NLP --- 文本分类(基于LDA的隐语意分析详解)
前几节我们分析了向量空间模型(VSM)、基于奇异值分解(SVD)的潜语意分析(LSA)、基于概率的潜语意分析(PLSA)这些模型都是为了解决文本分类问题,他们各自有自己的优点和缺点,其中VSM模型简单方便但是容易造成维度爆炸和计算量慢的缺点,LSA是基于矩阵分解的原理进行分析的,优点是对VSM有效的降维,但是计算量还是很大,因此引入了PLSA,该优点是完全避开了PSA的矩阵分解的计算问题,把其完全转变为概率问题,通过EM算法进行求解问题,但是该算法的缺点是假设太过牵强,建模比较粗糙,统计理论基础不足,没有考虑在NLP中语料稀疏的情况,EM算法迭代计算繁琐,计算量大,因此还需要继续寻找更好的模型,这时LDA(Latent Dirichlet Allocation)应运而生,这个算法更精密优雅,但又不容易理解的模型LDA(Latent Dirichlet Allocation),LDA可以说是统计理论大观园,需要有较好的概率统计基础才可以理解,好下面我们就看看他是如何解决问题的,这里我想了很久怎么写这篇文章,本人这里为了能让大家理解LDA的工作过程,本节主要使用语言描述型和少量公式进行讲解,先让大家从整体上去把握这个算法,然后我们在一起去推倒公式,如果整体性不清晰,很容易晕的,本人刚开始学习的时候就在这里晕了两三天,因此我会考虑当时我理解的过程进行讲解,这里的讲解,会使用到前面大量的使用过的术语,例如矩阵的奇异值分解后得到两个矩阵的情况(下图),第一个矩阵的行是item(主题、电影、单词),列是隐分类或是topic或者抽象的特征等等称号,第二个矩阵的行是隐分类或是topic或者抽象的特征等等称号,列就是user(用户、document等等),这里大家对前面的知识点应该有一个清晰的认识,因为他们都是递进关系,就是为了解决前一个算法的缺点才会引入更好的算法,这也是我一直在强调的学习算法时尽量去搞懂算法的来历和发展历史,这样我们才能对这个系列的算法有一个清晰的认识,以后遇到问题才能根据问题的特点,想到类似的解决方案,下面给出对应的矩阵分解的示意图,不懂请看我前面的文章。好,废话不多说,这里开始我们今天的内容,这里大家一定要耐着性子看,因为我感觉他的难度和支持向量机是同一个级别了。

LDA(Latent Dirichlet Allocation)
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从Dirichlet分布,主题到词服从Dirichlet分布。LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
对于语料库中的每篇文档,LDA定义了如下生成过程(generative process):
1.对每一篇文档,从主题分布中抽取一个主题;
2.从上述被抽到的主题所对应的单词分布中抽取一个单词;
3.重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomial distribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ.
上面是简单的百度百科的解释,下面我们将从头开始介绍什么是LDA:
Beta分布和Dirichlet 分布
这里推荐大家看看《LDA数学八卦》这篇文章的0.3部分的背景知识,这里我就不讲背景了,直接给出结果,大家需要找到这篇文章结合学习:
Beta分布
这里简单的讲一下背景,详细请参考文档,游戏的规则很简单,我有一个魔盒,上面有一个按钮,你每按一下按钮,就均匀的输出一个[0,1]之间的随机数,我现在按10下,我手上有10个数,你猜第7大的数是什么,偏离不超过0.01就算对。”你应该怎么猜呢?


使用概率进行对其描述为事件E:

得到事件E的概率:
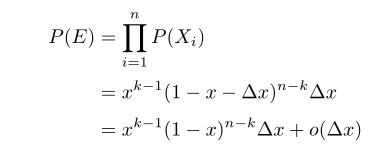
现在我们进行对其进行扩展,就是说,如果有n个数落进了![]() ,那么对应的概率密度函数为如下:
,那么对应的概率密度函数为如下:
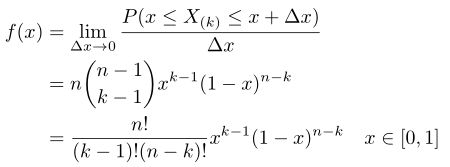
这就是对应的n个数落进了![]() 的概率密度,具体推倒请看文档,上面的形式我们觉得很复杂了,而且分子分母都是阶乘的形式,因此这里我们可以使用Gamma进行代替,这里大家可以这样简单的理解一下Gamma函数,gamma函数是阶乘的延续,如果输入的是整数,则返回的该数的阶乘,如果输入的不是整数,返回的是复杂的和阶乘相关的数。这里不细讲了,有兴趣的同学建议看看那篇文章的前一部分,下面直接给出,大家可以直接接受即可(和我们接受均匀分布、正态分布一样接受他即可):
的概率密度,具体推倒请看文档,上面的形式我们觉得很复杂了,而且分子分母都是阶乘的形式,因此这里我们可以使用Gamma进行代替,这里大家可以这样简单的理解一下Gamma函数,gamma函数是阶乘的延续,如果输入的是整数,则返回的该数的阶乘,如果输入的不是整数,返回的是复杂的和阶乘相关的数。这里不细讲了,有兴趣的同学建议看看那篇文章的前一部分,下面直接给出,大家可以直接接受即可(和我们接受均匀分布、正态分布一样接受他即可):

这里感觉还是麻烦,因为参数的形式不一样,这里继续简化,这里去![]() ,代入上式得:
,代入上式得:
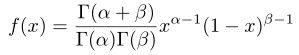
这就是Beta分布了,那么这个分布有什么物理意义呢?这里通过例子进行解释一下:
这里举一个两点分布的例子即掷硬币的,这里的硬币不是均匀的,正面可能的概率是0.4,反面为0.6,我不知道硬币的这个参数即概率,我试图通过试验去找出这个参数,根据大数定律,当我掷1万次时,如果出现4000次的正面,6000次的反面就说明我们的参数正面是0.4,反面是0.6,但是现在的问题,因为某些原因,你无法做那么多的试验,只能做10次试验,即你只能掷10次硬币,这个时候如果出现4次反面和6次正面,你敢说这个硬币的概率正面是0.4,反面为0.6吗?不敢的,因为试验次数太少,这时怎么办呢?这时候,我们假设硬币的两点的概率P是服从Beta分布即服从上式,这里大家需要注意的是服从Beta分布的是概率P,不是其他,就是我们要求的正反两面的概率P, 上式的参数![]() 是给定的参数,这里我们假如n=10,其中k=7,则
是给定的参数,这里我们假如n=10,其中k=7,则![]() ,
,![]() ,那么我通过试验的正面是0.4的概率代入上式计算,硬币正面是0.4的概率有多大:
,那么我通过试验的正面是0.4的概率代入上式计算,硬币正面是0.4的概率有多大:
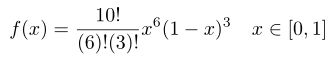
这样我就能计算试验10次的结果出现4次正面的概率为0.4的概率有多大了,上式的结果就是说明硬币的概率参数P取值0.4的概率是多少,这里大家必须得理解。
好,到这里大家有没有疑问呢?就是我的 ![]() 为什么是取值是7和4呢,这里呢就和Beta分布的共轭性质有关即Beta-Binomial 共轭性。
为什么是取值是7和4呢,这里呢就和Beta分布的共轭性质有关即Beta-Binomial 共轭性。
这里需要给大家再次强调一下什么是Beta分布,Beta分布的变量是概率P,如上面的例子,即在试验次数较少的情况下,得到的硬币概率P(这里指根据统计得到的值,如上面投掷10次,4次正面 ,说明正面的概率为0.4),那么得到的这个P是真实的P的概率是服从Beta分布的,也就是说Beta分布的变量是概率P,即可以写成Beta(P)或者这样写![]() ,这里大家把这个和正态分布的写法对比一下即
,这里大家把这个和正态分布的写法对比一下即![]() ,这样大家应该理解我一直在强调的什么意思了,其中P是Beta分布的变量,
,这样大家应该理解我一直在强调的什么意思了,其中P是Beta分布的变量,![]() 是先验的试验为了描述方便,我们合起来写即:
是先验的试验为了描述方便,我们合起来写即:
![]()
这里的p就是我们猜测的概率,或者说我们初次得到的概率,也叫做先验概率,那么我们现在的试验是符合二项分布的,那么这里就有一个性质了即:

其中![]() 就是试验分别出现的次数,如硬币正反面的次数,
就是试验分别出现的次数,如硬币正反面的次数,![]() 对应的就是正反面出现的次数,上面的式子就是Beta-Binomial共轭了,那么这代表什么呢?
对应的就是正反面出现的次数,上面的式子就是Beta-Binomial共轭了,那么这代表什么呢?
假如现在有一个硬币我们不知道他的分布特性即正反两面的概率,现在我先给定一个先验概率,这个概率是服从Beta分布的,那么我使用这个硬币进行实验,分别记录出现正反面的次数![]() ,那么得到的新的分布依然符合Beta分布的,这样有什么好处呢?其实我们的给出的先验是服从Beta分布的,那么再加上物理的试验过程使其得到的分布依然服从Beta分布,只不过里面的
,那么得到的新的分布依然符合Beta分布的,这样有什么好处呢?其实我们的给出的先验是服从Beta分布的,那么再加上物理的试验过程使其得到的分布依然服从Beta分布,只不过里面的![]() 会根据物理试验进行变化,但是始终符合Beta分布,这样话我们就容易分析了,因为分布模型不变,分析手段就是一样的,如果先验分布是其他的分布,再加上物理试验得到不确定的分布我们怎么分析呢?这就是使用Beta分布的原因。这里还是具体的举个例子吧,假如我们掷硬币,假如出现正反的次数都为1,先验的概率为0.5,此时
会根据物理试验进行变化,但是始终符合Beta分布,这样话我们就容易分析了,因为分布模型不变,分析手段就是一样的,如果先验分布是其他的分布,再加上物理试验得到不确定的分布我们怎么分析呢?这就是使用Beta分布的原因。这里还是具体的举个例子吧,假如我们掷硬币,假如出现正反的次数都为1,先验的概率为0.5,此时![]() ,
,![]() ,那么我们
,那么我们
我们做试验,记录正反面的次数,这里按照上面的例子加入![]() ,那么我们带进上式得到:
,那么我们带进上式得到:
![]()
这样就会得到分布p=0.5的概率![]() ,这样如果我们,简单来说,就是如果我们的先验概率不准确,但是我们可以根据我们的试验去不断的纠正,使概率
,这样如果我们,简单来说,就是如果我们的先验概率不准确,但是我们可以根据我们的试验去不断的纠正,使概率![]() 可能性越小,这样我们找到一个概率
可能性越小,这样我们找到一个概率![]() 使的Beta分布得概率最大,即
使的Beta分布得概率最大,即![]() ,如下图所示:
,如下图所示:

这里大家应该能明白吧,不明的我也没办法了,私聊我吧,这里在说一下为什么要选用Beta分布的原因,其本质原因是,Beta分布和两点分布是共轭的,即先验概率和物理试验过程结合后还是符合这个Beta分布的,这里大家需要理解,下面我们继续,我们知道这里的p是二值函数(即硬币只有正反两个值称为二值)的,那如果是多值函数怎么办呢?这时就引入了Gamma分布。
Dirichlet 分布
Dirichlet 分布的定义式是:

这就是多点了,之前的Beta分布的p就两个要么是p要么是1-p,而这里的p就很多了,因此我们这里写成向量的形式,同样的Beta分布的![]() 就两个,而这里的是K个,因此也可直接写成向量形式,因此 Dirichlet 分布算是Beta分布的扩展,理解是一样的,这样按照上面的理解就好,同样的他也有一个和Beta分布类似的性质即Dirichlet-Multinomial 共轭,如下:
就两个,而这里的是K个,因此也可直接写成向量形式,因此 Dirichlet 分布算是Beta分布的扩展,理解是一样的,这样按照上面的理解就好,同样的他也有一个和Beta分布类似的性质即Dirichlet-Multinomial 共轭,如下:

这里不详细的解释了,先验概率满足 Dirichlet 分布,在和物理过程结合后任然满足Dirichlet 分布。
这两个分布大家应该都理解了,这里建议大家看看那篇文章,你会理解的更深的,相信我,你会有惊喜的。下面我们来看看另外一个知识点即Gibbs Sampling
Gibbs Sampling(吉布斯采样)
这个采样我在深度学习相信的讲解了,大家有兴趣的可以看看我之前的写的,这里只是简单讲解一下这个采样过程,当然这需要你具有一些基础性的采样知识,不懂的请看我的这篇文章,下面我就简单的讲讲Gibbs Sampling,这里保证大家能看懂的,好,废话不多说,下面开始:
在实际生活中,大量问题包含随机性因素。有些问题很难用数学模型来表示,也有些问题虽建立了数学模型,但其中的随机性因素较难处理,很难得到解析解,这时使用计算机进行随机模拟是一种比较有效的方法。随机模拟方法是一种应用随机数来进行模拟实验的方法,也称为蒙特卡罗法。这种方法名称来源于世界著名的赌城——摩纳哥的蒙特卡罗,通过对研究问题或系统进行随机抽样,然后对样本值进行统计分析,进而得到所研究问题或系统的某些具体参数、统计量等。
也就是说我们的概率密度太复杂,导致我们写出来或者无法计算,这里我们就无法得到对应的统计特性,但是现在我们就是想知道他的统计特性,怎么办呢,如果我们能够得到符合这个很复杂的概率密度的样本,那么我们根据样本来统计这个概率密度的统计特性也是可以的,因此采样就这样由来了,上面的链接我简单的讲解了一些常用地采样方法,但是那些方法都是针对一维的概率密度进行抽样,但是如果高维就无法使用了,但是有针对高维进行抽样的方法即Gibbs Sampling,这里我只简单的讲讲结果,尽量让大家知道他的工作流程。
首先我们从二维的吉布斯采样开始,然后推向高维的吉布斯采样,首先这里默认大家都懂了一维的吉布斯采样了,二维和高维的采样思想其实很简单,就是我能不能把高维的采样降到一维,通过一维来采样就简单了,因此高维的采样就是这个思想,下面我们以二维的为例进行讲解:
假如我有一个联合分布![]() ,我想求出符合这个联合概率密度的统计特性,但是这个概率密度太复杂了,无法数学求出, 因此如果我能拿到服从这个联合概率密度的样本,那么在通过样本就可以估计这个联合概率密度的统计特性了,但是现在的问题是他是二维的,如何处理呢?这样做:
,我想求出符合这个联合概率密度的统计特性,但是这个概率密度太复杂了,无法数学求出, 因此如果我能拿到服从这个联合概率密度的样本,那么在通过样本就可以估计这个联合概率密度的统计特性了,但是现在的问题是他是二维的,如何处理呢?这样做:
这里我们知道符合联合概率分布的一个值假如是![]() ,带进联合概率密度,此时就变成一维的联合概率密度了,如下:
,带进联合概率密度,此时就变成一维的联合概率密度了,如下:

根据上式我们知道了 ,其中联合概率密度知道的带进去可计算分子,分母也很容易知道,因此此时整个式子就变为一维的概率分布了,然后就可以通过一维的采样技术采样了,此时就能得到![]() ,然后我把
,然后我把![]() 当做已知的量,
当做已知的量,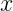 当做未知量,按照下式:
当做未知量,按照下式:

同理此时采样就可以得到![]() ,以此类推进行下去,因此它的图形应该是两个轴的变化来回更替,如下图:
,以此类推进行下去,因此它的图形应该是两个轴的变化来回更替,如下图:

具体二维吉布斯采样算法如下:

同理推向高维即如下:

这里没讲采样细节,其实高维采样很麻烦的,这里没有展开讲,建议大家看看我的深度学习方面的博客,那里我详细的讲解而了,这里就不详细讲解了。下面我们就就简单的讲解一下我们的LDA模型,上面的内容都是铺垫,下面的讲解都是从总体性讲解的,目的是希望大家能搞懂LDA的工作原理的,然后我们再去研究他的数学论证以及学习方法,这样才是正确的学习方法,否则一旦没有全局把控,乱了,你会看不下去的,好,下面继续,下面只从整体的工作原理开始,大家一定要把握住他的整体性。
LDA模型整体理解

其中,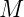 代表文档数目,
代表文档数目,![]() 代表主题数目,词汇表中有
代表主题数目,词汇表中有![]() 个词,
个词,![]() 表示第
表示第![]() 篇文档的单词个数,
篇文档的单词个数,![]() 和
和![]() 表示第
表示第![]() 篇文档中第
篇文档中第![]() 个单词及其主题。
个单词及其主题。![]() 表示主题
表示主题![]() 中所有单词的概率分布,
中所有单词的概率分布,![]() 表示第
表示第![]() 篇文档的所有主题概率分布。
篇文档的所有主题概率分布。![]() 和
和![]() 分别服从超参数
分别服从超参数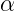 和
和![]() 的Dirichlet先验分布。
的Dirichlet先验分布。
这里大家首先要做的就是先理解一下符合的意义,这里先和大家强调一下就是上图的![]() 和
和![]() 分别服从超参数和
分别服从超参数和![]() 的Dirichlet先验分布,我们前面讲的基础就用到了,这里大家应该理解使用Dirichlet分布的意义在哪里,这个分布有什么特性,最大的特性就是在先验的概率基础上加上物理过程,最后的分布仍符合Dirichlet分布。我们从
的Dirichlet先验分布,我们前面讲的基础就用到了,这里大家应该理解使用Dirichlet分布的意义在哪里,这个分布有什么特性,最大的特性就是在先验的概率基础上加上物理过程,最后的分布仍符合Dirichlet分布。我们从![]() 开始讲,这里的
开始讲,这里的![]() 代表第m篇文章的所有主题(隐分类)的概率,那么从
代表第m篇文章的所有主题(隐分类)的概率,那么从![]() 到
到![]() 是什么意思呢?其中
是什么意思呢?其中![]() 如本节刚开的矩阵分解图的等号右边第二个矩阵,即隐分类和文本,那么从
如本节刚开的矩阵分解图的等号右边第二个矩阵,即隐分类和文本,那么从![]() 到
到![]() 是从第m篇文章中第n个词,去生成对应这篇文章的第n个词的主题的概率。这里使用掷骰子为例进行说明,就是说我有M个骰子,每篇文章看成一个骰子,而每个骰子有K个面,这里每个面代表一个词,这里的每个骰子都是服从Dirichlet分布,且每个骰子摇出来的面的概率不同,现在开始物理试验过程,我拿出属于对应每篇文章的骰子进行摇号,我需要摇多少次呢,摇到和本篇文章的词数相同,那么我摇出的骰子代表什么意思呢?代表在第m篇文章中的第n个词属于哪个主题这就是
是从第m篇文章中第n个词,去生成对应这篇文章的第n个词的主题的概率。这里使用掷骰子为例进行说明,就是说我有M个骰子,每篇文章看成一个骰子,而每个骰子有K个面,这里每个面代表一个词,这里的每个骰子都是服从Dirichlet分布,且每个骰子摇出来的面的概率不同,现在开始物理试验过程,我拿出属于对应每篇文章的骰子进行摇号,我需要摇多少次呢,摇到和本篇文章的词数相同,那么我摇出的骰子代表什么意思呢?代表在第m篇文章中的第n个词属于哪个主题这就是![]() ,就这样把所有的文章按照这样的方法进行做一遍。好到这里我们停一下,再看看另外一个服从Dirichlet分布代表什么。
,就这样把所有的文章按照这样的方法进行做一遍。好到这里我们停一下,再看看另外一个服从Dirichlet分布代表什么。
从上面介绍符号我们知道![]() 表示主题
表示主题![]() 中所有单词的概率分布,也就是说
中所有单词的概率分布,也就是说![]() 会产生k个骰子,这k个骰子分别对应着K个主题(隐分类),那么
会产生k个骰子,这k个骰子分别对应着K个主题(隐分类),那么![]() 就是给这些主题找对应的单词,也就是说我现在知道第m篇文章第n个位置输入哪个主题,但是我不知道这个位置的单词,这个单词怎么确定呢?就是通过
就是给这些主题找对应的单词,也就是说我现在知道第m篇文章第n个位置输入哪个主题,但是我不知道这个位置的单词,这个单词怎么确定呢?就是通过![]() 进行确定这个单词即
进行确定这个单词即![]() ,而这个词从哪里找呢?是从词汇表表中找即V。词典里的词和文章里的词不同,词典的词是不会重复,是根据语料的出来的。
,而这个词从哪里找呢?是从词汇表表中找即V。词典里的词和文章里的词不同,词典的词是不会重复,是根据语料的出来的。
这里需要在强调一下,就是首先我们是给文章的词去寻找对应的主题(隐分类)即![]() 和
和![]() ,那么当我们需要给第m篇第n个词寻找对应的主题时,此时我们把对应这一篇文本的另外一个服从Dirichlet分布
,那么当我们需要给第m篇第n个词寻找对应的主题时,此时我们把对应这一篇文本的另外一个服从Dirichlet分布![]() ,从词典中寻找对应这个位置的,符合这个主题的单词即
,从词典中寻找对应这个位置的,符合这个主题的单词即![]() ,同时也从
,同时也从![]() 中得到这个单词,进行训练,总体上LDA的思想就是这样,下面我从整体思路再理一下,希望大家能理解他的工作原理:
中得到这个单词,进行训练,总体上LDA的思想就是这样,下面我从整体思路再理一下,希望大家能理解他的工作原理:
首先我们只拥有很多篇文本和一个词典,那么我们就可以在此基础上建立基于基于文本和词向量联合概率(也可以理解为基于文本和词向量的矩阵,大家暂且这样理解),我们只知道这么多了,虽然知道了联合概率密度了,但是还是无法计算,因为我们的隐分类或者主题不知道啊,在LSA中使用SVD进行寻找隐分类的,在PLSA中使用概率进行找隐分类的,而在LDA中是如何做的呢?他是这样做的,首先我为每个文本赋值一个服从Dirichlet分布的![]() ,他的作用就是寻找文本中对应词的主题(隐分类),或者从本篇文本的角度来说确定这篇文本有哪几个隐分类,而隐分类的确定是根据
,他的作用就是寻找文本中对应词的主题(隐分类),或者从本篇文本的角度来说确定这篇文本有哪几个隐分类,而隐分类的确定是根据![]() 进行确定的,首先我们根据
进行确定的,首先我们根据![]() 确定了这个这篇文章的某一个位置的词了即
确定了这个这篇文章的某一个位置的词了即![]() ,那么我通过词典,在通过
,那么我通过词典,在通过![]() 去寻找这个词对应的隐分类(主题),这样我就确定了这篇文章的隐分类,同时都计算了所有的相关概率,后面就可以通过隐分类和相关概率进行判断文本的相似性等等就和前面几节一样了,这就是LDA的深层工作原理,这样说大家应该可以理解了吧,写吐了,本节结束,下一节我们主要从数学方面对LDA的学习算法和训练算法进行讲解,当然也是很难理解的,我尽量深入浅出讲解,大家如果有感觉,建议看论文辅助理解,这样效果会更好。这篇论文是:
去寻找这个词对应的隐分类(主题),这样我就确定了这篇文章的隐分类,同时都计算了所有的相关概率,后面就可以通过隐分类和相关概率进行判断文本的相似性等等就和前面几节一样了,这就是LDA的深层工作原理,这样说大家应该可以理解了吧,写吐了,本节结束,下一节我们主要从数学方面对LDA的学习算法和训练算法进行讲解,当然也是很难理解的,我尽量深入浅出讲解,大家如果有感觉,建议看论文辅助理解,这样效果会更好。这篇论文是:
《Parameter estimation for text analysis》Gregor Heinrich Technical Report
Fraunhofer IGD
Darmstadt, Germany
[email protected]