数据结构之哈希表
文章目录
- 定义
- 散列函数
- 碰撞的解决
- 开放地址法
- 线性探测法
- 二次探测
- 再哈希法
- 链地址法
- 哈希表实现
定义
- 哈希表的思想是:用一个与集合规模差不多大的数组来存储这个集合,将数据元素的关键字映射到数组的下标,这个映射称为“散列函数”,数组称为“散列表”。查找时,根据被查找的关键字找到存储数据元素的地址,从而获取数据元素。
- 哈希表是唯一的专用于集合的数据结构。可以以常量的平均时间实现插入、删除和查找。
- 顺序查找的时间复杂度为O(N) ,二分查找和查找树的时间复杂度为O(logN),而 理想状态哈希表的时间复杂度为O(1) 。
因为散列函数的定义域范围比值域大,两个或更多的数据元素可能被映射到同一个位置,称为“冲突或碰撞”。这种情况是不可避免的。因此,实现散列表的两个最基本的问题是:如何设计散列函数,如何解决碰撞。
散列函数
选取散列函数需要考虑的因素有:
- 计算散函数所需时间。
- 关键字长度。
- 散列表长度(散列表地址范围)。
- 关键字分布情况。
- 记录的查找频率。
常用的散列函数包括直接定址法、保留余数法、数字分析法、平方取中法和折叠法等。
(1) 直接定址法
直接取关键字的值或关键字的某个线性函数的值作为散列地址。设关键字为x,那么散列地址可表示为:
(2) 保留余数法
如果M是散列表的大小,关键字 x 的数据元素的散列地址为:
在保留余数法中,选取合适的余数M很重要,如果选取不当,则导致大量的碰撞。
经验表明:M为素数(除了1和它本身以外不再有其他因数。)时,散列表的分布比较均匀。
(3) 数字分析法
如果在关键字集合中,每个关键字均由n位组成,分析关键字中每一位的分布规律,并从中提取分布均匀的若干位或它们的组合作为地址。
例如计算机的IP地址,一个IP地址由两部分组成:网络号和主机号。在同一子网中的主机的网络号是相同的。在某个网络中,我们可以将IP地址作为关键字。如果采取散列方法保存这个集合,可以选取IP地址的主机号部分作为存储地址。
(4) 平方取中法
如果关键字中的各位的分布都比较均匀,但关键字的值域比数组的规模大,则可以将关键字平方后,取其结果中间各位作为散列函数值。
由于中间各位和每一位数字有关系,因此均匀分布的可能性较大。
例如:4731 X 4731 = 22 382 361。中间选取几位,依赖于散列表的单元总数。若散列表中有100个单位,选取中间4,5两位,即关键字4731的地址为82.
(5) 折叠法
如果关键字相当长,以至于和散列表的单元总数相比大的多,则采取折叠法。如果数字的分布大体上是均匀的,通常选取一个长度后,将关键字按长度分组相加。例如:542 242 241,折叠后542 + 242 + 241 = 1025,抛弃进位,得到散列表的结果为25
不存在一种万能的散列函数,在任何情况下都是出色的。但是大部分情况下,保留余数法比较好。
碰撞的解决
在选取散列函数时,由于很难选取一个既均匀分布又简单,同时保证关键字和散列地址一一对应的散列表,所以冲突时不可避免的。如果具有不同关键字的 k 个数据元素的散列地址完全相同,就必须为 k-1个数据元素重新分配存储单元。通常称其为“溢出”的数据元素。
常用的处理冲突的方法有两种:开放地址法和链地址法(拉链法)
开放地址法
根据hash函数计算数组下标时,当遇到数据存放的冲突时就需要重新找到数组的其他位置。开放地址法通常有三种方式:线性探测法、二次探测法、再哈希法。
线性探测法
线性探测方法就是线性探测空白单元。当数据通过哈希函数计算应该放在700这个位置,但是700这个位置已经有数据了,那么接下来就应该查看701位置是否空闲,再查看702位置,依次类推。
二次探测
在线性探测过程中会产生数据聚集问题,当数据聚集越来越大时,数据经哈希化后就需要插在聚集的后端。这样会使得效率变得很低。二次探测是防止聚集产生的一种尝试,相隔比较远的单元进行探测,而不是线性一个个的探测。
二次探测是过程是x+1,x+4,x+9,以此类推。二次探测的步数是原始位置相隔的步数的平方。
再哈希法
再哈希是当哈希函数计算下标冲突时,把关键字用不同的哈希函数再做一遍哈希化,用这个结果作为步长,对指定的关键字,探测的步长是不变的,可以说不同的关键字可以使用不同的步长,并且步长可以控制。
如: H2(x) = 5 - (x % 5);
虽然不同的关键字可能会映射到相同的数组单元,但是可能会有不一样的探测步长。如上式使用步长1~5进行探测。步长是不能为零的,不然就会形成死循环。
探测序列通常使用再哈希法生成。
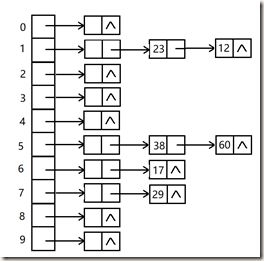
链地址法
将映射到同一地址的数据元素分别保存到散列表以外的各自线性表中。由于地址相同的数据元素个数变化比较大,因此通常采用链表的方式。散列表本身只保存一个指向各自链表中第一个节点的指针。这种方法称为“开散列表",或拉链法,可以理解为“链表的数组”。
开散列表将具有同一散列地址的数据元素都存储在一个单链表中。在散列表中插入、查找或删除一个元素,就是在对应的单链表中进行的。
如下图:
哈希表实现
这里将参考JDK1.7中HashMap的实现,采用数组+单链表的形式实现哈希表。
- 定义
public class MyHashMap<K,V> {
// 默认初始容量16,该值应为2的n次幂,以减少碰撞
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//负载因子,已存储的元素个数与数组长度的比值。当超过负载因子,数组需扩容
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//数组最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
//已存储元素的个数
int size;
//存储元素的数组,其中每个元素都是一个单链表
Entry<K, V>[] table;
/**
* 单链表
*
* @param
* @param
*/
static class Entry<K, V> {
final K key; //键
V value; //值
Entry<K, V> next; //下一个元素的引用
int hash; //哈希值
Entry(int h, K k, V v, Entry<K, V> n) {
value = v;
next = n;
key = k;
hash = h;
}
}
public MyHashMap() {
//初始化数组
table = new Entry[DEFAULT_INITIAL_CAPACITY];
}
}
- 添加元素
/**
* 添加元素
* @param key
* @param value
* @return 返回原位置的值
*/
public V put(K key, V value) {
if (key == null)
//如果key为null,调用putForNullKey()处理
return putForNullKey(value);
//计算哈希值
int hash = hash(key);
//计算数组下标
int i = indexFor(hash, table.length);
//如果key已存在,则替换value值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
//key不存在,则将节点插入对应链表的表头
addEntry(hash, key, value, i);
return null;
}
/**
* 当key为null时,调用此方法,将value放置在数组第一个位置。
* @param value
* @return 返回原位置的值
*/
private V putForNullKey(V value) {
//如果key已存在,则替换value值
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
//key不存在,则将节点插入数组下标为0对应的链表中
addEntry(0, null, value, 0);
return null;
}
/**
* 将元素添加到指定位置链表的表头
* @param hash
* @param key
* @param value
* @param bucketIndex
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//计算哈希表最大阈值
int threshold = (int) (table.length * DEFAULT_LOAD_FACTOR);
//如果超过阈值
if ((size >= threshold) && (null != table[bucketIndex])) {
//数组扩容
resize(2 * table.length);
//重新计算哈希值
hash = (null != key) ? hash(key) : 0;
//重新计算下标
bucketIndex = indexFor(hash, table.length);
}
Entry<K,V> e = table[bucketIndex];
//插入节点
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
/**
* 数组扩容
* @param newCapacity
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果数组已达到最大容量,则返回
if (oldCapacity == MAXIMUM_CAPACITY) {
return;
}
Entry[] newTable = new Entry[newCapacity];
//将原数组元素转换到新数组
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
//重新计算哈希值
e.hash = null == e.key ? 0 : hash(e.key);
//重新计算下标
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
table = newTable;
}
/**
* 散列函数
* @param k
* @return
*/
final int hash(Object k) {
int h = 0;
h ^= k.hashCode(); //0 ^ x = x
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* 根据哈希值返回数组下标
*/
static int indexFor(int h, int length) {
return h & (length-1); //等价于对length取模
}
- 获取元素
/**
* 获取元素
* @param key
* @return
*/
public V get(Object key) {
//如果key为null,调用getForNullKey()处理
if (key == null)
return getForNullKey();
if (size == 0) {
return null;
}
//根据key,计算哈希值
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//如果哈希值相等,且key相同,则返回对应value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e.value;
}
return null;
}
/**
* 获取key为null的值
* @return
*/
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
在java jdk8中对HashMap的源码进行了优化,在jdk7中,HashMap处理“碰撞”的时候,都是采用链表来存储,当碰撞的结点很多时,查询时间是O(n)。
在jdk8中,HashMap处理“碰撞”增加了红黑树这种数据结构,当碰撞结点较少时,采用链表存储,当较大时(>8个),采用红黑树(特点是查询时间是O(logn))存储
参考链接:
https://www.cnblogs.com/zhuweiheng/p/8207255.html
https://blog.csdn.net/cai2016/article/details/52728761
https://www.cnblogs.com/dijia478/p/8006713.html