MySQL日志详解
文章目录
- 引言
- 错误日志 (error log)
- 通用日志 (general log)
- 慢查询日志 (slow query log)
- 二进制日志 (binlog)
- 中继日志 (relay log)
- InnoDB日志 Redo与Undo
- Redo
- undo
引言
日志是MySQL中很重要的部分,无论是MySQL调优,事务回滚,还是MySQL本身的优化,都需要日志的帮助,这就意味这MySQL日志种类也是非常多的,这篇文章就来介绍下MySQL的日志构成.
错误日志 (error log)
MySQL中唯一默认开启的日志(deepin 15.7, MySQL版本5.7),默认的路径可在MySQL配置文件中找到,如下
log_error = /var/log/mysql/error.log
作用如下
- 记录MySQL数据库启动和关闭的信息
- 运行过程中所有较为严重的警告信息与错误信息
下面是张截的日志的图
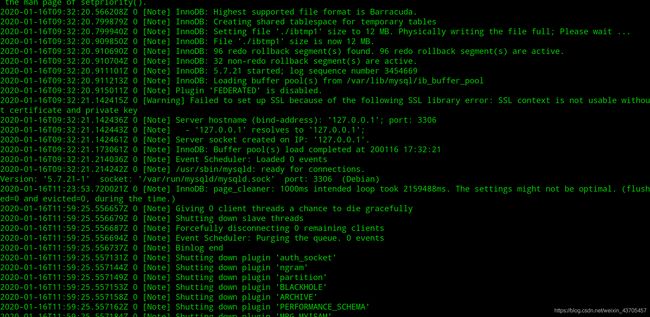
日志结构如下:
时间 PID [错误级别] 错误信息
日志等级为:
note warning error
通用日志 (general log)
顾名思义,通用日志其实就是记录所有我们使用过的sql语句,它会记录所有的我们执行的sql语句与连接记录,而这在大流量时是巨大的性能损耗,所以默认是不开启的.


通用日志包含以上三个参数
- general_log 是否开启
- general_log_file 默认日志的输出文件
- log_output 以何种形式进行记录 可选值 TABLE, FILE, 或者 NONE,默认值是FILE,可以同时选择TABLE和FILE, 当我们选择TABLE的时候可以执行以下语句查看
select * from mysql.general_log;
这通常用在测试的时候,当出现错误的时候可以更好的复现,因为它会输出很多的日志信息,势必会损耗一些效率,所以在我们正常使用的时候一般是不开启的.
慢查询日志 (slow query log)
MySQL调优的一个重要手段,其作用就是设置一个超时时间,如果有哪条sql语句超过了定的超时时间就会被记录,这样就可以找到效率低下的sql语句,接下来我们就可以结合explain或profile来对sql进行分析,从而进行调优.

慢查询日志仍然是默认关闭的,我们可以使用set slow_query_log = ON 来开启,不过这是在当前有用而已,重启后就没用了,想要一直存在的话可以去修改配置文件,在[mysqld]段中加入如下语句
slow_query_log = 1
slow_query_log_file = /var/log/mysql/mysql-slow.log
long_query_time = 2
语义为默认开启,日志输入到/var/log/mysql/mysql-slow.log,超时时间定为2秒,注意这里的单位为秒,可以配置成小数,直接写成小数就可以了.
其实还有其他参数,如下,这些参考其他博主的,链接附在文末
log_queries_not_using_indexes # :如果值设置为ON,则会记录所有没有利用索引的查询(性能优化时开启此项,平时不要开启)
min_examined_row_limit=100 # -- SQL语句扫描的行数少于设定值的语句不会被记录到慢查询日志,
#即使这个语句执行时间超过了long_query_time的阈值,默认为0
log_throttle_queries_not_using_indexes=10 # -- 设定每分钟记录到日志的未使用索引的语句数目,
# 超过这个数目后只记录语句数量和花费的总时间
log_output=FILE,TABLE # -- 日志文件记录方式
log_slow_admin_statements=ON # -- 记录执行缓慢的管理SQL,如alter table,analyze table,
check table, create index, drop index, optimize table, repair table等
log_slow_slave_statements=ON # -- 记录从库上执行的慢查询语句, 默认为 OFF
log_timestamps=system # -- 版本新增时间戳所属时区参数,默认记录UTC时区的时间戳到慢查询日志,最好修改为记录系统时区
固然,当慢查询日志的内容多了以后很难管理,所以有了一个好用的工具mysqldumpslow,这个工具可以帮我们找出锁定时间最长,查询时间最长,访问次数最多等等数据,具体参见mysqldumpslow --help,下面是几个使用mysqldumpslow的实例

二进制日志 (binlog)
在主从复制时,从master中传往slave的日志就是binlog,用来保存主服务器的DDL与DML,在slave读取时就可以与master进行数据同步了,注意MYSQL会在执行语句之后,释放锁之前,写入二进制日志,这样就保证了是事务安全的,因为就算有语句失败也会进行回滚,满足事务的原子性和一致性.
这篇文章讲的很好
中继日志 (relay log)
用在主从复制时,作为master的输出和slave中sql线程的输入,slave中会把接收到的relay log中的sql,也就是master中执行的sql重新执行,从而与master中实现数据同步,
同样是参考的,原文见文末链接
max_relay_log_size=0; -- 标记relay log 允许的最大值,如果该值为0,
则默认值为max_binlog_size(1G);如果不为0,则max_relay_log_size则为最大的relay_log文件大小
relay_log=; -- 定义relay_log的位置和名称,如果值为空,
则默认位置在数据文件的目录(datadir),文件名为host_name-relay-bin.nnnnnn
relay_log_basename=; -- 定义relay_log的位置,如果值为空,则默认位置在数据文件的目录(datadir)
relay_log_index=; -- 定义relay_log索引的位置和名称,如果值为空,
则默认位置在数据文件的目录(datadir),文件名为host_name-relay-bin.idx
relay_log_info_file=relay-log.info; -- 设置relay-log.info的位置和名称(relay-log.info记录MASTER的binary_log的恢复位置和relay_log的位置)
relay_log_info_repository=FILE; -- 日志文件记录方式,默认为FILE
relay_log_purge=ON; -- 是否自动清空不再需要中继日志时。默认值为1(启用)。
relay_log_recovery=OFF; -- 当slave从库宕机后,假如relay-log损坏了,导致一部分中继日志没有处理,
则自动放弃所有未执行的relay-log,并且重新从master上获取日志,这样就保证了relay-log的完整性。
默认情况下该功能是关闭的,将relay_log_recovery的值设置为 1时,可在slave从库上开启该功能,建议开启。
relay_log_space_limit=0; -- 防止中继日志写满磁盘,这里设置中继日志最大限额。
但此设置存在主库崩溃,从库中继日志不全的情况,不到万不得已,不推荐使用;
sync_relay_log=10000; -- 这个参数和 sync_binlog 是一样的, 建议采用默认值
当设置等于0,表示MySQL不控制log的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。
因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,
这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但大事务时会造成大量的磁盘IO。
当设置为大于0时,slave的I/O线程接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,
值设置的越大,造成的磁盘IO越小,但是当出现异常,丢失的事务越多。
sync_relay_log_info=10000; -- 这个参数和 sync_binlog 是一样的, 建议采用默认值
当设置等于0,表示MySQL不控制log的刷新,由文件系统自己控制它的缓存的刷新。这时候的性能是最好的,但是风险也是最大的。
因为一旦系统Crash,在binlog_cache中的所有binlog信息都会被丢失。
当设置为1时,slave的I/O线程每次接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,
这样是最安全的,因为在崩溃的时候,你最多会丢失一个事务,但大事务时会造成大量的磁盘IO。
当设置为大于0时,slave的I/O线程接收到master发送过来的binlog日志都要写入系统缓冲区,然后刷入relay log中继日志里,
值设置的越大,造成的磁盘IO越小,但是当出现异常,丢失的事务越多。
InnoDB日志 Redo与Undo
这两种日志与事务息息相关,我们从字面意思入手,undo,简单的理解就是不做,撤销嘛,是的,其作用就是辅助事务的回滚.后者为redo,字面理解就是重做,也是它就是为重新执行而生,为什么要重新执行,后面会详说.
Redo
在高性能MySQL中又叫事务日志,它可以帮我们提高事务的效率,具体如何做呢?就是存储引擎在进行执行事务的时候不直接修改内存中的数据,而是先这次的修改持久化到硬盘中的事务日志中,也就是redo日志中,然后再把此次操作写在表的内存拷贝中,这时显然磁盘中的数据对我们来说就是脏数据.然后数据库再异步的慢慢刷数据回到存数据的磁盘中.
为什么要这么做?原因是为了效率的提升,写入日志文件是顺序IO,直接写入磁盘则是是随机IO,所以采用事务redo日志会使效率有所提升,这种方法又被称作预写式日志(Write-Ahead Logging).
其比较重要的配置参数如下
innodb_log_group_home_dir # 默认为./ 下面会展示
innodb_log_files_in_group # 文件的数量 默认为2
innodb_log_file_size # 文件的默认大小
相信那个默认目录为./大家一定有点疑惑,其实对于MySQL程序来说是./,对我们来说我们可以这样查询

值得一提的是目录的权限如下,所以我们只能用root进入


我们可以在其中看到很多东西,其中的ib_logfile0和ib_logfile1是redo日志的内容,其中我们还可以看到二进制日志,慢查询日志,和数据库(DB)的详细数据(表.frm和数据.ibd)
还有一点很重要,就是redo何时进行写入磁盘的操作,显然有写入磁盘,就会有缓存存在,redo日志的buffer为Innodb_log_buffer,innodb首先将数据写进这个buffer中,有三种方式进行刷新
- 把日志缓冲写到日志文件,并且每秒刷新一次,但是事务提交不做任何操作.
- 把日志缓冲写到日志文件,每次事务提交都刷新持久化存储,这是默认的(最安全的设置).
- 每次提交把日志写到日志文件,但是不刷新,InnoDB每一秒做一次刷新,mysql服务异常,可保证数据不丢失.
显然我们的每次redo日志都会写入buffer,这样即使对于很大的事务来说写入效率也是极高的.
undo
又叫回滚日志.对于支持事务的引擎来说显然回滚是一个很重要的操作,它在一定程度上保证了事务的一致性.举个简单的例子,对于一个事务来说如果有一条sql执行错误,我们需要回滚,但前面已经执行了,虽然还没有commit,也就是还没有修改磁盘中的数据,但我们何来修改之前的数据?这就是undo日志的作用.即保存事务执行前的数据,用于回滚,更有意思的是其还可以被用作多版本并发控制(MVCC),想来也是,MVCC中不就有字段保存了事务的版本号吗.
这里有一个重要的概念 undo表
参考
error log
general_log
slow query log
relay log
undo redo
日志