group by 的基本用法
group by做为分组来使用,后面为条件,可以有多个条件,条件相同的为一组,配合聚合函数进行相关统计。在不同数据库中用法稍有不同,这里只测试mysql和oracle。
1.准备好一张数据表:
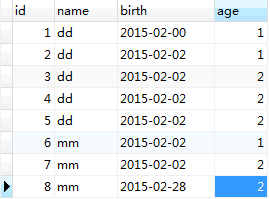
mysql oracle
2.首先以name为分组条件:
1 SELECT * FROM person 2 GROUP BY `name`;
在mysql中执行结果如下:
分析:
在mysql中没有强调select指定的字段必须属于group by后的条件。若符合条件的字段有多个,则只显示第一次出现的字段。比如:以name为dd分组,id为1,2,3,4,5,但只显示1.同理,age也只显示1.
然后,虽然这种查询在语法上通过了,但结果并没有什么意义,因为其他字段并非需要的准确值。这在oracle中就行不通了。
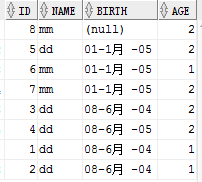
在oracle中执行结果如下:
![]()
分析:
oracle指出,select查询字段未包含在group by 的条件中。推测,首先通过select * from person可以看到oracle中id并不是升序,或者说没有默认升序。也就是查询的结果是不确定的,hash?这可能涉及到在磁盘的存储等等,这里不去深究。因此,并不能确认第一次查出来的字段的值,而且分组后不是条件的值被合并后没有意义。
结论:
group by语句中select指定的字段必须是“分组依据字段”。
因此,只能这样查询:
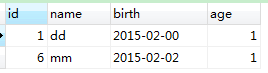
SELECT name FROM person GROUP BY name;
结果一致: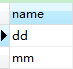 。
。
3.以name,age为查询依据,多条件分组
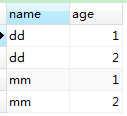
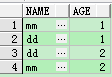
1 SELECT name,age FROM person 2 GROUP BY name,age;
结果:
mysql oracle
显然,两组的查询策略是不同的。但最终结果是相同的。都是以条件组合的笛卡尔积。也就是每个条件都一一对应。
分组依据为多条件组合成一个条件,当组合条件相同时为一组。因此,dd:1和dd:2分为两组。
4.添加聚合函数
聚合函数有如下几种:
| 函数 | 作用 | 支持性 |
|---|---|---|
| sum(列名) | 求和 | |
| max(列名) | 最大值 | |
| min(列名) | 最小值 | |
| avg(列名) | 平均值 | |
| first(列名) | 第一条记录 | 仅Access支持 |
| last(列名) | 最后一条记录 | 仅Access支持 |
| count(列名) | 统计记录数 | 注意和count(*)的区别 |
首先,要明白聚合函数的用法。比如,count(列字段值),统计该字段值出现的次数:
1 SELECT name,COUNT(*) 2 from person 3 GROUP BY name;
结果为: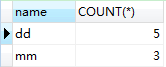 。
。
分析:
首先进行分组工作,group by name,这时8条数据被分成两组:dd和mm;然后count的作用就是统计每组里面的个数,分别是5和3.
更直观的例子:
SELECT * FROM person;
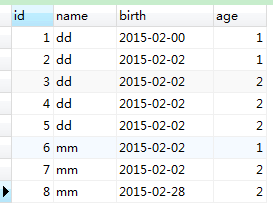
1 SELECT count(name) from person;
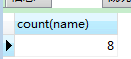 ,count(name)为统计所有的name数量,同样的结果为count(1),count(*).
,count(name)为统计所有的name数量,同样的结果为count(1),count(*).
5.where 和 having
- where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
- having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。