Mysql日志抽取与解析
1. 摘要:
![]()
3.2 mysql 日志协议
4. 位点确认机制
![]()

5. tracker设计
6. parser 设计
7. 重连机制
Mysql日志抽取与解析正如名字所将的那样,分抽取和解析两个部分。这里Mysql日志主要是指binlog日志。二进制日志由配置文件的log-bin选项负责启用,Mysql服务器将在数据根目录创建两个新文件XXX-bin.001和XXX-bin.index,若配置选项没有给出文件名,Mysql将使用主机名称命名这两个文件,其中.index文件包含一份全体日志文件的清单。Mysql会把用户对所有数据库的内容和结构的修改情况记入XXX-bin.n文件,而不会记录SELECT和没有实际操作意义的语句。2. 设计概要:
本项目主要包括两个独立的模块:1、日志抽取(mysql-tracker);2、日志解析(mysql-parser)。日志抽取主要负责与mysql进行交互,通过socket连接以及基于mysql的开源协议数据报文,来进行从mysql主库上dump相应的日志数据下来。而日志解析主要负责与日志抽取模块交互,通过将dump下来的bytes类型的数据,根据mysql协议,对bytes数据进行解析,并封装成易读的event对象。2.1 流程概要:
mysql-tracker 总体流程设计:tracker与mysql交互:1. 建立socket连接2. 加载上次退出时的位点信息(从checkpoint表中加载)3. 利用socket连接发送基于mysql协议的数据包+checkpoint表中的位点信息,创建mysql主库的binlog dump线程4. 利用socket接受(监听)mysql主库传过来的数据包5. 解析数据包(有多种形式,OK包,EOF包,ERROR包,EVENT包等等)6. 如果有EVENT包,将基于byte的数据包解析成event对象7. 将对象存入List或Queue里面tracker与hbase交互:1. 从queue中接收固定量数据(上限:防止内存溢出,下限:防止频繁I/O),或固定时间数据(防止内存溢出)。2. 这里的数据就是event对象3. 将event对象序列化,存入hbase(protobuf 和 entry)4. 存入过程中,保证位点确认机制,如果有关于mysql binlog 的标志性位点,则将该event存入hbase后(注意这里有对特殊xid位点的确认机制,而parser是没有的,直接确认即可),然后再将该event的位点信息存入checkpoint表(维护各种位点信息:包括mysql binlog位点,event表(存如序列化后的event)位点,entry表(存入反序列化后的event)位点)5. 也就是说只要是存入hbase实体数据,都要伴随位点确认机制。这里tracker确认两个方面的位点:mysql binlog 位点(xid:binlog file name + next position) + event表位点(tracker写位点:row key)tracker 每分钟记录位点:
mysql-parser 总体流程设计:(设计思路非常类似,只不过是mysql binlog变成了event表,parser fetch数据从这里fetch)1. 每分中固定时间记录确认的checkpoint位点(可能有重复,长时间没有数据fetch重复最多)
parser与event表交互:1. 建立hbase连接2. 加载上次退出的位点信息(从checkpoint表中加载)3. 通过hbase连接+checkpoint表中的位点信息,不断监听event表一旦event表有更新,就从event表中把序列化的event fetch下来4. 得到的序列化event(bytes) 存入List或Queue里面。parser与hbase交互:1. 从queue中接收固定量数据(上限:防止内存溢出,下限:防止频繁I/O),或固定时间数据(防止内存溢出)。2. 将序列化的event(bytes)反序列化成entry(其实就是event对象)3. 将entry存入hbase。4. 存入过程中,伴随位点确认机制(直接确认位点,不需要特殊位点确认机制)(存入位点信息到checkpoint表中去:parser 读 event表的位点(row key) + parser 写entry表的位点(row key))parser每分钟确认位点:1. 每分钟固定时间记录确认的checkpoint位点(可能有重复,长时间没有数据fetch重复最多)
2.2 架构

tracker 与 parser都有同样的3个线程结构 取数据线程、消费数据线程、每分钟记录线程。并且每个消费数据线程必定伴随着位点确认的机制,就如前面2.1流程概要所说:
1、tracker的位点确认机制需要有xid的特殊event作为mysql主库的位点确认点。3. mysql 相关
2、而hbase里面的位点确认除了tracker写位点也需要是xid的event作为位点确认点,其他确认点没有特殊位点的要求。
主要涉及到mysql的通讯协议和mysql 日志协议。mysql通讯协议,这里主要是利用到与mysql交互中的收发数据包的解析;mysql日志协议,这里主要是利用受到数据包后得到event事件的数据包,然后解析event数据包会用到相关的日志协议。即前者主要用在mysql交互、数据收发上面;后者主要用于日志解析、数据封装上面。3.1 mysql 通讯协议
mysql通讯协议主要用于mysql客户端与mysql服务端的交互,通讯协议通过SSL加密通讯、数据包压缩通讯、连接阶段的强交互性。3.1.1 mysql数据包
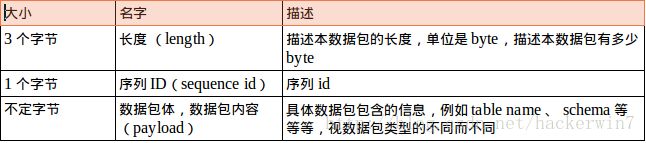
如果客户端要和服务端交互,他们会把数据打包成数据包的形式然后通过发送数据包的形式,实现信息的传递。数据包的具体格式如下:
例如一个COM_BINLOG_DUMP类型的数据包的payload(数据包体)是这样的:
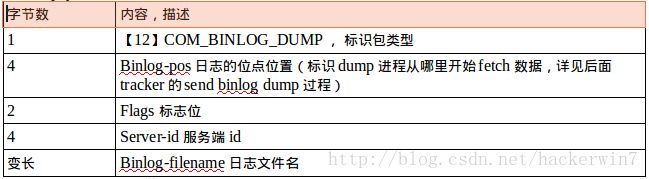
3.2 mysql 日志协议
binlog日志是一个对于mysql记录各种变化的日志集合,开启日志功能可以通--log-bin 选项来开启。MySQL的二进制日志可以说或是MySQL最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是失误安全型的.3.2.1 event事件
MySQL的二进制日志的作用是显而易见的,可以方便的备份这些日志以便做数据恢复,也可以作为主从复制的同步文件。
mysql通过C++的类来描述事件的基本类型 log event,在这里我们可以通过mysql源码的log_event.cc来详细了解 各种各样的event事件类型。log event是一个描述事件的基本类型,更加细致的log event 组成了基本的log event,即log event是可派生的,并派生处了一些描述事件信息更详细的子事件类型。比如row event就是一个母事件类型。在mysql源码中是通过一系列枚举整数值来描述各个事件的,如下所示:
enum Log_event_type {UNKNOWN_EVENT= 0,START_EVENT_V3= 1,QUERY_EVENT= 2,STOP_EVENT= 3,ROTATE_EVENT= 4,INTVAR_EVENT= 5,LOAD_EVENT= 6,SLAVE_EVENT= 7,CREATE_FILE_EVENT= 8,APPEND_BLOCK_EVENT= 9,EXEC_LOAD_EVENT= 10,DELETE_FILE_EVENT= 11,NEW_LOAD_EVENT= 12,RAND_EVENT= 13,USER_VAR_EVENT= 14,FORMAT_DESCRIPTION_EVENT= 15,XID_EVENT= 16,BEGIN_LOAD_QUERY_EVENT= 17,EXECUTE_LOAD_QUERY_EVENT= 18,TABLE_MAP_EVENT = 19,PRE_GA_WRITE_ROWS_EVENT = 20,PRE_GA_UPDATE_ROWS_EVENT = 21,PRE_GA_DELETE_ROWS_EVENT = 22,WRITE_ROWS_EVENT = 23,UPDATE_ROWS_EVENT = 24,DELETE_ROWS_EVENT = 25,INCIDENT_EVENT= 26,HEARTBEAT_LOG_EVENT= 27,ENUM_END_EVENT/* end marker */};
具体各种事件含义的详细说明可以参照mysql官方说明文档: http://dev.mysql.com/doc/internals/en/event-meanings.html3.2.2 event 事件结构
接下来我们来看看一个通用事件的具体结构(参照mysql packet 数据包)
所有的event 都含有如下通用的事件结构:+===================+| event header |+===================+| event data |+===================+分别由时间头和时间体组成。
而事件的内部结构随mysql的版本不同而变化着,这里取出3个代表性的版本结构:v1 :用于mysql 3.23v3 :用于mysql 4.01v4 :用于mysql 5.0 及 以上v1 的event 结构:+=====================================+| event | timestamp 0 : 4 || header +----------------------------+| | type_code 4 : 1 || +----------------------------+| | server_id 5 : 4 || +----------------------------+| | event_length 9 : 4 |+=====================================+| event | fixed part 13 : y || data +----------------------------+| | variable part |+=====================================+v3 的 event 结构 :+=====================================+| event | timestamp 0 : 4 || header +----------------------------+| | type_code 4 : 1 || +----------------------------+| | server_id 5 : 4 || +----------------------------+| | event_length 9 : 4 || +----------------------------+| | next_position 13 : 4 || +----------------------------+| | flags 17 : 2 |+=====================================+| event | fixed part 19 : y || data +----------------------------+| | variable part |+=====================================+v4 的event结构:+=====================================+| event | timestamp 0 : 4 || header +----------------------------+| | type_code 4 : 1 || +----------------------------+| | server_id 5 : 4 || +----------------------------+| | event_length 9 : 4 || +----------------------------+| | next_position 13 : 4 || +----------------------------+| | flags 17 : 2 || +----------------------------+| | extra_headers 19 : x-19 |+=====================================+| event | fixed part x : y || data +----------------------------+| | variable part |+=====================================+更详细的事件包数据可见: http://dev.mysql.com/doc/internals/en/event-header-fields.html相关页面
4. 位点确认机制
在于mysql的交互过程中发现,xid event通常是作为一个事务的结尾(DML,DDL的话是Query作为结尾),现将DML和DDL的事件组成展示出来(过滤掉一些对解析日志无意义的事件):4.1 确认位点分类:
DML:1. QUERY EVENT2. TABLE MAP EVENT3. ROWS EVENT4. XID EVENTDDL:1. QUERY EVENT这里我们可以通过一定的辨识机制将DDL的QUERY EVENT 和 DML的XID EVENT归为一类,所以我们把这种结束事务的时间统称为特殊xid 事件。从调试中可以得到这样一个推论:
在与mysql交互中,binlog dump线程的起始位点一定要是特殊xid事件的next position的。即特殊xid一定要作为mysql的结束标识,读时候一定要确认这里的位点机制。
所以在tracker重启,重新抓取数据时一定要从xid开始fetch数据,这样就是位点确认机制的由来。
目前的位点确认机制有:1. mysql的位点确认,必须是以xid位点来确认的,所以checpoint表存储mysql位点信息的数据必须要是特殊xid事件2. 写event表的checkpoint位点确认,受mysql位点特殊xid的影响,这里checkpoint表中tracker写event表的位点信息也必须是特殊xid的位点信息。(考虑这样一种场景,大事务里面有很多个event,如果tracker在写event表是crash掉了,这样我们可以把大事务的第一个时间a[0] 到发生crash的时间a[i]成为脏数据,为什么呢??,因为如果重启tracker,他与mysql的交互特性是必须要以xid作为起始位点才开始fetch event数据,所以我们tracker会又从这个大事务的a[0]开始fetch,如果hbase event不以xid作为位点确认,那么这次event表就变成a[0]......a[i] a[0] …..a [j] ,这样a[0]......a[i]成了明确的脏数据,如果是以xid作为tracker写event的位点确认,实际上就是重写了一段a[0]......a[i]的数据,当然你可已在tracker fetch a[0]到a[i]这一段,先不写hbase,到crash的位点再开始写hbase也是可以的。注意这里有无限循环的bug漏洞)3. 除以上两个的位点,其他位点的确认均采取直接确认,不需要考虑特殊xid事件。
大致有以下几类位点需要确认:
5. tracker设计
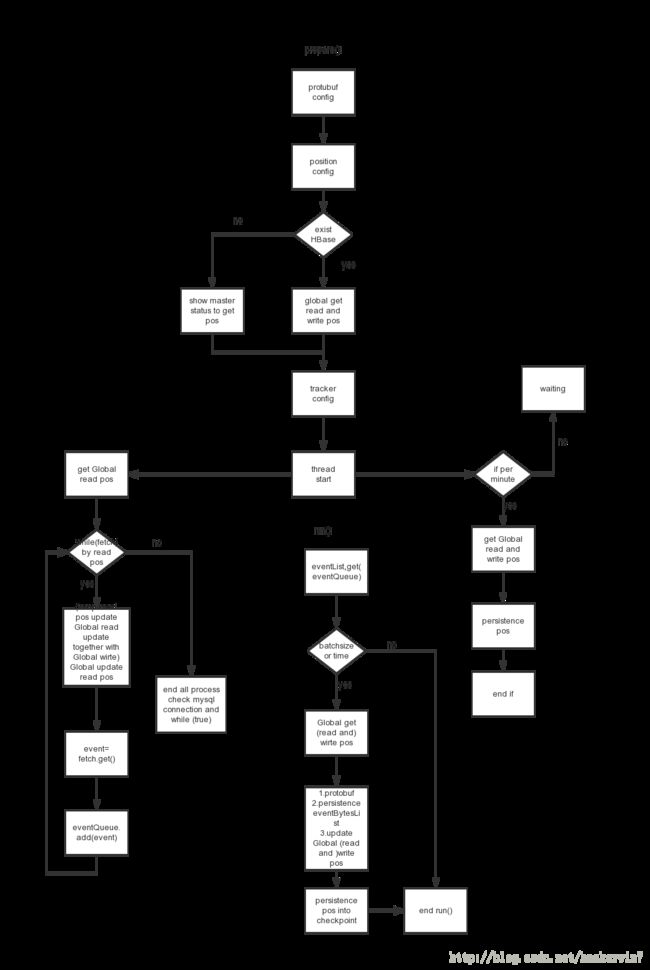
依照2.1的流程概要设计,其流程图如下所示:
这部分可以结合源代码理解(Handler1.java)1. prepare方法:1. 建立mysql的两个连接,其中一个连接用于fetch event数据,另外一个连接用于fetch表结构元数据。这里如果创建连接不成功,将一直处于创建连接流程。保证程序的存活不依赖与mysql的存活2. 建立hbase连接,这里如果hbase没有启动会处于阻塞和重连的状态。3. 加载起始位点,既有mysql的起始位点也有event表的其实位点,注意这两个位点都是受xid影响的位点,如果hbase没有相关信息,这里我们用show master status的mysql命令,让mysql位点处于本库的最末端,而让event表位点置0,即相当于清除所有数据,从0开始。4. 启动fetch 线程,开始从mysql主库上fetch event数据。5. 启动per minute 线程,开始每分中记录相应位点6. 启动persistence 线程,开始接受fetch到的event数据,并且序列化,然后存入hbase event表中,并且伴随位点确认机制。(注意:这个线程其实就是Handler.run()方法,实际上run()方法也是一个线程的机制,只不过对Handler是不可见的而已)2. fetch 线程:1. preRun方法做一些初始化工作,包括设置binlog dump线程参数、send binlog dump让fetch指针置为到起始位点(start position)、初始化数据抓取器fetcher2. fetch方法,抓取一条event数据。3. 加入queue多线程队列中4. kafka监控相关5. 这里fetch是一个循环重连的机制,入股fetch方法失败跳出第一层循环,通过外层循环和checkMysqlConn()方法时间fetch线程重连mysql。即如果fetch中途mysql crash掉,fetch线程会等待mysql有效后重连mysql。
3. Per minute 线程:1. 每分钟执行一次run方法2. 具体是将得到的存储位点的全局变量存入checkpoint中去。注意row key的设计4. Persistence 线程 Handler1.run()方法:1. 接受多线成queue的数据到list中,以此位一批数据,2. 以数量的上限,下限和时间的阀值来判断时候执行一批数据的持久化3. 进行持久化。4. 将一批event数据 序列化 然后 tracker写入到event表中去。5. 伴随位点确认机制:当真正写入event表数据成功后,看这一批数据是否有特殊xid事件,如果有则作为位点确认,写入checkpoint表中去(tracker整体重启,启动的时候加载这个位点信息)
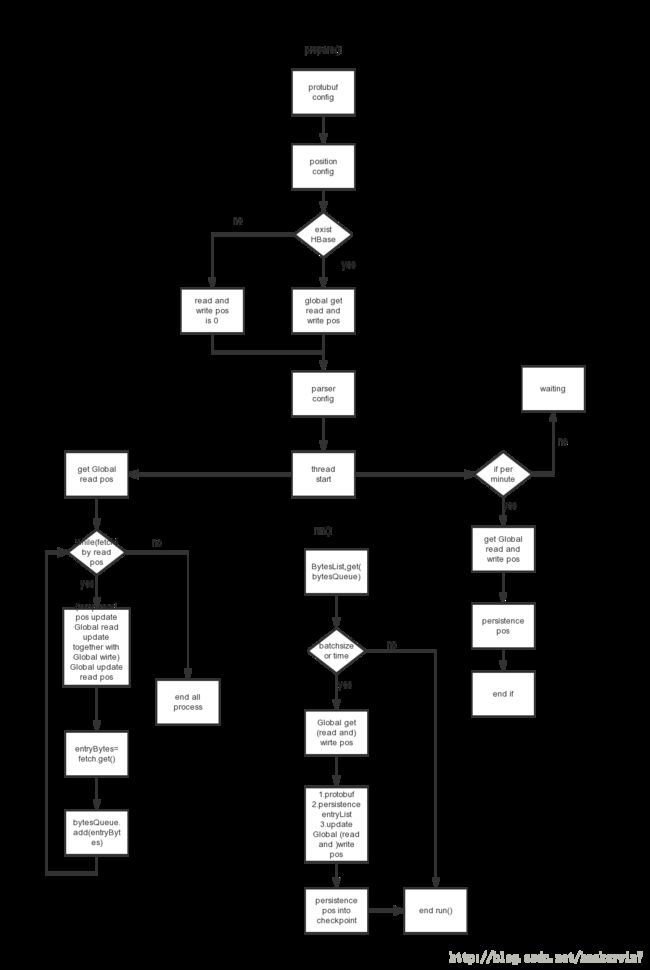
6. parser 设计
与tracker设计思路基本相同,不过是fetch的目的mysql换成hbase event表,以及位点信息的直接确认,不需要考虑特殊xid。这里不再详述。
注意:所有的位点确认一定要是在持久化成功之后才开始位点确认。
7. 重连机制
tracker中的mysql connector建立过程加入重连与等待机制。8. 性能评测
fetch线程中加入了正在fetch数据,mysql突然断掉的重连机制。
hbase的断掉的自身重连机制
目前尚未进行系统性的,正式的性能测试。9. bug与优化
仅以单机作测试有 每1-2秒 tracker能fetch 1万条数据,parser 每1万条数据 需要耗时4~5秒左右。
本单机测试尚不能作为评测标准,其性能以机器的硬件性能的不同而不同,不能以此作为性能标准。
1. 对于巨大事务的海量事件的场景,可能存在潜在的无限循环bug,即到事件a[i] crash掉,然后重启,重新fetch时 到 时间 a[i]再一次crash,然后再重启,这样一直不停地循环,永远扫描不完着一个巨量的大事务。10. 结论
2. tracker与parser的数据交接目前仍是单线程的模式,可以考虑大规模分布式并行的模式,使tracker与parser在数据交接上能够提升效率(与mysql的交接,与hbase的交接)。
基于单机的,传统的,mysql解析就到这里,主要是利用了mysql的协议进行数据传递与解析,后面组件考虑基于分布式的,基于大规模并行化的,基于高HA的模式。
11. 项目地址
https://github.com/hackerwin7/mysql-tracker
https://github.com/hackerwin7/mysql-parser