谷歌技术探究之Spanner
文章目录
- 引言
- TrueTime
- 事务
- 读写事务
- 快照读
- 只读事务
- Spanner 与 BigTable
- 总结
引言
Spanner是一个全球分布式的数据库,从数据模型来看Spanner很像BigTable,都是类似于key对应着一行数据,但是却并不一样,Spanner中衍生出了“目录”的概念(把两张表合并存储)。这并不是重点,Spanner的重是它是第一个在全球范围内传递数据且保证外部一致的分布式事务的系统,且支持几种特定的事务,这显然是一个很困难的问题,我们会在文章中加以描述,这篇文章主要对Spanner的事务以及实现事务所使用的 TrueTime API 进行分析,这些也是论文中描述最为详尽,也是比较不好懂的地方。还有之所以不分析Spanner的架构是因为我觉得论文(第二节)中此方面的描述实在是有些简略,所以直接看论文就可以。
TrueTime
我们在引言中提到实现分布式下的外部一致性非常困难,Spanner引入了一个新的API巧妙的解决了这个问题,这个API可以直接暴露时钟的不确定性,简单来说,就是可以给我们一个区间,保证现在的准确时间在这个区间以内,而且这个区间很小(上下浮动7ms),这就是TrueTime。
那么为什么实现分布式下的外部一致性非常困难呢?我们举两个例子来看一看:
例1: 主从复制

这是一个非常常见的模型,我们要解决的问题是Client向master发出一个修改操作,然后直接向Slave进行查询,显然如果在CA中选择可用性的话我们可能无法在Slave中看到刚刚进行的修改,这就不满足外部一致性了,有两种方法解决这个问题:
- 在CA中选择C,但是这在绝大多数情况下是不被采取的,因为只要有一个Slave出现问题,就会导致此次数据提交无限期延长。
- 对Slave节点的读操作,我们能够判断数据是否足够新,如果数据并不是最新的,就阻塞操作,直到数据到了以后再返回,这也是我们所说的用户角度的一致性。这有一个问题,就是写入和查询两个操作的顺序如何确定(这两个操作不一定来自于一个机器),因为一般情况下分布式中的时钟是不可相信的[4],所以也这是一个问题。
例2:跨分区的事务

当Client1执行一个跨分区的事务,也就是图中向master1,master2发送两个修改操作,然后Client向master1,master2分别发送出读取请求,一般而言我们必须把读操作也封装成一个事务,否则可能会出现读取的数据一半是修改之前,一半是修改之后,要避免这种情况也意味着读操作也会加锁,这会大幅的影响性能。
我们来看看TrueTime的API:
| Method | Returns |
|---|---|
| TT.now() | TTinterval: [earliest, latest] |
| TT.after(t) | true if t has definitely passed |
| TT.before(t) | true if t has definitely not arrived |
- now()
- 返回一个时间区间(tearliest, tlatest),使得tearliest
- 论文中没有具体描述上下界的计算方法,显然若定义tearliest=tlocal-ε,tlatest=tlocal+ε是满足要求的。
- 返回一个时间区间(tearliest, tlatest),使得tearliest
- after(t)
- 当确定当前全球精确时间大于输入的时间记录时返回true,否则返回false
- before(t)
- 当确定当前全球精确时间大于输入的时间记录时返回true,否则返回false
有了这些API,实现一致性就方便了,假设“要求Client2执行的事务B一定在Client1执行的事务A之后”,使用了TrueAPI以后我们可以这么做:
- Client1,Client2协商出两个时间戳,分别是事务的提交时间,设为t1,t2。且
t2 - t1 > 2ε,其中ε为TrueTime最大偏移时间 - Client1在t1时刻提交事务A
- Client2在t2时刻提交事务B
这样我们就可以保证事务B可以看到事务A了,这样很好证明:
(tabs代表事务a的绝对时间,t1 - ε < tabs(ea) < t1 + ε)
- tabs(ea) < t1+ε
- tabs(eb) > t2-ε
- t2-t1>2ε
- 所以tabs(e1)
其中的ε为参考误差值,上限被Spanner设置为7ms,我们也可以看出精度越高,事务执行的效率就越高。
至于如此苛刻的时间需求该如何满足呢?Spanner基于GPS时钟和原子钟来实现这个功能,那么为什么要是用两种方式呢?论文中给出的解释是两种方法的失效原因并不相同,这可以最大限度的提升可用性,毕竟Spanner是一个全球性的分布式数据库。我们来看看两种方法的原理:
- 原子钟利用原子的波长测量时间,科学领域通常使用最精确的铯原子时钟,但成本也很高。而商用领域则使用精度和成本都较低的铷原子钟。无论哪种原子钟,都存在误差累积问题,即原子钟自然产生的误差是单调变化的,两个不同的原子钟授时差异会越来越大。
- GPS时钟的技术基础,仍然是每个GPS卫星上的两个互相校时的原子钟。GPS时钟终端可以通过连接多颗GPS卫星,通过算法屏蔽电磁波传输时延计算出相对精确时间。因此GPS时钟产生的误差是随机误差,即全球不同GPS时钟的时间虽然会呈现动态不一致,但误差不会越来越大。然而,GPS毕竟是第三方服务,并不能确信它在任何情况下都可用(例如发生大范围的卫星故障、电磁干扰等)。
综合以上原因,Spanner决定同时采用GPS时钟和原子钟,并且以GPS时钟为主。这样可以既避免计时误差问题,又保证了GPS失效时的可用性。
事务
Spanner中支持三种事务,分别为快照读,只读事务,读写事务,我们来看看Spanner如何利用 TrueTime API 来实现事务的特性。
读写事务
读写事务也可以只包含写事务,所以这也可以看成Spanner中对写操作的处理过程。我们会给这个事务的所有操作分配同一个时间戳(写入数据项中),我们希望所有这个读写事务提交后开始的事务的这个时间戳严格大于这个时间戳,且这个时间戳大于等于写操作的起始绝对时间,小于等于写操作commit绝对时间,流程如下:
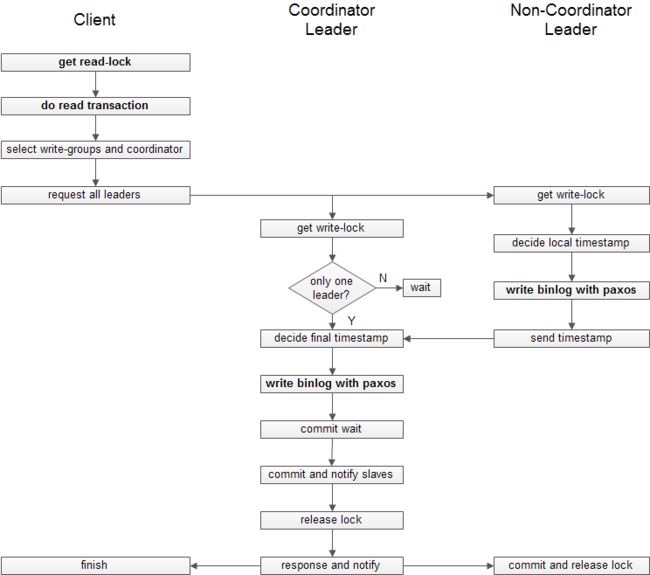
- 获取leader节点的读锁
- 如果事务中包含读操作,先进行快照读(同一事务中的读操作没办法看见写操作)
- 客户端确定写操作的所有副本组,选择一个coodinator-leader(如果客户端只确定了一个副本组,则该副本组的leader即为coodinator-leader)
- coodinator-leader执行以下操作:
1. 获取写锁
2. 等待所有非coordinator-leader的消息
3. 确定此次事务的最终时间戳,遵循以下规则:大于所有其他非coordinator-leader的时间戳,大于刚收到客户端消息时的now().latest,大于本节点所有已用时间戳,这就可以保证与本事务相关的所有节点时间戳保证递增
4. 将客户端提交的数据通过Paxos写入日志,也就是同步到副本
5. 执行commit-wait,阻塞到after(ts)==true
6. 通知slave节点提交commit
7. 释放写锁
8. 通知客户端写操作完成,同时通知非coordinator-leader进行commit - 非coodinator-leader节点执行以下操作:
1. 获取写锁
2. 确定时间戳,需要大于本节点所有已使用的时间戳
3. 将客户端提交的数据通过Paxos写入日志,即同步到副本
4. 通知coordinator-leader
5. 等待coordinator-leader回复
6. 讲日志的时间戳改为coordinator-leader的时间戳,保证全局相同
7. 通知slave节点commit
8. 释放写锁
我们可以看到读写事务的执行其实就是一个两阶段提交的过程,不过因为对每一个数据维护了时间戳,所以使得读操作可以不需要加锁,这也就在保证效率的情况下保证了读写的外部一致性。
我们说说上面提到的commit-wait,这个机制有什么用呢?
我们知道TrueTime返回的是一个时间范围,当两个范围有交集的时候我们没办法确定它们的发生顺序。因为Spanner的支持快照读的外部一致性: 如果一个事务已经提交了,而另一个事务发起了,另一个事务是看得见已提交事务的影响的,换句话说就是**如果一个事务 T2 在事务 T1 提交以后开始执行, 那么,事务 T2 的时间戳一定比事务 T1 的时间戳大。**因为Spanner支持无锁的的只读事务和快照读,如果读事务的TrueTime和上一个事务的TrueTime有交集,那么我们没办法判断它们之间的先后顺序,所以引入了commit-wait机制,那么我们让上一个事务在after(ts)以后再commit,读事务就一定与上一个事务没有交集了。
快照读
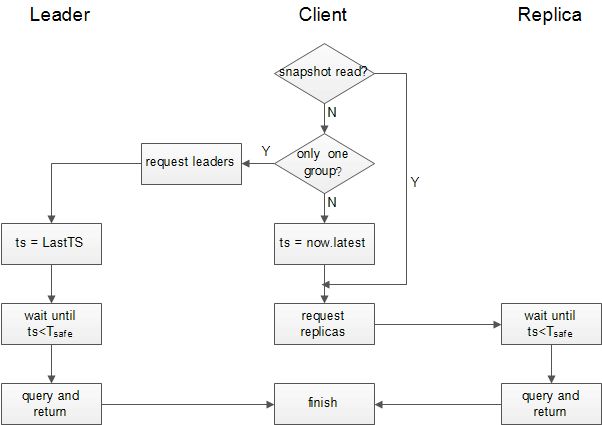
流程如下:
- 客户端指定一个时间戳ts
- 根据读请求和数据分布信息,选择与本次查询有关的副本组
- 客户端在每个group选择一个副本节点,分别发起查询请求,等待至全部完成
- 在每个所选的副本节点上,我们需要等待客户端所指的的ts小于该节点在所有正在执行的读写事务中产生的时间戳(读等待机制)(用户眼中的一致性)
因为Spanner是一个多版本的数据库,给人的感觉类似于MVCC,我们可以指定时间戳查询指定版本的数据,因为快照读引入了读等待所机制,副本节点达到足够新的状态之后才完成读取,因此即使数据复制是异步执行的,也可以保证跨副本节点的读写一致性(让人想起了zk,也是这样保证一致性的)。
只读事务
只读事务是在没有指定时间戳时的读取操作,默认就是查询当前时刻的数据,流程如下:
- 根据读请求和数据分布信息,选择与本次查询有关的副本组
- 如果所有的读操作只在一个Paxos组内部,客户端直接执行查询,时间戳设置为now.latest。
- 如果读操作分布在多个组,时间戳设置为now.latest,后续操作与快照读的步骤3,4相同
Spanner 与 BigTable
Spanner可以看作对BigTable的改进,在paper中也提到:
尽管有许多项目可以很好地使用 BigTable,我们也不断收到来自客户的抱怨,客户反映 BigTable 无法应用到一些特定类型的应用上面,比如具备复杂可变的模式,或者对于在大范围内分布的多个副本数据具有较高的一致性要求
那么它们之间有什么大的不同呢?我认为有如下几点:
-
Bigtable只支持单行事务,Spanner则可以包含任意的写操作,使用2PC来实现。我并不觉得这是BigTable的缺点,相反,这在有时可以很好的提升效率(我们并不知道在Spanner中行是否存在一个paxos group中,如果是的话效率就差不多了),BigTable也提到了仅支持单行事务的初衷:
We initially planned to support general-purpose transactions in our API. Because we did not have an immediate use for them, however, we did not implement them. Now that we have many real applications running on Bigtable, we have been able to examine their actual needs, and have discovered that most applications require only single-row transactions.
-
BigTable做到了计算和存储的分离,这使得table迁移可以不移动底层的数据。而Spanner中数据由Paxos算法保证一致性,计算和存储在一个节点中完成。前者在table server宕机时不影响数据,master会把数据重新分配。
-
数据类型不同,BigTable是标准的k/v结构,且历史版本存放在一行中;Spanner中时间戳是键的一部分。
当然还有很多其他地方,仅仅列出几个比较直观的地方
总结
其实论文对于Spanner的描述仅仅只是皮毛而已,很多重要的地方都没有讨论到,比如客户端如何确定在读或者读写事务时该向 Spanner server 内的哪些 tablt 服务器发送请求呢?在执行读写事务时锁的粒度?因为第一个问题没办法知道,为什么有这么高的可用性也就无从谈起了。但是Spanner对我们来说仍旧是一个很好的学习资料,因为它使用一个新的API做到了实现大范围分布式的外部一致性,且吞吐量并不差(异步的复制仍可保证读写一致性),打破了我对这个问题的固有认知。且事务的实现采用了2PC(2PC本身是有问题的,比如单点故障,数据不一致),这也是第一次见到2PC实际使用。
Spanner也给我了一个另外一种看CAP的角度,Spanner声称自己达到了CA,当然我们知道严格从技术上来说这是不可能的,Spanner从原理上来说这是一个CP的系统,但是Spanner称为CA的最主要因素就是,用户是否认可它的可用性,如果可用性够高,用户有时是可以忽略掉这个中断的,况且就算出现分区也不一定对用户有影响,而Spanner的可用性是超过5个9的。
参考:
- 论文《Spanner: Google’s Globally-Distributed Database》
- 博文《Spanner技术分析》
- 博文《深入理解Spanner事务》
- 博文《构建可靠分布式系统的挑战》
- 博文《谈谈Spanner和F1》
- 博文《spanner与bigtable》
- 博文《Bigtable设计的”得”与”失”》
- 博文《GOOGLE分布式数据库技术演进研究–从Bigtable、Dremel到Spanner(一)》
- 博文《GOOGLE分布式数据库技术演进研究–从Bigtable、Dremel到Spanner(三)》
http://www.nosqlnotes.com/