.com.sysystem.model.RecordModel;
import cn.com.sysystem.service.RecordService;
@Controller
@RequestMapping("/audio")
public class RecordController{
@Resource
RecordService recordService;
@ResponseBody
@RequestMapping(value = "/getaudio" ,produces = "application/json; charset=utf-8")
public String getaudio(MultipartFile audioData,HttpServletRequest request) throws Exception {
StringBuffer sb = new StringBuffer(2000);
if (audioData != null) {
byte[] bytes = audioData.getBytes();
// 当录音文件过大时,将文件分割成两段
if (bytes.length < 20000000) {
InputStream inputStream = audioData.getInputStream();
sb.append(getText(inputStream));
} else {
byte[] tmp1 = new byte[bytes.length/2];
byte[] tmp2 = new byte[bytes.length-tmp1.length];
System.arraycopy(bytes, 0, tmp1, 0, tmp1.length);
System.arraycopy(bytes, tmp1.length, tmp2, 0, tmp2.length);
InputStream input1 = new ByteArrayInputStream(tmp1);
InputStream input2 = new ByteArrayInputStream(tmp2);
sb.append(getText(input1));
sb.append(getText(input2));
}
}else {
return "文件上传失败";
}
return sb.toString();
}
@ResponseBody
@RequestMapping(value = "/saveRecord")
public boolean saveRecord(RecordModel recordlist) throws Exception {
boolean flag = true;
List records = recordlist.getRecords();
for (RecordEntity recordEntity : records) {
int row = recordService.saveRecord(recordEntity);
if (row < 0) {
flag = false;
}
}
return flag;
}
@RequestMapping(value = "/getAllRecord")
public String getAllRecord(HttpServletRequest request) throws Exception {
List allRecord = recordService.getAllRecord();
request.setAttribute("recordList", allRecord);
return "showrecord";
}
/**
* 将语音输入流转换为文字
* @param input
* @return
*/
private synchronized String getText(InputStream input) {
StringBuilder finaltext = new StringBuilder(2000);
List results = null;
RealtimeAsr realtimeAsr = new RealtimeAsr();
results = realtimeAsr.AliAudio2Text(input);
// 去除集合中含有status_code = 0的元素
results.removeIf(p -> p.indexOf("\"status_code\":0") == -1);
for (String str : results) {
String text = "";
String[] split = str.split(",");
text = split[split.length-1];
text = text.substring(8, text.length()-2);
finaltext.append(text);
}
// 清空集合
results.clear();
return finaltext.toString();
}
}
Controller中getText方法,创建RealtimeAsr类的对象,调用AliAudio2Text方法获得转换结果,RealtimeAsr类如下:
RealtimeAsr.java
package cn.com.sysystem.base.util;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONPath;
import com.alibaba.idst.nls.realtime.NlsClient;
import com.alibaba.idst.nls.realtime.NlsFuture;
import com.alibaba.idst.nls.realtime.event.NlsEvent;
import com.alibaba.idst.nls.realtime.event.NlsListener;
import com.alibaba.idst.nls.realtime.protocol.NlsRequest;
import com.alibaba.idst.nls.realtime.protocol.NlsResponse;
/**
* asr 示例
*
*/
public class RealtimeAsr implements NlsListener {
protected NlsClient client = new NlsClient();
protected static final String asrSC = "pcm";
static Logger logger = LoggerFactory.getLogger(RealtimeAsr.class);
public String filePath = "";
//public String appKey = "nls-service-shurufa16khz"; //社交聊天领域
public String appKey = "nls-service-multi-domain"; //短视频,视频直播领域,教育,娱乐,文学,法律,财经等
//public String appKey = "nls-service-en"; //英语
protected String ak_id = ""; //阿里云的AccessKeyID 和 AccessKeySecret 自行去注册账户,这里就不提供了
protected String ak_secret = "";
protected String url = "https://nlsapi.aliyun.com/asr/custom/vocabs";
public static List results = new ArrayList(5000);
public RealtimeAsr() {
}
public void shutDown() {
logger.debug("close NLS client manually!");
client.close();
logger.debug("demo done");
}
public void start() {
logger.debug("init Nls client...");
client.init();
}
public void process() {
logger.debug("open audio file...");
FileInputStream fis = null;
try {
File file = new File(filePath);
fis = new FileInputStream(file);
} catch (Exception e) {
logger.error("fail to open file", e);
}
if (fis != null) {
logger.debug("create NLS future");
process(fis);
logger.debug("calling NLS service end");
}
}
public void process(InputStream ins) {
try {
NlsRequest req = buildRequest();
NlsFuture future = client.createNlsFuture(req, this);
logger.debug("call NLS service");
byte[] b = new byte[5000];
int len = 0;
while ((len = ins.read(b)) > 0) {
future.sendVoice(b, 0, len);
//Thread.sleep(200);
}
logger.debug("send finish signal!");
future.sendFinishSignal();
logger.debug("main thread enter waiting .");
future.await(100000);
} catch (Exception e) {
e.printStackTrace();
}
}
protected NlsRequest buildRequest() {
NlsRequest req = new NlsRequest();
req.setAppkey(appKey);
req.setFormat(asrSC);
req.setResponseMode("streaming");
req.setSampleRate(16000);
String body="{\n"
+ " \"global_weight\": 1,\n"
+ " \"words\": [\n"
+ " \"SpringMVC\",\n"
+ " \"Mybatis\",\n"
+ " \"Hibernate\"\n"
+ " ],\n"
+ " \"word_weights\": {\n"
+ " \"spring\": 2\n"
+ " }\n"
+ " }";
//create
String result=HttpUtil.sendPost(url,body,ak_id,ak_secret);
String vocabId=(String)JSONPath.read(result,"vocabulary_id");
//update
result=HttpUtil.sendPut(url+"/"+vocabId,body,ak_id,ak_secret);
req.setVocabularyId(vocabId);
// 设置关键词库ID 使用时请修改为自定义的词库ID
// req.setKeyWordListId("c1391f1c1f1b4002936893c6d97592f3");
req.authorize(ak_id, ak_secret);
return req;
}
@Override
public void onMessageReceived(NlsEvent e) {
NlsResponse response = e.getResponse();
response.getFinish();
if (response.result != null) {
String tmptext = response.getResult().toString();
results.add(tmptext);
//logger.debug("status code = {},get finish is {},get recognize result: {}", response.getStatusCode(),
// response.getFinish(), response.getResult());
if (response.getQuality() != null) {
logger.info("Sentence {} is over. Get ended sentence recognize result: {}, voice quality is {}",
response.result.getSentence_id(), response.getResult(),
JSON.toJSONString(response.getQuality()));
}
} else {
logger.info(JSON.toJSONString(response));
}
}
@Override
public void onOperationFailed(NlsEvent e) {
logger.error("status code is {}, on operation failed: {}", e.getResponse().getStatusCode(),
e.getErrorMessage());
}
@Override
public void onChannelClosed(NlsEvent e) {
logger.debug("on websocket closed.");
}
/**
* @param inputStream
*/
public List AliAudio2Text(InputStream inputStream) {
RealtimeAsr lun = new RealtimeAsr();
lun.start();
lun.process(inputStream);
lun.shutDown();
return results;
}
}
注意的地方
1、@RequestMapping(value = "/getaudio" ,produces = "application/json; charset=utf-8")
produces = "application/json; charset=utf-8" 保证Controller在return中文时乱码的问题。
2、StringBuffer sb = new StringBuffer(2000);
因为要经常拼接字符串,所以StringBuffer的效率会比String高些,另外还有一个小窍门,就是在new StringBuffer时指定大小,若不指定且内容较长时,会频繁的扩容,影响性能(具体也不知道能提高多少,提高一点是一点吧,同时集合中的list和map也是一样的道理)
3、synchronized
转换的方法中加入synchronized关键字保证线程安全的目的是,当上一段录音时长较长时,转换需要一定的时间(20分钟的音频,转换过程3分钟左右),若立即开始第二段录音,且时间较短,若不加锁,第二段转换的文本中显示的是第一段的内容。
4、results.removeIf(p -> p.indexOf("\"status_code\":0") == -1);
这里用到了Java8的Lambda表达式,不明白的同学可以自行了解一下,很好用。
5、
语音转换收集到的信息如下:(例如说ABCD)
{"sentence_id":1,"begin_time":280,"current_time":1670,"end_time":-1,"status_code":1,"text":"A"}
{"sentence_id":1,"begin_time":280,"current_time":1670,"end_time":1793,"status_code":0,"text":"A B C D"}
其中status_code = 1 表示的是转换的中间状态,status_code = 0表示语音转换完成。所以我们要从集合中筛选出status_code = 0的所有字符串,并截取text的值。