TLV简介以及c语言实现装包与解析
一、TLV简介
协议可以使双方不需要了解对方实现细节的情况下进行通信,因此双方可以是异构的,例如服务器可以是c,客户端可以是java,基于相同的协议,我们可以用自己熟识的语言工具来对通信发送的数据装包或解析来进行通信。当然也不只是这样,计算机通信不是通过字符串传输的,是将电信号转换为逻辑信号,其转换方式是将高低电平表示为二进制数中的1和0, 再通过不同的二进制序列来表示所有的信息。也就是将数据以二进制中的0和1的比特流的电的电压做为表示,如串口通信,波特率(bps)表示一秒钟传输多少个位(bit),将数据序列化发出去。不光是用在通信工作上,在存储工作上我们也经常用到。如我们经常想把内存中对象存放到磁盘上,就需要对对象进行数据序列化工作。但是要知道对方发过来的数据是什么意思,就需要双方对数据有约定,这就是所谓的通讯协议。
通讯协议约定中包括对数据格式,同步方式,传送速度,传送步骤,纠错方式以及控制字符定义等问题做出统一规定,通信双方必须共同遵守,倘若一方不遵守,便会直接导致数据不能被解析。常见的有tcp,udp,http等常见协议。而这些都是固定的不可修改的协议,而TLV具备了很好可扩展性。同时也具备了缺点,因为其增加了2个额外的冗余信息,tag 和len,特别是如果协议大部分是基本数据类型int ,short, byte. 会浪费几倍存储空间。另外Value具体是什么含义,需要通信双方事先得到描述文档,即TLV不具备结构化和自解释特性。TLV,即Tag(Type)-Length-Value,是一中简单实用的数据传输方案。在TLV的定义中,可以知道它包括三个域,分别为:标签域(Tag)或者称为类型域(Type),长度域(Length),内容域(Value),几乎所有的需要在卡片和终端之间传送的数据都是TLV格式的或者是TLV变种。
假设报文类型定义如下:
| Tag定义 |
说明 |
长度 |
数据域说明 |
| 0x01 |
控制照明灯命令 |
整个TLV的长度 |
0x00: 关灯 0x01: 开灯 |
这样发来的数据0x01(控制照明灯) 0x03(总的长度,Tag类型和length长度和value数据,长度为3) 0x01(开灯),收到数据0x01 0x03 0x01就可以知道需要控制LED灯开灯。
帧头:
数据丢失可能会出错或丢失导致解析数据错误,要发的数据是0x01 0x03 0x01,但发送过程中混入了垃圾数据0x02,变成0x02 0x01 0x03 0x01一读0x02未知类型,0x01错误长度,解析错误,防止这种情况,一般采用添加加帧头数据。如加个0xFE的帧头,要发的数据是0XFE 0x01 0x04 0x01(这里定义的长度是总的TLV长度所以加了帧头之后长度变成0x04),接收到的数据0x33 0XFE 0x01 0x04 0x01,接收端就可以从帧头开始读,此时就能正确的解析出来,当然帧头也可能会出错,0xFE变0xFD了,找不到帧头就继续找下一个帧头0xFE,也就丢掉一帧数据,如果不是什么很严重的数据也没什么关系,比如这里的控制灯的状态或者是获取温度的温度值这样的无关紧要,但像波音737这样的致命错误就需要谨慎就需要更加严谨的协议。
校验位:
当然加帧头还是不够,数据出错了还是不知道,比如要发的数据是0xFE 0x01 0x04 0x01 (开灯),而数据域出了问题0x01变成0x00,收到的数据就是0xFE 0x01 0x04 0x00(关灯),本来想开灯的结果变成了关灯,数据出错了还不知道,这时候就需要在数据尾加校验,校验有奇偶校验,CRC校验等,奇偶校验,顾名思义在数据最后面加0或1使得整个数据最后1的个数是奇数或者是偶数,如果某位出了错,计算整个数据1的个数与最后的校验位做比较就可以知道是否出错,虽然双位同时发生错误的概率相当低,但奇偶校验却无法检测出双位错误。所以使用CRC校验比较可靠,CRC也还可以用来纠错,感兴趣的可以深究。

CRC示例参考:https://blog.csdn.net/d_leo/article/details/73572373
对CRC计算的实现可以对数据流逐位进行计算,效率很低。实际上仔细分析CRC计算的数学性质后我们可以多位多位计算,最常用的是一种按字节查表的快速算法。该算法基于这样一个事实:计算本字节后的CRC码,等于上一字节余式CRC码的低8位左移8位,加上上一字节CRC右移 8位和本字节之和后所求得的CRC码。如果我们把8位二进制序列数的CRC(共256个)全部计算出来,放在一个表里,编码时只要从表中查找对应的值进行处理即可。网上实现CRC算法的代码很多,度娘搜索了解一下~。之前说过协议通信双方必须共同遵守,所以CRC的算法也必须是相同的能算出相同的CRC值才可以通信。
最后发来的数据就是[帧头] [Tag] [Length] [Value] [CRC校验和],用前面[帧头] [Tag] [Length] [Value]可以算出一个CRC的值,用来跟TLV报文最后的[CRC校验和]做比较,任何一位出错都会导致这两个不相等,就可以知道数据错误。这就是一个比较完备的tlv协议了
参考博客:https://blog.csdn.net/qq_43296898/article/details/88863854
二、对tlv报文的封包与解包
tlv的封包:
tlv封包就是将字节序封装进一个字符串,这个字符串的内容就是tlv的报文,比较简单
int packtlv_led(char *buf, int size, int cmd)
{
unsigned short crc16;
int pack_len = TLV_FIXED_SIZE+1; /* Only 1 byte data */
if(!buf || size上面的value仅是一个字节直接赋值即可, 如果是多个字节或者是一个字符串也可以用memcpy将其封包。
tlv解包
tlv报文的格式: [帧头] [Tag] [Length] [Value] [CRC校验和] (这里我用的CRC校验和是16位的所以占两个字节)先从一个最简单的解一个一帧的包说起,首先需要找到帧头,接着往下读到长度tlv_len,从帧头开始到tlv_len-2(除开后面2位CRC)可以算出一个CRC值,用算出来的CRC值与tlv最后两位CRC的值做对比,如果相等说明传过来的tlv报文是正确的,接着根据Tag类型以及Value值做相对应的处理。
多帧解包也是如此,假设tlv报文总的长度是bytes,做个循环从0开始到bytes找,找到帧头接着就往下读tlv的长度,算CRC做比较,如果是正确的tlv就做处理,如果是错误的就找下一个帧头,重复上述操作。
但是有时候发送tlv数据的时候,由于网络或传输原因,先接收到tlv数据的前半部分,过段时间后半部分数据才来到,这两段数据合起来可以组成一个完整的正确的tlv数据。但是解析的时候如果仅仅是接收到前半部分的tlv解析错误之后就将这前半部分都给丢掉了,之后来到的后半部分也只能是错误tlv接着也丢掉,就比如你朋友给你写信,一封信分成两个部分,你一看前面的信话说到一半就没了!这是啥意思啊!丢掉了,结果过段时间第二封信到来,可是你前半部分丢掉了忘记是什么内容了,光拿着后半部分同样看不懂,只好也丢掉。所以我们需要多考虑一下出现半帧数据的情况,读到的数据不能是将数据存到首地址,这样数据会被覆盖掉,而应该是读到上次数据后面。假设定义一个char buf[BUFSIZE]来将读到数据保存起来,bytes是这个buf里存在的数据长度,所以剩下的数据应该读到&buf[bytes]之后才能组成一个完整的tlv报文,rv = read(fd, &buf[bytes], BUFSIZE-bytes); bytes = bytes+rv; 同样的先拿一帧的数据来操作理解,假设一帧数据是FD 03 06 01 A2 2F,这一帧数据分成两半,前半部分是FD 03 06,后半部分是01 A2 2F,一开始bytes设置为0,从首位置地方开始存,先读到FD 03 06,解析错误,bytes = bytes + rv ;read()返回读到数据的个数,所以rv = 3, bytes = 0+3 = 3,接着read(fd, &buf[bytes], BUFSIZE-bytes);后面读到的数据就从存到&buf[3]开始存,接收到01 A2 2F,bytes = bytes + rv, 此时bytes = 6。就像上面说过的解析tlv一样for(i=0;i 接着就是多帧的考虑半帧的情况,多帧的时候考虑的半帧一般是在tlv报文最后边。假如收到的数据是【正确的一帧】 【前半帧】 【正确的一帧】 【后半帧】,这样的数据都稀巴烂了不用去考虑。考虑收到的半帧在最后面,如【正确的一帧】【错误的一帧】【正确的一帧】...【前半帧】,接下来收到的是【后半帧】【剩下的数据...】,与之前收到的前半帧组成正确的一帧tlv报文就可以正确解析出来。 实现半帧情况最主要就是半帧的位置以及后面到的半帧存放到之前的半帧数据后面,多帧的时候比较复杂,所以解析出正确的tlv报文之后做完对tlv报文处理便将正确的tlv部分移出数组,剩余tlv的长度等于tlv长度减掉移出的部分数据长度,同理错误的tlv报文检验出错后也需要移出数组,剩余tlv的长度等于tlv长度减掉移出的部分长度。直到最后如果没有半帧的情况,错误的正确的tlv都移出了数组,数组里面存有数据的数据个数bytes就可以设置为0,从首位置重新存放tlv的数据。如果最后有半帧,bytes就设置为半帧的长度,下次读到的数据存放到这半帧的后面,继续解析,下面贴出解析tlv报文的流程图 第一次画流程图没有经验,凑合着看一下~ 需要注意的地方: 将需要移除数据之后的数据移到最前面实现数据的移出,但是使用的是memmove而不用memcpy。memmove函数的功能同memcpy基本一致,但是当src区域和dst内存区域重叠时,memcpy可能会出现错误,而memmove能正确进行拷贝。每次进行memmove()之后,设置数组中存在的数据长度bytes为剩下的数据长度,设置完之后需要跳转至循环之上,继续找下一个帧头进行解析。如果不跳转而是下一次循环的话,循环里i++会跳掉很多数据而解析出错。 tlv解析代码: 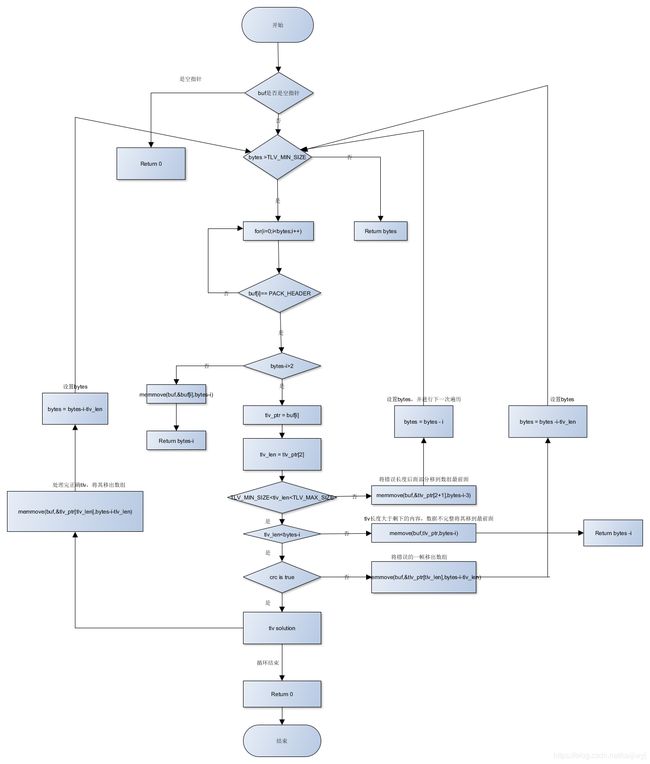
int unpack_tlv(char *buf, int bytes, char *true_tlv,int *true_size)
{
int i ;
char *tlv_ptr = NULL;
int tlv_len = 0 ;
unsigned short crc16,val ;
if(!buf||!true_tlv)
{
printf("Invailed input!\n") ;
return 0 ;
}
again:
if(bytes < TLV_MIN_SIZE) //数据长度太短
{
printf("tlv packet too short\n") ;
return bytes ;
}
for(i=0; i< bytes; i++)
{
if((unsigned char)buf[i]==PACK_HEADER)
{
if(bytes -i <= 2)//剩下的数据不能读到tlv的长度
{
printf("tlv_packet is too short so incomplete\n") ;
memmove(buf, &buf[i], bytes - i) ;
return bytes -i ;
}
tlv_ptr = &buf[i] ;
tlv_len = tlv_ptr[2] ;
if(tlv_len < TLV_MIN_SIZE||tlv_len>TLV_MAX_SIZE )//tlv长度不合理说明是错误的一帧
{
memmove(buf, &tlv_ptr[2], bytes-i-2) ;//将tlv长度后面的移到数据最前面
bytes = bytes -i -2 ;
goto again;
}
if(tlv_len > bytes - i)//如果tlv长度比剩下的数据长度还长
{
memmove(buf, tlv_ptr, bytes-i) ;
printf("tlv_packet is incomplete\n") ;
return bytes - i ;
}
crc16 = crc_itu_t(MAGIC_CRC,(unsigned char*)tlv_ptr, tlv_len-2);
val = bytes_to_ushort((unsigned char*)&tlv_ptr[tlv_len-2],2) ;
//printf("crc: %d, val: %d\n",crc16, val) ;
if(val != crc16)//crc校验错误
{
printf("CRC check error\n") ;
memmove(buf, &tlv_ptr[tlv_len], bytes-i-tlv_len) ;
bytes = bytes -i -tlv_len ;
goto again ;
}
//printf("CRC check true\n") ;
memmove(&true_tlv[*true_size], tlv_ptr, tlv_len) ;
*true_size += tlv_len ;
memmove(buf,&tlv_ptr[tlv_len], bytes-i-tlv_len) ;//处理完正确的一帧之后将其移出数组
bytes = bytes -i -tlv_len ;
goto again ;
}//if((unsigned char)buf[i] == PACK_HEADER)
}//for(i=0;i