从0开始学习spark(7)SparkCore 核心知识复习与核心机制详解
Spark零基础入门第七课
- Spark 的核心概念 :
- Spark 运行架构特点
- Spark运行架构图:
- spark stage 阶段划分算法图:
- spark-on-yarn 模式图:
- sparkContext的构建的过程
- Spark MasterHA机制
- Worker节点的原理

没有看前面的同学可以回顾一下:**
6.Spark共享变量之累加器和广播变量的使用!!!
5.RDD常用算子用法训练(附习题答案)(aggregateByKey与combineByKey)!!!
4.Spark Rdd常用算子和RDD必备知识
3.spark core 核心知识
2.spark 之 wordcount入门
1.spark 入门讲解
Spark 的核心概念 :
1、Application:表示你的应用程序,包含一个 Driver Program 和若干 Executor
2、Driver Program:Spark 中的 Driver 即运行上述 Application 的 main()函数并且创建 SparkContext,其中创建 SparkContext 的目的是为了准备 Spark 应用程序的运行环境。由 SparkContext 负责与 ClusterManager 通信,进行资源的申请,任务的分配和监控等。程序执 行完毕后关闭 SparkContext
3、ClusterManager:在 Standalone 模式中即为 Master(主节点),控制整个集群,监控 Worker。 在 YARN 模式中为资源管理器。
4、SparkContext:整个应用的上下文,控制应用程序的生命周期,负责调度各个运算资源, 协调各个 Worker 上的 Executor。初始化的时候,会初始化 DAGScheduler 和 TaskScheduler 两个核心组件。
5、RDD:Spark 的基本计算单元,一组 RDD 可形成执行的有向无环图 RDD Graph。
6、DAGScheduler:根据 Job 构建基于 Stage 的 DAG,并提交 Stage 给 TaskScheduler,其划分 Stage 的依据是 RDD 之间的依赖关系:宽依赖,也叫 shuffle 依赖
7、TaskScheduler:将 TaskSet 提交给 Worker(集群)运行,每个 Executor 运行什么 Task 就 是在此处分配的。
8、Worker:集群中可以运行 Application 代码的节点。在 Standalone 模式中指的是通过 slave 文件配置的 worker 节点,在 Spark on Yarn 模式中指的就是 NodeManager 节点。
9、Executor:某个 Application 运行在 Worker 节点上的一个进程,该进程负责运行某些 task, 并且负责将数据存在内存或者磁盘上。在 Spark on Yarn 模式下,其进程名称为 CoarseGrainedExecutorBackend,一个 CoarseGrainedExecutorBackend 进程有且仅有一个 executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task, 这样,每个 CoarseGrainedExecutorBackend 能并行运行 Task 的数据就取决于分配给它的 CPU 的个数。
10、Stage:每个 Job 会被拆分很多组 Task,每组作为一个 TaskSet,其名称为 Stage
11、Job:包含多个 Task 组成的并行计算,是由 Action 行为触发的
12、Task:在 Executor 进程中执行任务的工作单元,多个 Task 组成一个 Stage
13、SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。SparkEnv 内创建并包含 如下一些重要组件的引用。 MapOutPutTracker:负责 Shuffle 元信息的存储。 BroadcastManager:负责广播变量的控制与元信息的存储。 BlockManager:负责存储管理、创建和查找块。 MetricsSystem:监控运行时性能指标信息。 SparkConf:负责存储配置信息。
Spark 运行架构特点
1、每个 Application 获取专属的 executor 进程,该进程在 Application 期间一直驻留,并以 多线程方式运行 tasks。这种 Application 隔离机制有其优势的,无论是从调度角度看(每个 Driver 调度它自己的任务),还是从运行角度看(来自不同 Application 的 Task 运行在不同的 JVM 中)。当然,这也意味着 Spark Application 不能跨应用程序共享数据,除非将数据写入 到外部存储系统。
2、Spark 与资源管理器无关,只要能够获取 executor 进程,并能保持相互通信就可以了。
3、提交 SparkContext 的 Client 应该靠近 Worker 节点(运行 Executor 的节点),最好是在同 一个 Rack 里,因为 Spark Application 运行过程中 SparkContext 和 Executor 之间有大量的信息 交换;如果想在远程集群中运行,最好使用 RPC 将 SparkContext提交给集群,不要远离 Worker 运行 SparkContext。
4、Task 采用了数据本地性和推测执行的优化机制
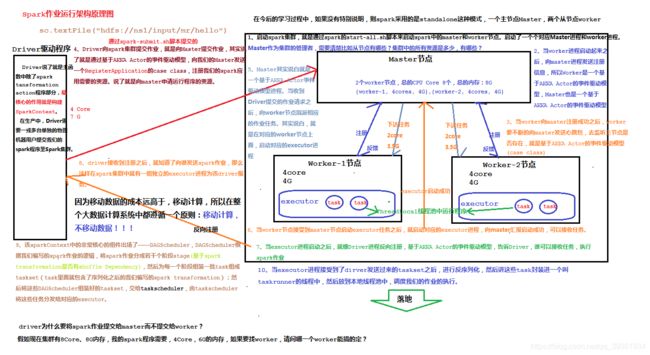
Spark运行架构图:
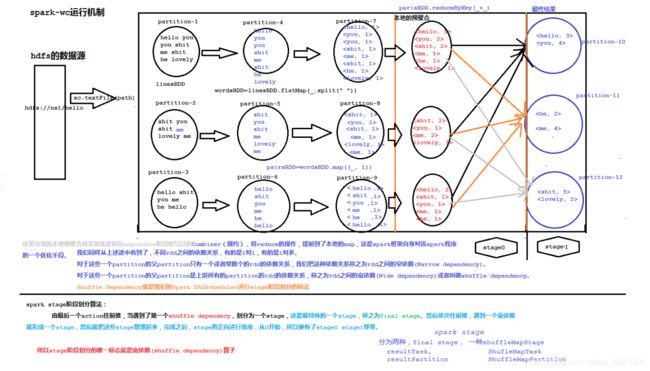
spark stage 阶段划分算法图:
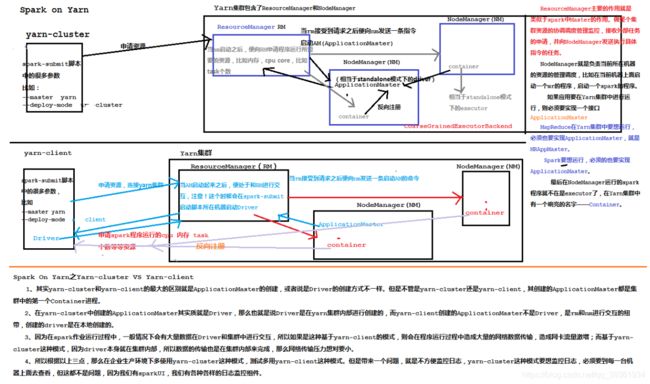
spark-on-yarn 模式图:
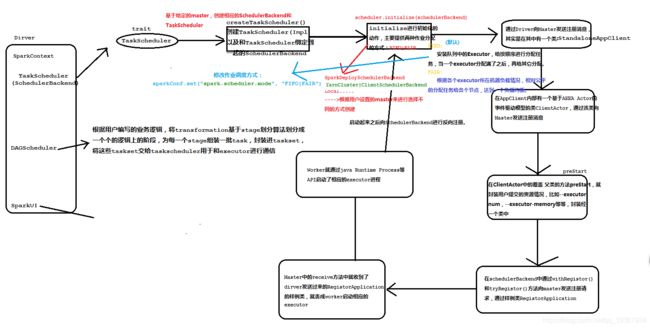
sparkContext的构建的过程
1、SparkContext 是用户通往 Spark 集群的唯一入口,可以用来在 Spark 集群中创建 RDD、累 加器 Accumulator 和广播变量 Braodcast Variable
2、SparkContext 也是整个 Spark 应用程序中至关重要的一个对象,可以说是整个应用程序 运行调度的核心(不是指资源调度)
3、SparkContext在实例化的过程中会初始化DAGScheduler、TaskScheduler和SchedulerBackend
4、SparkContext 会调用 DAGScheduler 将整个 Job 划分成几个小的阶段(Stage),TaskScheduler 会调度每个 Stage 的任务(Task)应该如何处理。另外,SchedulerBackend 管理整个集群中为这 个当前的应用分配的计算资源(Executor)
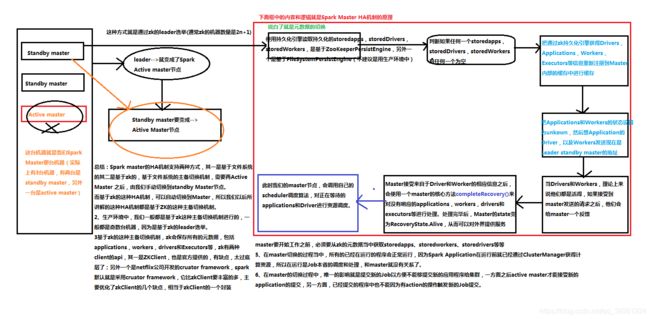
Spark MasterHA机制
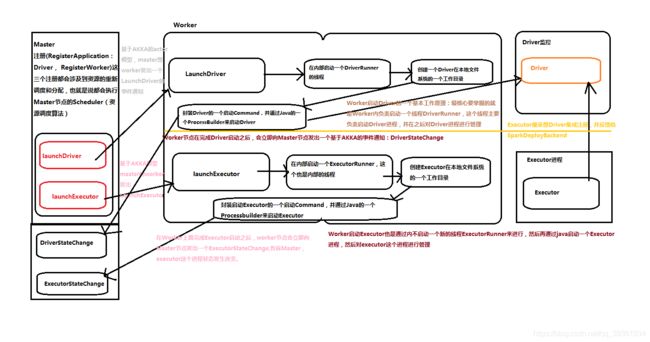
Worker节点的原理

记得点赞加关注!!! 不迷路 !!!
人活着真累:上车得排队,爱你又受罪,吃饭没香味,喝酒容易醉,挣钱得交税!