如何在Hadoop上跑通WordCount
先整体上说一下整个流程是怎么弄的。
首先我们需要有WordCount.java源程序,输入文档file1.txt,里面写上几行单词。接着对该源文件进行编译,编译之后打包成jar。然后把file1传到hadoop里,接着把file1、jar包扔给hadoop让他来帮我们统计每个单词出现的次数,结果输出在我们指定的路径里的part-r-00000。
下面来看具体是怎么操作的吧!
首先,需要Hadoop集群已经搭建好。我用的是1个slave(192.168.206.129),两个master(192.168.206.130/131)。
接着启动Hadoop:
cd /opt/linuxsir/hadoop/sbin
./start-dfs.sh
./start-yarn.sh
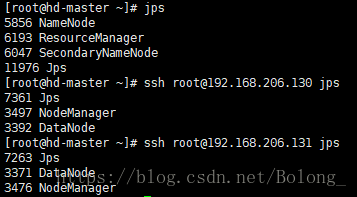
在三个节点上查看进程,验证Hadoop是否成功启动(我用的ssh无密码登陆),如果启动成功,就是下图所示。如果发现slave1和slave2上DataNode进程没有启动,可参考我之前写的一篇文章速查:搭建hadoop集群,遇到问题怎么解决(一)。,尝试解决这个问题:
jps
ssh [email protected] jps
ssh [email protected] jps
接着,准备好WordCount的java程序,我是在官网上直接拷贝来做实验的,WordCount代码 。
将拷过来的java源程序放在本地某路径上,这里我是放在了/opt/linuxsir/hadoop/share/hadoop/mapreduce里,新建了一个文件夹examples。
接着是编译.java文件:
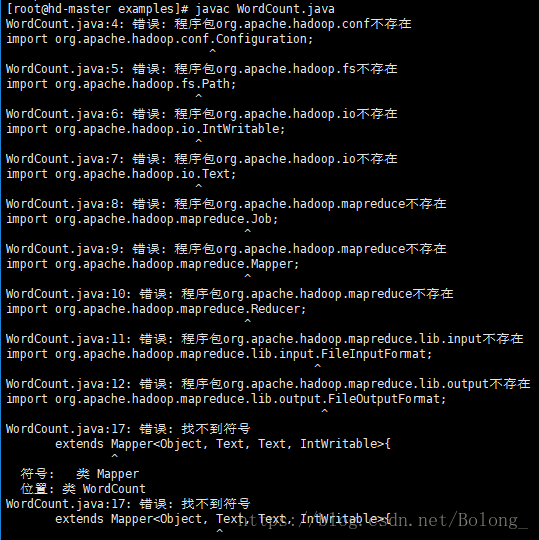
首先通过vim /etc/profile,在peofile中添加hadoop的路径,导入一些必需的hadoop的jar包,hadoop2.x版本里,需要的是下面的3个,跟hadoop1.x版本有很大的不同。(可以直接复制代码,这样分行写是为了排版,粘贴时记得把export里的换行都去掉。)接着一定不要忘了,source /etc/profile,使修改生效。
HADOOP_HOME=/opt/linuxsir/hadoop
export CLASSPATH=$JAVA_HOME/lib/tools.jar:
$JAVA_HOME/jre/lib/rt.jar:
$JAVA_HOME/lib/dt.jar:
$HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.3.jar:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.3.jar:
$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
如果没有这一步,直接编译会出现下面的错误:
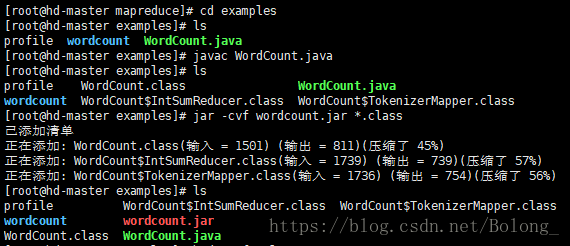
接着在存放WordCount.java的路径下,编译该文件: javac WordCount.java。
编译成功后,在当前文件夹下,会出现
WordCount.class,WordCount$IntSumReducer.class,WordCount$TokenizerMapper.class三个class程序。
接着通过jar -cvf wordcount.jar *.class,把编译后的所有class程序打包,成功后,当前文件夹下会出现wordcount.jar。(这个jar包名字的大小写取决于指令里的怎么写)
接下来把输入file1.txt传到hadoop里:
首先在hadoop里新建一个文件夹,来存放file1:hadoop fs -mkdir -p /examples/wordcount/input
接着把file1.txt传到刚才新建的路径下:hadoop fs -put file1.txt /examples/wordcount/output
还可以通过 hadoop fs -cat /examples/wordcount/input/file1.txt查看file1里到底写了什么东西。

接下来,最后一步啦。
把打包之后的wordcount.jar和输入文件所在的路径丢给hadoop,WordCount是程序执行的主函数,指定输出路径/examples/wordcount/output。
![]()
等待map和reduce执行完毕。

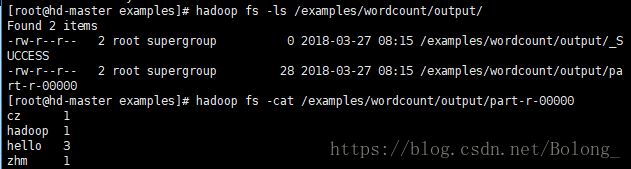
查看output,里面多出了两个文件,而我们的输出结果就在pert -r -00000里,还可以检验一下,hadoop计算的对不对,哈哈~
到这,整个过程就结束啦~
如果有出错的地方,欢迎大家指正~