Hive
Hive
- Hive简介
- Hive组件
- Hive CLI 操作
- Hive 命令中 可用变量及区别
- 在Hive CLI 中执行其他命令
- 执行Linux shell命令
- 执行 Hadoop的 fs 命令
- Hive支持的数据类型
- 基本类型
- 复杂类型
- 类型转换
- Hive 数据库操作
- 创建数据库
- 查看指定数据库的详细信息
- 查看所有数据库名
- 使用正则表达式匹配来筛选出需要的数据库名
- 使用指定数据库
- 删除数据库
- Hive 表操作
- 创建表
- 创建内部表(也称管理表)
- 创建外部表
- Hive 默认分隔符
- 分区表(基于内部表和外部表)
- 创建分区表
- 查看表的分区 及其 存储路径
- 复制表模型式 创建表
- 查询语句中创建表并加载数据
- 删除表
- 修改表
- 增加、修改 或 删除表分区
- 增加表分区(通用于外部表)
- 修改表分区的存储路径
- 删除表分区
- 修改表名
- 修改 字段信息
- 修改 表存储格式
- 防止分区被删除和被查询
- 增加 字段
- 删除或者替换 字段
- 查看数据库所有表
- 查看指定表的详细结构信息
- HiveQL 数据查询
- 字段区可用函数和运算符
- 算数运算符 和 逻辑运算符
- 数学函数
- 聚合函数
- 表生成函数
- 字符函数
- 时间函数
- 自定义函数
- jar包 UDF
- Python UDF
- where条件区 支持的运算符
- 比较运算符
- 逻辑运算符
- 模糊筛选
- 范围筛选
- 判空筛选
- 高级查询
- 排序(ORDER BY 和 SORT BY)
- CLUSTER BY、DISTRIBUTE BY、SORT BY
- 分页(limit)
- 起别名(as)
- 去重(distinct)
- 分组查询(group by)
- case表达式
- 联表查询
- 内连接
- 左外连接 (LEFT OUTER JOIN)
- 右外连接(RIGHT OUTER JOIN)
- 完全外连接(FULL OUTER JOIN)
- 合并表(UNION ALL)
- HiveQL 数据的加载和导出
- 加载数据
- 通过查询语句向表中追加数据
- 动态分区插入
- 开启动态分区
- 导出数据
- Hive数据模型 对应 HDFS的存储位置
Hive官方文档链接
Hive简介
- 基于
Hadoop的一个数据仓库工具 - 将 结构化的数据映射为一张数据库表
- 提供
HQL(Hive SQL)查询功能,底层数据是存储在HDFS上 Hive本质: 将SQL语句转换为MapReduce任务运行,使不熟悉MapReduce的用户很方便地利用HQL处理和计算HDFS上的结构化的数据- 主要用来做离线数据分析,比直接用
MapReduce开发效率更高 - 没有集群的概念,如果想提交
Hive作业只需要在hadoop集群Master节点上装Hive
Hive对比关系型数据库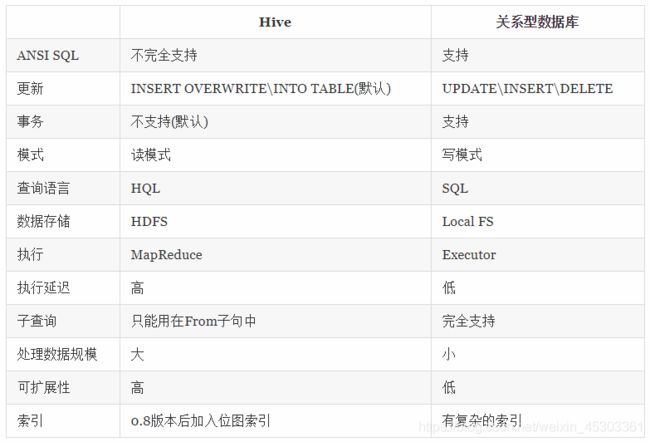
Hive组件
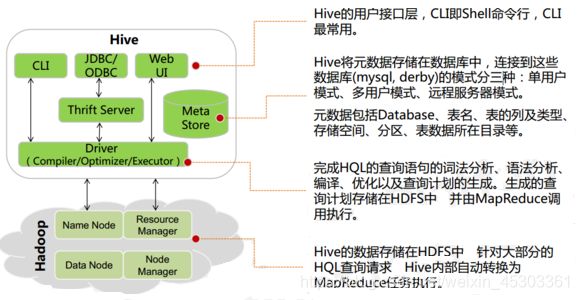
- 用户接口:包括
CLI、JDBC/ODBC、WebGUICLI(command line interface)为shell命令行JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似,通过Thrift Server, 允许远程客户端使用多种编程语言如Java、Python向Hive提交请求Web UI是通过浏览器访问Hive
- 元数据存储:通常是存储在关系数据库如
mysql/derby中Hive将元数据存储在数据库中Hive中的元数据包括- 表的名字
- 表的列
- 分区及其属性
- 表的属性(是否为外部表等)
- 表的数据所在目录等
- 解释器、编译器、优化器、执行器:完成
HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行
Hive CLI 操作
启动Hive Shell :$HIVE_HOME/bin/hive 之后通向命令行界面执行CLI 操作
$ hive --help --service cli
usage: hive
-d,--define 自定义变量,方便Hive命令使用
例如: -d A=B or --define A=B
-e 一次性 Hive Shell 执行命令后关闭
例如:hive -e "SELECT * FROM mytable LIMIT 3";
-f 执行文件中的Hive命令
例如:hive -f /path/to/file/withqueries.hql 一般Hive文件后缀名设为.hql
-H,--help 打印出帮助信息
-h 连接到远程主机上的Hive服务器
--hiveconf 使用Hive配置属性的值
--hivevar 自定义变量,方便Hive命令使用 与 -d,--define 等价
例如: --hivevar A=B
-i 初始化SQL文件,当CLI启动时,在提示符出现前会先执行这个文件
Hive会自动在HOME目录下寻找名为.hiverc的文件
而且会自动执行这个文件中的命令(如果文件中有的话)
-p 连接到Hive服务器的端口号上
-S,--silent 交互式shell中的静默模式,输出结果中去掉“OK” 和“Time taken”等无关紧要的输出信息
-v,--verbose 详细模式(将执行的SQL回送到控制台)
Hive 命令中 可用变量及区别

$ hive --define foo=bar 定义一个变量
hive> set foo; SET命令显示或者修改变量值
foo=bar;
hive> set hivevar:foo;
hivevar:foo=bar;
hive> set hivevar:foo=bar2;
hive> set foo;
foo=bar2
hive> set hivevar:foo;
hivevar:foo=bar2 证明 --define 与 hivevar 等价 并且 hivevar:是可选的
变量的使用案例
hive> create table toss(i int, ${hivevar:foo} string); 创建一个表
hive> describe toss; 显示 toss表的详细信息
i int
bar2 string
--hiveconf 该变量,主要用于修改Hive配置 或 使用配置的值
$ hive --hiveconf hive.c li.print.current.db=true 显示当前使用的数据库名 默认不开启
hive (default)> set hive.cli.print.current.db;
hive.cli.print.current.db=true
$ hive> set hive.cli.print.header=true; 显示字段名称
hive> SELECT * FROM system_logs LIMIT 3;
......
$ hive --hiveconf y=5
hive> set y;
y=5
hive> CREATE TABLE whatsit(i int);
hive> SELECT * FROM whatsit WHERE i = ${hiveconf:y};
system命名空间, Java系统属性对这个命名空间内容具有可读可写权利
而env命名空间,对于环境变量只提供可读权限:
必须使用system:或者env:前缀来指定系统属性和环境变量
hive> set system:user.name;
system:user.name=myusername
hive> set system:user.name=yourusername;
hive> set system:user.name;
system:user.name=yourusername
hive> set env:HOME;
env:HOME=/home/yourusername
hive> set env:HOME=xxx;
env:* variables can not be set.
当用户不能完整记清楚某个属性名时,可以模糊获取这个属性名进行查找
假设用户没记清哪个属性指定了管理表的“warehouse(数据仓库)”的路径,通过如下命令可以查看到:
$ hive -S -e "set" | grep warehouse
hive.metastore.warehouse.dir=/user/hive/warehouse
hive CLI立即退出。Hive提供了这样的功能,因为CLI可以接受-e 命令这种形式。如果表mytable具有一个字符串字段和一个整型字段,我们可以看到如下输出:
$ hive -e "SELECT * FROM mytable LIMIT 3";
OK
name1 10
name2 20
name3 30
Time taken: 4.955 seconds
$
临时应急时可以使用这个功能将查询结果保存到一个文件中。增加-S选项可以开启静默模式,这样可以在输出结果中去掉“OK” 和“Time taken”等行,以及其他一些无关紧要的输出信息,如下面这个例子:
$ hive -S -e "select * FROM mytable LIMIT 3" > /tmp/myquery
$ cat /tmp/myquery
name1 10
name2 20
name3 30
需要注意的是,Hive会将输出写到标准输出中。上面例子中的shell命令将输出重定向到本地文件系统中,而不是HDFS中。
最后,当用户不能完整记清楚某个属性名时,可以使用下面这个非常有用的技巧来模糊获取这个属性名而无需滚动set命令的输出结果进行查找。假设用户没记清哪个属性指定了管理表的“warehouse(数据仓库)”的路径,通过如下命令可以查看到:
$ hive -S -e "set" | grep warehouse
hive.metastore.warehouse.dir=/user/hive/warehouse
hive.warehouse.subdir.inherit.perms=false
在Hive CLI 中执行其他命令
用户不需要退出hive CLI就可以执行简单的 bash shell命令 或 Hadoop命令
执行Linux shell命令
只要在命令前加!并且以分号;结尾就可以:
hive> ! /bin/echo "what up dog";
"what up dog"
hive> ! pwd;
/home/me/hiveplay
但是,Hive CLI中不能使用需要用户进行输入的交互式命令,而且不支持shell的“管道”功能和文件名的自动补全功能
例如:! ls *.hql;这个命令表示的是查找文件名为*.hql的文件,而不是表示显示以.hql结尾的所有文件
执行 Hadoop的 fs 命令
只需将hadoop命令中的关键字hadoop去掉,然后以==;结尾==就可以:
hive> fs -ls / ;
hive> fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2;
这种使用hadoop 命令的方式实际上比与其等价的在bash shell中执行的hadoop fs -…命令要更高效。因为后者每次都会启动一个新的JVM实例,而Hive会在同一个进程中执行这些命令
Hive支持的数据类型
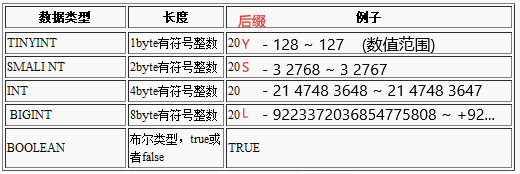
基本类型
- 整数型
TINYINT、SMALLINT、INT、BIGINT,布尔型(BOOLEAN)
- 小数型
FLOAT、DOUBLE、DECIMALS

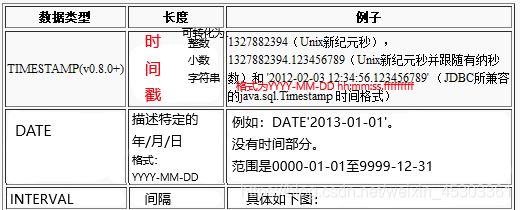
- 日期/时间类型
TIMESTAMP 时间、DATE 日期 、INTERVAL 间隔
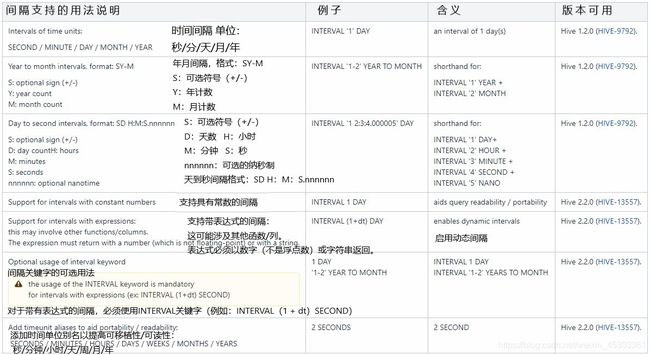
- 字符串类型
CHAR、VARCHAR、STRING
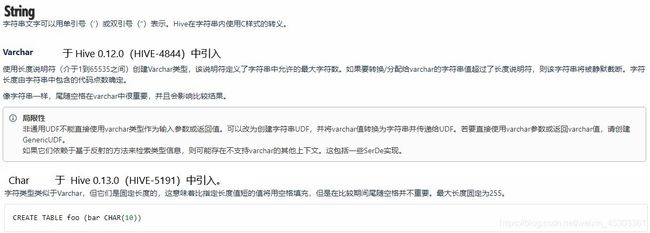
复杂类型
ARRAY:ARRAY
例如:ARRAY(STRING)表示ARRAY中的每个元素的数据类型必须是stringMAP:MAP
例如:MAP表示map中的每个键都是STRING数据类型的,而每个值都是FLOAT数据类型的STRUCT:STRUCT
STRUCT可以混合多种不同的数据类型,但是STRUCT中一旦声明好结构,那么其位置就不可以再改变- 注意:从
Hive 0.14开始,允许使用负值和非常量表达式
- union:(UNIONTYPE
注意:仅从 Hive 0.7.0开始可用)
类型转换
使用 cast(数据 as 想要转换的类型) 函数
select cast(float1 as boolean) from decimal_2;
能否转化示意表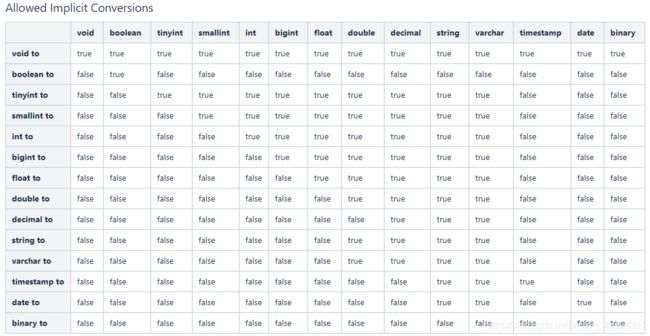
Hive 数据库操作
Hive中数据库:本质上仅仅是HDFS上的一个目录或者命名空间
如果用户没有显式指定数据库,那么将会使用默认的数据库default
数据库一旦建成 其 数据库名 和 存储位置 是无法修改的
创建数据库
格式:hive> CREATE DATABASE 数据库名; 重名则报错
格式:hive> CREATE DATABASE IF NOT EXISTS 数据库名; 重名不报错
hive> CREATE DATABASE financials;
hive> CREATE DATABASE IF NOT EXISTS financials; 用于若存在,则可用已有的数据库
- 创建同时指定存储位置
格式:hive> CREATE DATABASE 数据库名 LOCATION '指定数据库在HDFS中的位置';hive> CREATE DATABASE financials LOCATION '自定义数据库存储在HDFS上的位置'; 不指定,则默认存储位置在属性hive.metastore.warehouse.dir所指定的目录下 - 创建同时添加描述信息
hive> CREATE DATABASE financials COMMENT '描述信息';
查看指定数据库的详细信息
hive> DESCRIBE DATABASE financials;
financials Holds all financial tables 描述信息
hdfs://host:port/user/hive/warehouse/financials.db 存储位置
查看所有数据库名
hive> SHOW DATABASES;
default
financials
使用正则表达式匹配来筛选出需要的数据库名
hive> SHOW DATABASES LIKE 'f.*'; 搜索f开头任意结尾的数据库名
financials
...
使用指定数据库
将某个数据库设置为用户当前的工作数据库,
hive> USE 指定数据库名;
但是,并没有一个命令可以让用户查看当前所在的是哪个数据库!
幸运的是,在Hive中是可以重复使用USE …命令的,这是因为在Hive中并没有嵌套数据库的概念。
也可以通过设置一个属性值来在提示符里面显示当前所在的数据库:
hive> set hive.cli.print.current.db=true;
hive (financials)> USE default;
hive (default)> set hive.cli.print.current.db=false;
hive> ...
删除数据库
hive> DROP DATABASE IF EXISTS 数据库名;
IF EXISTS子句是可选的,若有则可避免因数据库不存在而抛出警告信息
Hive是默认无法删除一个非空数据库,
需要先删除数据库中的表,然后再删除数据库;
要么在删除命令的最后面加上关键字CASCADE,才可以使Hive删除非空数据库:
hive> DROP DATABASE IF EXISTS financials CASCADE;
Hive 表操作
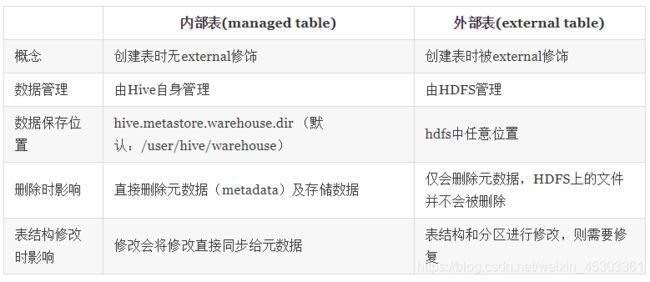
Hive中表类型分为:内部表(managed table) 和 外部表 两种
创建表
创建内部表(也称管理表)
Hive会控制其数据的生命周期,Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下
但是,管理表不方便和其他工作共享数据。例如,假设我们有一份由Pig或者其他工具创建并且主要由这一工具使用的数据,同时我们还想使用Hive在这份数据上执行一些查询,可是并没有给予Hive对数据的所有权,这是可创建一个外部表指向这份数据
CREATE TABLE 目标数据库.表名(
字段名 数据类型
name STRING,
salary FLOAT,
subordinates ARRAY,
deductions MAP,
address STRUCT)
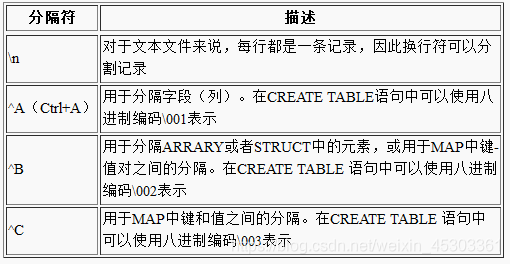
ROW FORMAT DELIMITED 若指定分隔符,则这组关键字必须要写在其他子句前
FIELDS TERMINATED BY '\001' 默认:^A字符作为字段分割符
COLLECTION ITEMS TERMINATED BY '\002' 默认:^B作为array和struct集合元素间的分隔符
MAP KEYS TERMINATED BY '\003' 默认:^C作为map的键和值之间的分隔符
LINES TERMINATED BY '\n' 行与行之间的分隔符只能为‘\n’
COMMENT 'Description of the table' 添加描述信息
STORED AS TEXTFILE; 存储为文本文件
- 若工作数据库并就是目标数据库,表名前的目标数据库名可以省略
IF NOT EXITS选项可选,在CREATE TABLE之后,表示若表已经存在了,Hive就会忽略掉后面的执行语句,而且不会有任何提示。但新表模式若和旧表模式不一致,Hive也不会为此做出提示和修改
创建外部表
在CREATE之后添加EXTERNAL 选项
CREATE EXTERNAL TABLE student (classNo string, stuNo string, score int) row format delimited
fields terminated by ',' 指定 逗号 为字段分隔符
location '/root/tmp/student'; 自定义存储位置
Hive 默认分隔符
将下文数据导入到上文创建的数据表中
John Doe^A100000.0^AMary Smith^BTodd Jones^AFederal Taxes^C.2^BStateTaxes^C.05^ BInsurance^C.1^A
1 Michigan Ave.^BChicago^BIL^B60600
以josn表示便是:
{
"name": "John Doe",
"salary": 100000.0,
"subordinates": ["Mary Smith", "Todd Jones"],
"deductions": {
"Federal Taxes": .2,
"State Taxes": .05,
"Insurance": .1
},
"address": {
"street": "1 Michigan Ave.",
"city": "Chicago",
"state": "IL",
"zip": 60600
}
}
分区表(基于内部表和外部表)
- 随着表的不断增大,对于新纪录的增加,查找,删除等(DML)的维护也更加困难。对于数据库中的超大型表,可以通过把它的数据分成若干个小表,从而简化数据库的管理活动,对于每一个简化后的小表,我们称为一个单个的分区。
hive中分区表实际就是对应hdfs文件系统上独立的文件夹,该文件夹内的文件是该分区所有数据文件。
分区可以理解为分类,通过分类把不同类型的数据放到不同的目录下。
分类的标准就是分区字段,可以一个,也可以多个。
分区表的意义在于优化查询。查询时尽量利用分区字段。如果不使用分区字段,就会全部扫描。
创建分区表
CREATE TABLE employees ( 若添加 EXTERNAL和储存地址 则表示 创建外部分区表
name STRING,
salary FLOAT,
subordinates ARRAY,
deductions MAP,
address STRUCT
)
PARTITIONED BY (country STRING, state STRING) 指定 分区字段 及其 数据类型
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile;
Hive将会创建好可以反映分区结构的子目录。例如:
...
.../employees/country=CA/state=AB
.../employees/country=CA/state=BC
...
.../employees/country=US/state=AL
.../employees/country=US/state=AK
...
使用方法
SELECT * FROM employees WHERE country = 'US' AND state = 'IL';
查看表的分区 及其 存储路径
- 查看表的所有分区
格式:SHOW PARTITIONS 表名;hive> SHOW PARTITIONS employees; ... Country=CA/state=AB country=CA/state=BC ... country=US/state=AL country=US/state=AK .. - 查看指定分区的存储位置
格式:DESCRIBE EXTENDED 表名 PARTITIONED (country='xxx', state='xxx') ;hive> DESCRIBE EXTENDED log_messages PARTITION (country = 'US', state = 'IL');
复制表模型式 创建表
根据已有表的表模式(而无需拷贝数据)复制出一张新表 :
CREATE TABLE IF NOT EXISTS mydb.student1
LIKE mydb.student
location '/root/tmp/student'; 仅支持自定义存储位置
但是注意表的属性,仅存储位置支持修改,其余属性都是不可能重新定义的,而是直接从已有表复制获得
查询语句中创建表并加载数据
创建表并将查询结果载入这个表的操作:
CREATE TABLE ca_employees
AS SELECT name, salary, address
FROM employees
WHERE se.state = 'CA';
新表的模式是根据SELECT语句和源表 来生成的
使用这个功能的常见情况是从一个大的宽表中选取部分需要的数据集。
这个功能不能用于外部表,因该命令并没有进行数据“装载”,而是将元数据中指定一个指向数据的路径
删除表
格式:DROP TABLE IF EXISTS 表名;
IF EXITST关键字可选,表示若表并不存在的话,不会抛出错误信息
对于管理表,表的元数据信息和表内的数据都会被删除
对于外部表,表的元数据信息会被删除,但是表中的数据不会被删除
Hadoop回收站功能(默认关闭):那么数据将会被转移到用户在分布式文件系统中的用户根目录下的.Trash目录下。如果想开启这个功能,只需要将配置属性fs.trash.interval的值设置为一个合理的正整数即可。这个值是“回收站检查点”间的时间间隔 ,单位是分钟。因此如果设置值为1440,那么就表示是24小时。
如果用户不小心删除了一张存储着重要数据的管理表的话,那么可以先重建表,然后重建所需要的分区,再从.Trash目录中将误删的文件移动到正确的文件目录下(使用文件系统命令)来重新存储数据
修改表
会修改元数据,但不会修改数据本身
增加、修改 或 删除表分区
增加表分区(通用于外部表)
格式:ALTER TABLE 表名 ADD PARTITION (分区字段1=值1,分区字段2=值2, ...)
ALTER TABLE log_messages ADD IF NOT EXISTS
PARTITION (year = 2011, month = 1, day = 1) LOCATION '/logs/2011/01/01'
PARTITION (year = 2011, month = 1, day = 2) LOCATION '/logs/2011/01/02'
PARTITION (year = 2011, month = 1, day = 3) LOCATION '/logs/2011/01/03'
...;
修改表分区的存储路径
ALTER TABLE log_messages PARTITION(year = 2011, month = 12, day = 2)
SET LOCATION 's3n://ourbucket/logs/2011/01/02';
该命令仅将数据复制到新的路径下,不会删除旧的数据
使用hadoop fs –rmr 命令删除掉HDFS中的这个分区数据:
hive> fs -rmr /data/log_messages/2011/01/02
删除表分区
ALTER TABLE log_messages DROP IF EXISTS PARTITION(year = 2011, month = 12, day = 2);
IF EXISTS 子句是可选的
对于管理表,即使是使用ALTER TABLE … ADD PARTITION语句增加的分区,分区内的数据也是会同时和元数据信息一起被删除的
对于外部表,仅删除元数据,分区内数据不会被删除
修改表名
使用以下这个语句可以将表log_messages重命名为logmsgs:
ALTER TABLE log_messages RENAME TO logmsgs;
修改 字段信息
对某个字段进行重命名,修改其位置、数据类型或者注释:
ALTER TABLE 表名
CHANGE COLUMN 旧字段名 新字段名 数据类型
COMMENT '描述信息'
AFTER 指定字段; # 将该字段调到指定字段之后
CHANGE COLUMN和COMMENT子句 为可选需修改才使用CHANGE COLUMN子句 中 必须包含 完整三项 即使不修改表名或类型- 使用
FIRST关键字替代AFTER 指定字段子句即可 将该字段放置表首列
修改 表存储格式
下面这个语句将一个分区的存储格式修改成了SEQUENCEFILE
ALTER TABLE 表名
PARTITION(year = 2012, month = 1, day = 1)
SET FILEFORMAT SEQUENCEFILE;
如果表是分区表,那么需要使用PARTITION子句
常用的存储类型:
TEXTFILE:文本格式,使用字母、数字、字符编码,包括那些国际字符集SEQUENCEFILE和RCFILE:两种皆为 二进制编码和压缩(可选)格式,来优化磁盘空间使用以及I / O带宽性能的
可以指定一个新的SerDe(序列化),并为其指定SerDe属性,或者修改已经存在的SerDe的属性
下面这个例子演示的表使用了一个名为com.example.JSONSerDe的Java类来处理记录使用JSON编码的文件:
ALTER TABLE table_using_JSON_storage
SET SERDE 'com.example.JSONSerDe'
WITH SERDEPROPERTIES (
'prop1' = 'value1',
'prop2' = 'value2');
SERDEPROPERTIES中的属性会被传递给SerDe模块(本例中,也就是com.example.JSONS erDe这个Java类)
需要注意的是,属性名(例如prop1)和属性值(例如value1)都应当是带引号的字符串
防止分区被删除和被查询
ALTER TABLE log_messages
PARTITION(year = 2012, month = 1, day = 1) ENABLE NO_DROP; 防删
ALTER TABLE log_messages
PARTITION(year = 2012, month = 1, day = 1) ENABLE OFFLINE; 放查
使用DISABLE替换ENABLE可以达到反向操作的目的
仅限非分区表可用
增加 字段
用户可以在分区字段之前增加新的字段到已有的字段之后
ALTER TABLE 表名 ADD COLUMNS (
新字段名1 数据类型 COMMENT '描述信息',
新字段名2 数据类型 COMMENT '描述信息',
...);
如果新增的字段中有某个或多个字段位置是错误的,那么需要使用 ALTER COULME 表名 CHANGE COLUMN语句逐一将字段调整到正确的位置
删除或者替换 字段
该命令会 移除表之前的所有字段并重新指定新字段:
ALTER TABLE log_messages REPLACE COLUMNS (
hours_mins_secs INT COMMENT 'hour, minute, seconds from timestamp',
severity STRING COMMENT 'The message severity'
message STRING COMMENT 'The rest of the message');
查看数据库所有表
命令:SHOW TABLES IN 指定数据库 表示查看指定数据库下的所有表
假设我们的工作数据库是mydb,包含 table1、table2 和 employees 三个表:
hive> USE default;
hive> SHOW TABLES IN mydb; 查看指定数据库下的所有表
employees
table1
table2
hive> USE mydb;
hive> SHOW TABLES; 若查看当前工作数据库下的所有表,则无需指定数据库
employees
table1
table2
可以使用正则表达式来过滤出所需要的表名
hive> USE mydb;
hive> SHOW TABLES 'empl.*'; 选出当前数据库中以 empl 开头的表名
employees
但是Hive并非支持所有的正则表达式功能
查看指定表的详细结构信息
格式:DESCRIBE EXTENDED 指定数据库.指定表名.指定字段
其中:
- 若工作数据库即为目标数据库 则可省略数据库名
- 若是看整个表的结构信息,则不必指定字段
FORMATTED可选,作用时信息更加详细
hive> DESCRIBE FORMATTED mydb.employees;
name string Employee name
salary float Employee salary
subordinates array Names of subordinates
deductions map Keys are deductions names, values are percentages
address struct Home address
Detailed Table Information Table(tableName:employees, dbName:mydb, owner:me,
location:hdfs://master-server/user/hive/warehouse/mydb.db/employees 储存表数据的HDFS 的完整路径
... tableType:MANAGED_TABLE) 表示为 管理表 即 内部表
... tableType:EXTERNAL_TABLE) 显示表类型 为 外部表
HiveQL 数据查询
格式:SELEC 要查询的字段1 字段2 字段区可用函数(字段3) ... FROM 表名 WHERE 条件
- 若查看全字段,可用
*替代整个字段区 - 若不添加条件子句表示 查看全表
- 查询分区表时查询条件中尽量包含分区字段
- 复杂格式
ARRER的显示形式及单独查看其中的元素
显示形式[元素1,元素2,...]可使用字段名[下标]查看其中的元素hive> SELECT name, subordinates subordinates[0] FROM employees; John Doe ["Mary Smith","Todd Jones"] Mary Smith Mary Smith ["Bill King"] Bill King Todd Jones [] NULL ARRAY为空返回 [ ] Bill King [] NULL 提取的元素为空返回 NULL - 复杂格式
MAP的显示形式及单独查看其中的值元素
显示形式{"键1":值1, "键2":值2,...}可使用字段名[键名]查看其中的值元素hive> SELECT name, deductions deductions["Federal Taxes"] FROM employees; John Doe {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} 0.2 Mary Smith {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1} 0.2 ... - 复杂格式
STRUCT的显示形式及单独查看其中的元素
显示形式{"键1":值1, "键2":值2,...}可使用字段名.键名查看其中的值元素hive> SELECT name, address address.city FROM employees; John Doe {"street":"1 Michigan Ave.","city":"Chicago","state":"IL", "zip":60600} Chicago Mary Smith {"street":"100 Ontario St.","city":"Chicago","state":"IL", "zip":60601} Chicago ... - 使用正则表达式来指定字段
下面的查询将会从表stocks中选择symbol列和所有列名以price作为前缀的列:hive> SELECT symbol, `price.*` FROM stocks; AAPL 195.69 197.88 194.0 194.12 194.12 AAPL 192.63 196.0 190.85 195.46 195.46 ...
字段区可用函数和运算符
算数运算符 和 逻辑运算符
| 运算符 | 描述 | 含义 |
|---|---|---|
| + | 加 | - |
| - | 减 | - |
| * | 乘 | 9*3等于数学上的9×3 |
| / | 除 | 9/3等于数学上的9÷3 |
| // | 取整 | 返回除法结果的商 7//2 输出结果3 |
| % | 取余 | 返回除法结果的余数 7% 2 输出结果1 |
A&B |
按位取取与 | A和B的二进制同位数都为1取1,有一个数为0取0 如:4&8 为0 ;3&2 为2 |
A|B |
按位取取或 | A和B的二进制同位数有一个为1取1,两个数为0取0 如:4|8 为12;3|2为3 |
~A |
按位取反 | A的二进制同位数1取0,0取1 如:~3 为 -4 |
A^B |
按位取亦或 | 二进制同位数相同取0,不同取1 如:2^3 为 1 |
hive> SELECT name, salary, deductions["Federal Taxes"],
> round(salary * (1 - deductions["Federal Taxes"])) FROM employees;
John Doe 100000.0 0.2 80000
Mary Smith 80000.0 0.2 64000
...
数学函数
| 命令 | 描述 | 返回值类型 |
|---|---|---|
round(DOUBLE d ) |
返回 d(DOUBLE型)的 整数近似值 |
BIGINT |
round(DOUBLE d, INT n) |
返回 d(DOUBLE型)的保留n位小数的近似值 |
DOUBLE |
floor(DOUBLE d ) |
返回<= d (d为DOUBLE型)的最大整值(向下取整) |
BIGINT |
ceil(DOUBLE d) |
返回>= d (d为DOUBLE型)的最小整值 (向上取整) |
BIGINT |
rand(INT 随机因子) |
每行返回一个DOUBLE型随机数,随机因子为INT型 并 可选 |
DOUBLE |
ln(DOUBLE d) |
以自然数为底 d的对数DOUBLE |
|
log10(DOUBLE d) |
以10为底d的对数 |
DOUBLE |
log2(DOUBLE d) |
返回以2为底d的对数 | DOUBLE |
log(DOUBLE base, DOUBLE d) |
以 base为底d的对数 |
DOUBLE |
exp(DOUBLE d) |
返回 自然数e的d次幂值 |
DOUBLE |
pow(DOUBLE d,DOUBLE p) |
计算 d的p次幂 |
DOUBLE |
sqrt(d) |
计算 d的平方根 |
DOUBLE |
bin(BIGINT i) |
计算二进制值i表示的STRING类型值 |
STRING |
hex(i) |
计算i表达的STRING类型值,i 为十六进制数 或 字符串型数字 |
STRING |
unhex(STRING i) |
返回字符串 i 表达的 值, hen() 的逆操作 |
BIGINT |
conv(num, INT from_base, INT to_base) |
将num (BGINT或STRING型)从from_base进制转换成to_base进制 |
STRING |
abs( d ) |
计算数值型d的绝对值 |
原数剧类型 |
pmod(i1, i2) |
i1 (INT型或DOUBLE型)对i2 (INT型或DOUBLE型)取模 |
INT型或DOUBLE型 |
sin( d ) |
在弧度度量中,返回数值型d的正弦值 |
DOUBLE |
asin(d) |
在弧度度量中,返回数型值d的反正弦值 |
DOUBLE |
cos(d) |
在弧度度量中,返回数型值d的余弦值 |
DOUBLE |
acos(d) |
在弧度度量中,返回数型值d的反余弦值 |
DOUBLE |
tan(d) |
在弧度度量中,返回数型值d的正切值 |
DOUBLE |
atan(d) |
在弧度度量中,返回数型值d的反正切值 |
DOUBLE |
degrees(d) |
将弧度值d转换成角度值 |
DOUBLE |
radians(d) |
将角度值d转换成弧度值 |
DOUBLE |
positive( i ) |
返回数型值i的正值 |
原数据类型 |
negative( i) |
返回数型值i的负数 |
原数剧类型 |
sign(d) |
如果d是正数则返回1.0;是负数则返回-1.0;是0则返回0.0 |
FLOAT |
e() |
数学常数e,也就是超自然数 |
DOUBLE |
pi() |
数学常数π,也就是圆周率 |
DOUBLE |
聚合函数
| 命令 | 描述 | 返回值类型 |
|---|---|---|
count(*) |
计算总行数,包括含有NULL值的行 |
BIGINT |
count(expr) |
计算非NULL的行数 |
BIGINT |
count(DISTINCT expr[, expr_.]) |
计算非空非重的行数 | BIGINT |
sum(col) |
计算指定行的值的和 | DOUBLE |
sum(DISTINCT col) |
计算排重后值的和 | DOUBLE |
avg(col) |
计算指定行的值的平均值 | DOUBLE |
avg(DISTINCT col) |
计算排重后的值的平均值 | DOUBLE |
min(col) |
计算指定行的最小值 | DOUBLE |
max(col) |
计算指定行的最大值 | DOUBLE |
variance(col), var_pop(col) |
返回集合col中的一组数值的方差,忽略空行 | DOUBLE |
var_samp(col) |
返回集合col中的一组数值的样本方差,忽略空行 | DOUBLE |
stddev_pop(col) |
返回一组数值的标准偏差,忽略空行 | DOUBLE |
stddev_samp(col) |
返回一组数值的标准样本偏差,忽略空行 | DOUBLE |
covar_pop(col1, col2) |
返回一组数值的协方差,忽略空行 | DOUBLE |
covar_samp(col1, col2) |
返回一组数值的样本协方差,忽略空行 | DOUBLE |
corr(col1, col2) |
返回两组数值的相关系数 | DOUBLE |
collect_set(col) |
返回集合col元素排重后的数组 | ARRAY |
percentile(BIGINT int_expr, p) |
中位数函数,int_expr中处在p(范围在[0,1],DOUBLE型)对应百分比处的值 |
DOUBLE |
percentile(BIGINT int_expr,ARRAY(P1[,P2]…)) |
中位数函数,int_expr中处在p(范围在[0,1],DOUBLE型)对应百分比处的一系列值 |
DOUBLE |
percentile_approx (DOUBLE col,p[ , NB]) |
近似中位数函数,col中处在p(范围在[0,1])对应百分比处的值,NB控制近似精度,B越大,准确度越高(默认是10000) |
DOUBLE |
percentile_approx(DOUBLE col,ARRAY(p1[,p2]…)[, NB]) |
近似中位数函数,col中处在p(范围在[0,1])对应百分比处的一系列值 |
ARRAY |
histogram_numeric(col, NB) |
以NB为基准计算col的直方图信息。返回NB数量的直方图仓库数组,值x是中心,值y是仓库的高 | ARRAY |
hive> SELECT count(*), avg(salary) FROM employees;
表生成函数
与聚合函数“相反的”一类函数就是表生成函数,其可以将单列扩展成多列或者多行
| 命令 | 描述 | 返回值类型 |
|---|---|---|
explode(ARRAY型字段名) |
将array数组拆开,每个元素为一行 |
N行结果 |
explode(MAP型字段名) |
将map炸开,每行对应每个map键-值对,其中一个字段是map的键,另一个字段对应map的值(Hive 0.8.0版本新增) |
N行结果 |
explode(ARRAY |
对于a中的每个元素,explode()会生成一行记录包含这个元素 | 数组的类型 |
inline(ARRAY |
将结构体数组提取出来并插入到表中(Hive 0.10.0版本新增) | 结果插入表中 |
json_tuple(STRING jsonStr, p1, p2, …,pn) |
本函数可以接受多个标签名称,对输入的JSON字符串进行处理,这个get_json_object这个UDF类似,不过更高效,其通过一次调用就可以获得多个键值 | TUPLE |
parse_url_tuple(url, partname1, partname2, …,partnameN) 其中 N >= 1 |
从URL中解析出N个部分信息。其输入参数是:URL,以及多个要抽取的部分的名称。所有输入的参数的类型都是STRING。部分名称是大小写敏感的,而且不应该包含有空格:HOST, PATH, QUERY, REF,PROTOCOL, AUTHORITY, FILE, USERINFO,QUERY: |
TUPLE |
stack(INT n, col1, …, colM) |
把M列转换成N行,每行有M/N个字段。其中n必须是个常数 | N行结果 |
hive> select name,id,sub from stu;
小明 01 ["数学","英语","体育"]
小兰 02 ["语文","美术","生物"]
hive> select name,id,explode(sub) from stu;
小明 01 数学
小明 01 英语
小明 01 体育
小兰 02 语文
小兰 02 美术
小兰 02 生物
字符函数
| 命令 | 描述 | 返回值类型 |
|---|---|---|
length(string A) |
统计字符串A的长度。例:select length('length'); = 6 |
INT |
lower(STRING s) 或 lcase(STRING s) |
将字符串中所有字母转换成小写字母。例如: lower(‘hIvE’); = hive |
STRING |
upper(STRING A) 或 ucase(STRING A) |
将字符串中所有字母转换成大写字母。例如: upper(‘hIvE’); = HIVE |
STRING |
reverse(STRING s) |
反转字符串,例:select reverse('reverse'); = esrever |
STRING |
cast( |
将expr转换成type类型的。例如: cast('1' as BIGINT)将会将字符串‘1’转换成BIGINT数值类型。如果转换失败则返回NULL |
指定的 |
trim(STRING s) |
将字符串s 前后出现的空格全部去除掉。例如:trim(' hive '); = "hive" |
STRING |
ltrim(STRING s) |
将字符串s 前面出现的空格全部去除掉。例如:trim(' hive '); = "hive " |
STRING |
rtrim(STRING s) |
将字符串s 后面出现的空格全部去除掉。例如:trim(' hive ');= " hive" |
STRING |
split(STRING s, STRING pattern) |
按照正则表达式pattern分割字符串s,并将分割后的部分以字符串数组的方式返回。例:select split('abtcdtef','t'); = ["ab","cd","ef"] |
ARRAY |
concat(BINARY s1, BINARY s2, …) |
将二进制字节码按次序拼接成一个字符串(Hive 0.12.0版本新增) | STRING |
concat(STRING s1, STRING s2, …) |
将字符串s1,s2等拼接成一个字符串。例如,concat(‘ab’,’cd’); = abcd |
STRING |
concat_ws(分隔字符, STRING s1,STRING s2,…) |
和concat类似,不过是使用指定的分隔符进行拼接的,例:concat_ws(' ', ‘ab’,’cd’); = ab cd |
STRING |
concat_ws(BINARY separator, BINARY s1,STRING s2,…) |
和concat类似,不过是使用指定的分隔符进行拼接的(Hive 0.12.0版本新增) |
STRING |
substr(STRING s, 开始下标, 截取长度) 或 substring(STRING s, 开始下标, 截取长度) |
截取字符串s,从开始位置下标开始截取指定长度字符串,若不指定长度表示截取到最后。例如:substr(‘abcdefgh’,3,2); = cd; substr(‘abcdefg’,5); = efd |
STRING |
substr(BINARY s, 开始下标, 截取长度) 或 substring(BINARY s, 开始下标, 截取长度) |
对于二进制字节值s,从开始位置下标开始截取指定长度字符串,下标从1开始,可为负数,表示倒数第几个(Hive 0.12.0新增) | STRING |
regexp_extract(STRING s, STRING regex_pattern, INT index) |
抽取字符串s中符合正则表达式regex_pattern的第index个分组编号的子字符串 |
STRING |
regexp_replace(STRING s,STRING regex, STRING replacement) |
替换字符串s中符合正则表达式regex的部分,替换成replacement 所指的字符串。例如regexp_replace('hive', '[ie]', 'z'); = hzvz |
STRING |
instr(STRING str, STRING substr) |
查找字符串str中子字符串substr第一次出现的位置下标。例:SELECT instr('bar', 'foobarbar');= 4 |
INT |
locate(STRING substr, STRING str [,INT pos]) |
查找在字符串str中的pos位置后字符串substr第一次出现的位置下标。例:SELECT locate('bar', 'foobarbar', 5); = 7 |
INT |
find_in_set(string str, string strList) |
查找str在strList第一次出现的位置下标,strlist是用逗号分割的字符串。如果没有找该str字符,则返回0。 例:select find_in_set('ab','ef,ab,de'); = 2 |
INT |
in |
例如,test in (val1, val2, …),其表示如果test值等于后面列表中的任一值的话,则返回true |
BOOLEAN |
in_file(STRING s, STRING filename) |
如果文件名为filename的文件中有完整一行数据和字符串s完全匹配的话,则返回true |
BOOLEAN |
lpad(STRING s,INT len,STRING pad) |
填充字符串,从左边开始对字符串s使用字符串pad进行填充,最终达到len长度为止。如果字符串s本身长度比len大的话,那么多余的部分会被去除掉 | STRING |
rpad(STRING s,INT len, STRING pad) |
填充字符串,从右边开始对字符串s使用字符串pad进行填充,最终达到len长度为止。例:select rpad('abc',10,'*'); = abc******* |
STRING |
format_number(NUMBER x,INT d) |
将数值x转换成#,###,###.##格式字符串,并保留d位小数,d可为0,表示不保留小数。例:SELECT format_number(12332.123456, 4); = 12,332.1235 |
STRING |
ascii(STRING s) |
返回字符串s中首个ASCII字符的整数值 | STRING |
base64(BINARY bin) |
将二进制值bin转换成基于64位的字符串(Hive 0.12.0版本新增) | STRING |
unbase64(STRING str) |
将基于64位的字符串str转换成二进制值(Hive 0.12.0版本新增) | BINARY |
binary(STRING s) binary(BINARY b) |
将输入的值转换成二进制值(Hive 0.12.0版本新增) | BINARY |
decode(BINARY bin, STRING charset) |
使用指定的字符集charset将二进制值bin解码成字符串(支持的字符集有:‘US_ASCII’, ‘ISO-8859-1’, ‘UTF-8’, ‘UTF-16BE’, ‘UTF-16LE’, ‘UTF-16’) |
STRING |
encode(STRING src, STRING charset) |
使用指定的字符集charset将字符串src编码成二进制值, 如果任一输入参数为NULL,则结果为NULL(Hive 0.12.0版本新增) |
BINARY |
get_json_object (STRING json_string, STRING path) |
从给定路径上的JSON字符串中抽取出JSON对象,并返回这个对象的JSOM字符串形式。如果输入的JSON字符串是非法的,则返回NULL | STRING |
ngrams(ARRAY |
估算文件中前K个字尾。pf是精度系数 | ARRAY |
context_ngrams(array |
和ngrams类似,但是从每个外层数组的第二个单词数组来查找前K个字尾 | ARRAY |
parse_url(STRING url,STRING partname [,STRING key]) |
从URL中抽取指定部分的内容。参数partname表示要抽取的部分名称,大小写敏感,可选的值有:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY: |
STRING |
printf(STRING format, Obj … args) |
按照printf风格格式化输出输入的字符串(Hive 0.9.0版本新增) | STRING |
repeat(STRING s,INT n) |
重复输出n次字符串s | STRING |
sentences(STRING s,STRING lang,STRING locale) |
将输入字符串s转换成句子数组,每个句子又由一个单词数组构成。参数lang和locale是可选的,如果没有使用的,则使用默认的本地化信息 | ARRAY |
size(MAP |
返回MAP中元素的个数 | INT |
size(ARRAY |
返回数组ARRAY的元素个数 | INT |
space(INT n) |
返回n个空格 | STRING |
str_to_map (STRING s,STRING delim1, STRING delim2) |
将字符串s按照指定分隔符转换成Map,第一个参数是输入的字符串,第二个参数是键值对之间的分隔符,第三个分隔符是键和值之间的分隔符 | MAP |
> select parse_url('https://blog.csdn.net/weixin_45303361/?articleId=104381607', 'HOST');
+--------------+--+
| _c0 |
+--------------+--+
| blog.csdn.net |
+--------------+--+
> select parse_url('https://blog.csdn.net/weixin_45303361/?articleId=104381607', 'QUERY', 'articleId');
+------+--+
| _c0 |
+------+--+
| 104381607 |
+------+--+
hive> select get_json_object('{"store":
{"fruit":\[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}],
"bicycle":{"price":19.95,"color":"red"}
},
"email":"amy@only_for_json_udf_test.net",
"owner":"amy"
}
','$.owner')
+------+--+
| _c0 |
+------+--+
| amy |
+------+--+
时间函数
| 命令 | 描述 | 返回值类型 |
|---|---|---|
from_unixtime(BIGINT unixtime [,STRING format]) |
将时间戳秒数转换成UTC时间,并用字符串表示,format可选来指定输出的时间格式,例:yyyyMMdd |
STRING |
unix_timestamp() |
获取当前本地时区下的当前时间戳 | BIGINT |
unix_timestamp(STRING date) |
输入的时间字符串格式必须是yyyy-MM-dd HH:mm:ss,如果不符合则返回0,如果符合则将字符串时间转换成Unix时间戳。例如:unix_timestamp('2009- 03-20 11:30:01') 为:1237573801 |
BIGINT |
unix_timestamp(STRING date, STRING pattern) |
将指定时间字符串格式字符串转换成Unix时间戳,如果格式不对则返回0。例如:unix_timestamp('2009-03-20', 'yyyy-MM-dd') = 1237532400 |
BIGINT |
to_date(STRING timestamp) |
返回时间字符串的日期部分,例如:to_ date("1970-01-01 00:00:00") = "1970-01-01" |
STRING |
year(STRING date) |
返回时间字符串中的年份并使用INT类型表示。例如:year("1970-01-01 00:00:00") = 1970, year(“1970-01-01”) = 1970 |
INT |
month(STRING date) |
返回时间字符串中的月份并使用INT类型表示。例如: month("1970-11-01 00:00:00") = 11, month("1970-11-01") = 11 |
INT |
day(STRING date) dayofmonth(STRING date) |
返回时间字符串中的天并使用INT类型表示。例如:day("1970-11-01 00:00:00") = 1, day("1970-11-01") = 1 |
INT |
hour(STRING date) |
返回时间戳字符串中的小时并使用INT类型表示。例如:hour('2009-07-30 12:58:59') = 12, hour('12:58:59') = 12 |
INT |
minute(STRING date) |
返回时间字符串中的分钟数 | INT |
second(STRING date) |
返回时间字符串中的秒数 | INT |
weekofyear(STRING date) |
返回时间字符串位于一年中第几个周内。例如:weekofyear("1970-11-01 00:00:00") = 44, weekofyear("1970-11-01") = 44 |
INT |
datediff(STRING enddate, STRING startdate) |
日期比较函数,计算开始时间startdata到结束时间enddata相差的天数。例如: datediff('2009-03-01', '2009-02-27') = 2 |
INT |
date_add(STRING startdate, INT days) |
日期增加,为开始时间startdata增加days天。例如:date_add('2008-12-31', 1) = '2009-01-01' |
STRING |
date_sub(STRING startdate, INT days) |
日期减少,从开始时间startdata中减去days天。例如:date_sub('2008-12-31', 1) = ' 2008-12-30' |
STRING |
last_day(string date) |
返回日期date月份的最后一天。例:select last_day('2018-12-26'); = 2018-12-31 |
STRING |
next_day(string start_date, string day_of_week) |
返回日期start_date下周的指定周几。例:·select next_day(‘2019-02-24’, ‘TU’); = 2019-02-26|STRING` |
|
trunc(string date, string format) |
返回日期date月份的第一天/年中的第一天日期。支持格式:MONTH/MON/MM, YEAR/YYYY/YY,例:select trunc('2019-02-24', 'YYYY'); = 2019-01-01 |
string |
add_months(string start_date, int num_months, output_date_format) |
按指定格式返回指定日期增加几个月后的日期。例:select add_months('2019-02-24 21:15:16', 2, 'YYYY-MM-dd HH:mm:ss'); = 2019-04-24 21:15:16 |
string |
date_format(date/timestamp/string, fmt) |
返回日期指定的格式。例:select date_format('2018-12-26', 'y'); = 2018 |
string |
自定义函数
UDF: 用户自定义函数(user-defined function)
相当于mapper,对每一条输入数据,映射为一条输出数据UDAF: 用户自定义聚合函数 (user-defined aggregation function)
相当于reducer,做聚合操作,把一组输入数据映射为一条(或多条)输出数据。
一个脚本至于是做mapper还是做reducer,又或者是做UDF还是做UDAF,取决于我们把它放在什么样的hive操作符中。放在select中的基本就是UDF,放在distribute by和cluster by中的就是UDAF。
jar包 UDF
在hdfs中创建 /user/hive/lib目录
hadoop fs -mkdir /user/hive/lib
把 hive目录下 lib/hive-contrib-2.3.4.jar 放到hdfs中
hadoop fs -put hive-contrib-2.3.4.jar /user/hive/lib/
把集群中jar包的位置添加到hive中
hive> add jar hdfs:///user/hive/lib/hive-contrib-2.3.4.jar ;
在hive中创建临时UDF
hive> CREATE TEMPORARY FUNCTION row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence'
在之前的案例中使用临时自定义函数(函数功能: 添加自增长的行号)
Select row_sequence(),* from employee;
创建非临时自定义函数
CREATE FUNCTION row_sequence as 'org.apache.hadoop.hive.contrib.udf.UDFRowSequence'
using jar 'hdfs:///user/hive/lib/hive-contrib-2.3.4.jar';
Python UDF
编写map风格脚本
import sys
for line in sys.stdin:
line = line.strip()
fname , lname = line.split('\t')
l_name = lname.upper()
print('\t'.join([fname, str(l_name)]))
通过hdfs向hive中ADD file
加载文件到hdfs
hadoop fs -put udf.py /user/hive/lib/
hive从hdfs中加载python脚本
ADD FILE '远程文件';
ADD FILE '本地文件';
Transform恒等变换,使用python脚本
SELECT TRANSFORM(fname, lname) USING 'python xxx.py' AS (fname, l_name) FROM u;
where条件区 支持的运算符
比较运算符
| 操作 | 格式 | 例子 | 含义 |
|---|---|---|---|
| 等于 | = |
select age from heros where id=1 |
查看id为1的英雄的age数据 |
| 大于 | > |
update heros set is_delete=1 where age>18 |
逻辑删除age大于18的英雄数据 |
| 大于等于 | >= |
delete from heros where height>=180 |
物理删除height大于等于180的英雄数据 |
| 小于 | < |
update heros set age=18 where age<18 |
将所有age小于18的英雄age数据改为18 |
| 小于等于 | <= |
select height,gender from heros where age<=18 |
查看所有age小于等于18的英雄的height和gender数据 |
| 不等于 | !=或 <> |
select * from heros where name!="关羽" |
查看name不是关羽的所有英雄的所有字段数据 |
逻辑运算符
格式:where 条件1 (not/and/or) 条件2
| 操作 | 例子 | 含义 |
|---|---|---|
| and | where age> 30 and gender="男" |
筛选年龄大于30的男性 |
| or | where id < 4 or is_delete=0 |
筛选编号小于4或没被逻辑删除的记录 |
| not | where not (age >= 10 and age <= 15) |
年龄不在10岁到15岁之间的记录 |
注意:
and表示条件都满足,or表示条件满足其一,not表示取反- 若是多逻辑运算最好添加
括号()
模糊筛选
格式:where 指定字段名 like "模糊条件"
含义:对指定字段进行模糊筛选,其中like为模糊查询关键字
| 操作 | 含义 | 例子 | 表示 |
|---|---|---|---|
% |
任意多个任意字符 | where name like '%明%' |
名字中带明字的记录 |
_ |
一个任意字符 | where name like '李_' |
以李姓开始并且名字仅有两字的记录 |
例:
# 查询姓黄或叫某靖的学生:
select * from students where name like '黄%' or name like '_靖';
where 指定字段名 not like "模糊条件" 表示查询不满足模糊条件的数据
# 查询不姓黄的学生:
select * from students where name not like '黄%';
范围筛选
| 操作 | 含义 | 例子 | 表示 |
|---|---|---|---|
where 字段名 between 下限 and 上限 |
表示在一个连续的范围内查询 | where id between 3 and 8' |
编号为3到8之间的记录 |
where 字段 in(值1,值2,值3,……) |
表示在一个非连续的范围内查询 | where id in (3, 9, 18)' |
编号为3或9或18的记录 |
注意:
where 字段名 between 下限 and 上限包含上下限
判空筛选
| 操作 | 含义 | 例子 | 表示 |
|---|---|---|---|
is null |
字段为空 | where height is null |
身高为空的记录 |
not is null |
字段不为空 | where height not is null |
身高不为空的记录 |
注意:
- 不能使用
where height = null和where height != null判断是否为空 - 不能使用
where height is not null判断不为空 null不等于''空字符串(空字符串:已经分配了存储空间,但是没有存储东西;NULL:没有分配存储空间)
高级查询
复杂查询语句,的执行顺序:
From --> where --> group by --> having --> select --> order by
排序(ORDER BY 和 SORT BY)
格式:select 需查询的字段 from 表名 order/sort by 排序字段1 asc/desc ,排序字段2 asc/desc,...
注意:
order by表示全局排序,会有一个所有的数据都通过一个reducer进行处理的过程。对于大数据集,这个过程可能会消耗太过漫长的时间来执行sort by表示局部排序,保证每个reducer的输出数据都是有序的(但并非全局有序)。这样可以提高后面进行的全局排序的效率asc表示升序,desc表示降序,默认升序- 先按照排序字段1进行排序,如果字段1的值相同时,方才按照 排列字段2 进行排序排序,以此类推
- 若排到最后一个字段顺序依旧一致,就会按照物理插入时间排(包含不填写排序字段1和没有
order by) - 字符串的排序中:
"12"在"2"之前
查询未删除男生信息,按身高升序后学号降序排列:
select * from students where gender=1 and is_delete=0 order by height asc,id desc;
CLUSTER BY、DISTRIBUTE BY、SORT BY
Hive提供了语法来控制数据是如何被分发和排序的。这些功能可以应用在大多数的查询中,不过在执行streaming处理时显得特别有用
例如,具有相同键的数据需要分发到同一个处理节点上,或者数据需要按照指定列或指定函数进行排序。Hive提供了多种方式来控制这种行为。
第1种控制这种行为的方法就是CLUSTER BY语句,其可以确保类似的数据可以分发到同一个reduce task中,而且保证数据是有序的。
为了演示CLUSTER BY的用法,让我们来看一个特殊的例子:使用到TRANSFORM功能和2个Python脚本,一个脚本用于将读取的文本的每行内容分割成单词;另一个脚本用于接受字频数据流以及单词的中间计数值(大多数是数字“1”),然后对每个单词的词频求和汇总。
下面是第1个Python脚本,其可以按照空格将每行内容分割成单词(按空格划分对于标点符号等可能不太合适):
import sys
for line in sys.stdin:
words = line.strip().split()
for word in words:
print "%s\t1" % (word.lower())
Python脚本的输出词组使用CLUSTER BY
执行结果:
word1 1
word1 1
word1 1
word2 1
word3 1
word3 1
第2个Python脚本将会更复杂些,因为其需要缓存当前处理的单词,以及迄今为止这个单词出现的次数。当处理下一个单词时,这个脚本需要输出上一个单词的词频数,然后重置缓存。
下面就是第2个Python脚本:
import sys
(last_key, last_count) = (None, 0)
for line in sys.stdin:
(key, count) = line.strip().split("\t")
if last_key and last_key != key:
print "%s\t%d" % (last_key, last_count)
(last_key, last_count) = (key, int(count))
else:
last_key = key
last_count += int(count)
if last_key:
print "%s\t%d" % (last_key, last_count)
我们将假设这2个Python脚本都在用户根目录下。
最后,我们来看下2个脚本结合使用的Hive查询语句。首先,我们通过CREATE TABLE语句创建一个输入表,表内容包含多行的文本数据。这个表我们在第1章使用过。任意文本文件都可以作为这张表的数据。其 次,创建的表word_count用于保存计算后的输出结果。其有2个字段,一个是word(表示单词),一个是count(表示次数)。同时字段分隔符是\t。最后就是结合使用这2个脚本进行处理的TRANSFORM语句了:
hive> CREATE TABLE docs (line STRING);
hive> CREATE TABLE word_count (word STRING, count INT)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
hive> FROM (
> FROM docs
> SELECT TRANSFORM (line) USING '${env:HOME}/mapper.py'
> AS word, count
> CLUSTER BY word) wc
> INSERT OVERWRITE TABLE word_count
> SELECT TRANSFORM (wc.word, wc.count) USING '${env:HOME}/reducer.py'
> AS word, count;
USING语句指定了Python脚本所在的绝对路径。
替代CLUSTER BY的最方便的方式就是使用DISTRIBUTE BY和SORT BY。使用它们的常见场景就是,用户期望将数据按照某个字段划分,然后按照另一个字段排序。实际上,CLUSTER BY word等价于DISTRIBUTE BY word SORT BY word ASC
如下TRANSFORM查询的字频输出结果是按照降序排序的:
FROM (
FROM docs
SELECT TRANSFORM (line) USING '/.../mapper.py'
AS word, count
DISTRIBUTE BY word SORT BY word DESC) wc
INSERT OVERWRITE TABLE word_count
SELECT TRANSFORM (wc.word, wc.count) USING '/.../reducer.py'
AS word, count;
使用CLUSTER BY或者使用结合SORT BY的DISTRIBUTE BY是非常重要的。因为如果没有这些指示,Hive可能无法合理地并行执行job,所有的数据可能都会分发到同一个reducer上,这样就会导致整体job执行时间延长。
分页(limit)
格式:select 需查看的字段 from 表名 limit 开始索引,每页条数
# 已知每页显示m条数据,获取第n页数据的SQL语句:
select * from 数据库名 limit (n-1)*m,m
# 获取第一页数据的SQL语句简写
select * from students where gender=1 limit m;
注意:
- 若开始索引不填写,默认为0
起别名(as)
-
使用
as给字段起别名
在SQL语句显示结果的时候,使屏幕显示的字段名具备良好的可读性select id as 序号, name as 名字, gender as 性别 from students; -
可以通过 as 给表起别名
select s.id,s.name,s.gender from students as s;多用于连表查询,尤其是自查询,用于区分两个表 并且 缩短表名减少击键次数
注意:
as关键字起别名,仅仅是用于方便查询和增加显示可读性,并不对 表(包括:表名、字段名和数据)进行任何修改as关键字可以省略,但为增加可读性不建议省略
去重(distinct)
distinct可以去除重复数据行
格式:select distinct 字段1,字段2... from 表名;
# 例:查询班级中学生的性别
select name, gender from students;
注意:
distinct关键字必须放在所有字段之前- 去除的是:
distinct关键字后所有字段都重复的数据,部分字段值重复不会被去掉
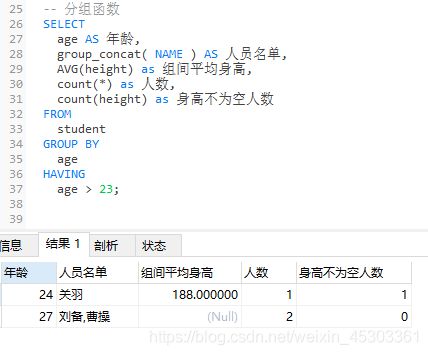
分组查询(group by)
作用:将查询结果按照指定字段进行分组,把相同的分组字段值连接起来
格式:GROUP BY 指定字段名,字段2 [HAVING 条件表达式] [WITH ROLLUP]
HAVING 条件表达式: 用来过滤分组后的数据WITH ROLLUP:表示在进行分组统计的基础上再次进行汇总统计
注意:当分完组,某一字段包含多个分组结果时,则必须配合group_concat(字段)函数,否则报错
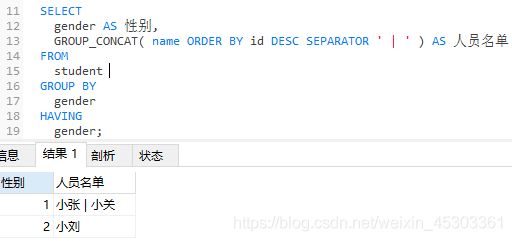
group_concat()中可以排序(order by)SEPARATOR '|'表示分隔符为|
分组查询配合聚合函数使用
使用with rollup进行汇总

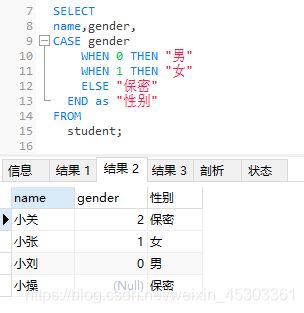
case表达式
格式一
CASE 字段
WHEN 常量1 THEN
语句段1
WHEN 常量2 THEN
语句段2
......
WHEN 常量n THEN
语句段n
[ELSE 语句段n+1]
END;
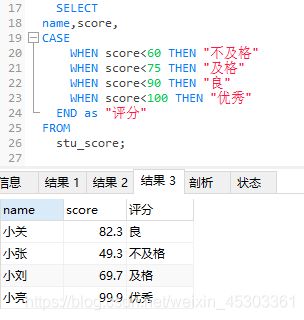
格式二
CASE
WHEN 条件表达式1 THEN
语句段1
WHEN 条件表达式2 THEN
语句段2
......
WHEN 条件表达式n THEN
语句段n
[ELSE 语句段n+1]
END;`
格式一案例:
格式二案例:
hive> SELECT name, salary,
> CASE
> WHEN salary < 50000.0 THEN 'low'
> WHEN salary >= 50000.0 AND salary < 70000.0 THEN 'middle'
> WHEN salary >= 70000.0 AND salary < 100000.0 THEN 'high'
> ELSE 'very high'
> END AS bracket FROM employees;
John Doe 100000.0 very high
Mary Smith 80000.0 high
Todd Jones 70000.0 high
Bill King 60 000.0 middle
Boss Man 200000.0 very high
Fred Finance 150000.0 very high
Stacy Accountant 60000.0 middle
...
联表查询
内连接

内连接(INNER JOIN)中,只有进行连接的两个表中都存在与连接标准相匹配的数据才会被保留下来
格式:select 字段 from 表1 join 表2 on 连接条件
其中:
join是内连接查询关键字on 连接条件基本为:on 表1.字段1 = 表2.字段2- 连表查询多用
as 别名另命名,用于减少击键次数 - 多表联表时尽量将大的表放在后面
hive> SELECT a.ymd, a.price_close, b.price_close , c.price_close
> FROM stocks a JOIN stocks b ON a.ymd = b.ymd
> JOIN stocks c ON a.ymd = c.ymd
> WHERE a.symbol = 'AAPL' AND b.symbol = 'IBM' AND c.symbol = 'GE';
2010-01-04 214.01 132.45 15.45
2010-01-05 214.38 130.85 15.53
2010-01-06 210.97 130.0 15.45
2010-01-07 210.58 129.55 16.25
2010-01-08 211.98 130.85 16.6
2010-01-11 210.11 129.48 16.76
...
大多数情况下,Hive会对每对JOIN连接对象启动一个MapReduce任务
本例中,会首先启动一个MapReduce job对表a和表b进行连接操作,然后会再启动一个MapReduce job将第一个MapReduce job的输出和表c进行连接操作
左外连接 (LEFT OUTER JOIN)
以左表为主,根据连接条件 添加右表数据,若右表数据不存在,则使用null值填充
左外连接查询效果图:

hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM stocks s LEFT OUTER JOIN dividends d ON s.ymd = d.ymd AND s.symbol = d.symbol
> WHERE s.symbol = 'AAPL';
...
1987-05-01 AAPL 80.0 NULL
1987-05-04 AAPL 79.75 NULL
1987-05-08 AAPL 79.0 NULL
1987-05-11 AAPL 77.0 0.015
1987-05-18 AAPL 75.75 NULL
...
右外连接(RIGHT OUTER JOIN)
以右表为主,根据连接条件 添加左表数据,若左表数据不存在,则使用null值填充
右外连接查询效果图:

hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM dividends d RIGHT OUTER JOIN stocks s ON d.ymd = s.ymd AND d.symbol = s.symbol
> WHERE s.symbol = 'AAPL';
...
1987-05-07 AAPL 80.25 NULL
1987-05-08 AAPL 79.0 NULL
1987-05-11 AAPL 77.0 0.015
1987-05-12 AAPL 75.5 NULL
1987-05-13 AAPL 78.5 NULL
...
完全外连接(FULL OUTER JOIN)
将会返回所有表中符合WHERE语句条件的所有记录
如果任一表的指定字段没有符合条件的值的话,那么就使用NULL值替代
hive> SELECT s.ymd, s.symbol, s.price_close, d.dividend
> FROM dividends d FULL OUTER JOIN stocks s ON d.ymd = s.ymd AND d.symbol = s.symbol
> WHERE s.symbol = 'AAPL';
...
1987-05-07 AAPL 80.25 NULL
1987-05-08 AAPL 79.0 NULL
1987-05-11 AAPL 77.0 0.015
1987-05-12 AAPL 75.5 NULL
1987-05-13 AAPL 78.5 NULL
...
合并表(UNION ALL)
UNION ALL可以将2个或多个表进行合并。
每一个union子查询都必需具有相同的列,而且对应的每个字段的字段类型必须是一致的
例如,如果第2个字段是FLOAT类型的,那么所有其他子查询的第2个字段必须都是FLOAT类型的。
下面是个将日志数据进行合并的例子:
SELECT log.ymd, log.level, log.message
FROM (
SELECT l1.ymd, l1.level,
l1.message, 'Log1' AS source
FROM log1 l1
UNION ALL
SELECT l2.ymd, l2.level,
l2.message, 'Log2' AS source
FROM log1 l2
) log
SORT BY log.ymd ASC;
HiveQL 数据的加载和导出
加载数据
Hive没有行级别的数据插入、数据更新和删除操作,那么往表中装载数据的唯一途径就是使用一种“大量”的数据装载操作。或者通过其他方式仅仅将文件写入到正确的目录下
格式:``
LOAD DATA LOCAL INPATH '${env:HOME}/california-employees` 载有数据的文件目录路径
OVERWRITE INTO TABLE employees 表名
PARTITION (country = 'US', state = 'CA'); 分区
- 若使用了
LOCAL关键字,则该路径为本地文件系统路径。数据将是拷贝到目标位置
若不使用LOCAL关键字,则该路径是同一分布式文件系统的路径。数据将是从这个路径转移到目标位置的 - 若使用了
OVERWRITE关键字,则目标文件夹中之前存在的数据将会被先删除掉
若不使用OVERWRITE关键字,则会把新增的文件增加到目标文件夹中而不会删除之前的数据,但若目标文件夹中已经存在和装载的文件同名的文件,那么新加载的同名文件将会重命名为“文件名_序列号”(hive 0.9 之前为覆盖同名文件) - 若目标表是非分区表,那么语句中应该省略
PARTITION子句 - 通常情况下指定的路径应该是一个目录,而不是单个独立的文件
- 若分区目录不存在,该命令会先创建分区目录,然后再将数据拷贝到该目录下
通过查询语句向表中追加数据
INSERT INTO TABLE employees
PARTITION (country = 'US', state = 'OR')
SELECT * FROM staged_employees se
WHERE se.cnty = 'US' AND se.st = 'OR';
若使用OVERWRITE关键字替换掉INTO关键字,那么Hive将会以追加的方式写入数据而不会覆盖掉之前已经存在的内容。这个功能只有Hive v0.8.0版本以及之后的版本中才有。
若用户需要对65个州都执行这些语句,那么也就意味这需要扫描staged_employees表65次
Hive提供了另一种INSERT语法,可以只扫描一次输入数据,然后按多种方式进行划分:
FROM staged_employees se
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'OR')
SELECT * WHERE se.cnty = 'US' AND se.st = 'OR'
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'CA')
SELECT * WHERE se.cnty = 'US' AND se.st = 'CA'
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state = 'IL')
SELECT * WHERE se.cnty = 'US' AND se.st = 'IL';
若分区很多,那么用户就需要写非常长的HQL!不过幸运的是,Hive提供了一个动态分区功能
动态分区插入
基于查询参数推断出需要创建的分区名称
格式:
INSERT OVERWRITE TABLE 表名
PARTITION (country, state) 仅分区名,不添加值,添加后是静态分区插入
SELECT ..., a.cnty, a.st
FROM 源表名 a;
Hive根据SELECT语句中最后2列来确定分区字段country和state
分区字段是根据位置而不是根据命名来匹配
用可以混合使用动态和静态分区
如下这个例子中指定了country字段的值为静态的US,而分区字段state是动态值:
INSERT OVERWRITE TABLE employees
PARTITION (country = 'US', state)
SELECT ..., se.cnty, se.st
FROM staged_employees se
WHERE se.cnty = 'US';
静态分区键必须出现在动态分区键之前
开启动态分区
动态分区功能默认情况下没有开启
开启后,默认是以“严格”模式执行的,在这种模式下要求至少有一列分区字段是静态的
这有助于阻止因设计错误导致查询产生大量的分区。例如,用户可能错误地使用时间戳作为分区字段,然后导致每秒都对应一个分区!而用户也许是期望按照天或者按照小时进行划分的
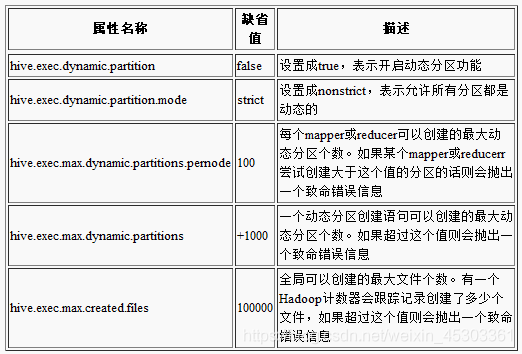
hive> set hive.exec.dynamic.partition=true;
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> set hive.exec.max.dynamic.parti tions.pernode=1000
导出数据
如果数据文件恰好是用户需要的格式,那么只需要简单地拷贝文件夹或者文件就可以了:
从hadoop 到 hadoop
hadoop fs -cp 源路径 目标路径
从hadoop 到 本地
hadoop fs -get 原路径 目标路径
否则,用户可以使用INSERT … DIRECTORY …
如下面例子所示:
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/ca_employees'
SELECT name, salary, address
FROM employees
WHERE se.state = 'CA';
关键字OVERWRITE和LOCAL和加载是一致
指定的路径也可以写成全URL路径(例如,hdfs://master-server/tmp/ca_employees)。
不管在源表中数据实际是怎么存储的,Hive会将所有的字段序列化成字符串写入到文件中。Hive使用和Hive内部存储的表相同的编码方式来生成输出文件。
和向表中插入数据一样,用户也是可以通过如下方式指定多个输出文件夹目录的:
FROM staged_employees se
INSERT OVERWRITE DIRECTORY '/tmp/or_employees'
SELECT * WHERE se.cty = 'US' and se.st = 'OR'
INSERT OVERWRITE DIRECTORY '/tmp/ca_employees'
SELECT * WHERE se.cty = 'US' and se.st = 'CA'
INSERT OVERWRITE DIRECTORY '/tmp/il_employees'
SELECT * WHERE se.cty = 'US' and se.st = 'IL';
表的字段分隔符可能是需要考量的。例如,如果其使用的是默认的^A分隔符,而用户又经常导出数据的话,那么可能使用逗号或者制表键作为分隔符会更合适。
Hive数据模型 对应 HDFS的存储位置
db数据库:在hdfs中表现为hive.metastore.warehouse.dir目录下一个文件夹table内部表:在hdfs中表现所属db目录下一个文件夹external table外部表:数据存放位置可以在HDFS任意指定路partition分区:在·hdfs中表现为table目录下的子目录