python爬虫----scrapy爬虫之天气预报
说到爬虫自然离不开scrapy
那么这次就用scrapy来写一个小爬虫
这次的目标是爬取中国天气网:tianqi.com上的中国各省市当日天气情况
关于scrapy的详细操作和内容就不一一介绍了,简单说一下这次爬虫的步骤吧
操作都是在cmd里用命令行的形式输入
创建一个项目:scrapy startproject tianqi
cd tianqi 进入到这个文件夹
创建一个爬虫:scrapy genspider weather tianqi.com
然后就会在tianqi文件夹里看到一些.py的文件
spdier文件

接下来我们就要在这些.py文件中来做文章
Spider
首先最重要的是spider里的weather.py文件,
它是整个爬虫爬取数据的部分,爬到数据后会返回给PIPELINE处理
# -*- coding: utf-8 -*-
import scrapy
from tianqi.items import TianqiItem #将items导入进来,使得数据能够使用
from bs4 import BeautifulSoup
import re
class WeatherSpider(scrapy.Spider):
name = 'weather'
allowed_domains = ['tianqi.com']
start_urls = ['http://www.tianqi.com/chinacity.html']#列表里是要爬取的url
def parse(self, response):
soup = BeautifulSoup(response.text,'html.parser')
province = soup.find_all('select',attrs = {'onchange':'getcity(this.value)'})[0]
all_province = re.findall(r'py="(.*?)"',str(province))
special_city = ['beijing','aomen','tianjin','hongkong','shanghai','chongqing']
#比较特殊的几个城市,分情况返回不同的函数
for i in all_province:
try:
if i in special_city:
url = 'http://'+ str(i) + '.tianqi.com/'
yield scrapy.Request(url,callback = self.parse_city)#返回给parse_province来处理
else:
url = 'http://www.tianqi.com/province/'+ str(i) +'/'
yield scrapy.Request(url,callback = self.parse_province)#返回给parse_city来处理
except:
continue
#对省份操作
def parse_province(self,response):
soup1 = BeautifulSoup(response.text,'html.parser')
city = soup1.find_all('select',attrs = {'onchange':'getzone(this)'})[0]
all_city = re.findall(r'py="(.*?)"',str(city))
for i in all_city:
try:
url = 'http://'+ str(i) + '.tianqi.com/'
yield scrapy.Request(url,callback = self.parse_city)#返回给parse_city来处理
except:
continue
#对市操作
def parse_city(self,response):
soup2 = BeautifulSoup(response.text,'html.parser')
tq = soup2.find_all('div',attrs = {'class':'tqshow'})[0]
pattern = re.compile(r'(.*?) .*?(.*?)~(.*?).*?(.*?) .*?(.*?) .*?',re.S)
#还是那个老问题,最后匹配的部分,解析出来的代码和自己在网页上看到的顺序不同
content = re.findall(pattern,str(tq))[0]
item = TianqiItem()
item['city'] = content[5]
item['date'] = content[0]
item['high_temp'] = content[1]
item['low_temp'] = content[2]
item['weather'] = content[3]
item['wind'] = content[4]
yield item#这个item要交给pippelines.py来处理数据如果要爬取的页面要一页页点进去的那种就需要,弄几个像def parse_province(self,response)这样的函数,
在parse中用yield scrapy.Request返回爬到的数据
如果对scrapy.Request不是太清楚,可以看看这个文章https://my.oschina.net/lpe234/blog/342741,
上面有关于spider的scrapy的官方文档的详细介绍
Items.py
然后就是items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
#创建一个类似于字典的东西,把需要获取字段的名字写入,并在需要用到的时候引入这个类
class TianqiItem(scrapy.Item):
city = scrapy.Field()
date = scrapy.Field()
high_temp = scrapy.Field()
low_temp = scrapy.Field()
weather = scrapy.Field()
wind = scrapy.Field()Pipelines.py
接下来就是处理数据的部分了,一般来说都是用来如何储存数据
pipelines.py就是用来处理爬取的数据、
这里就用简单的txt文件形式来储存
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import os
class TianqiPipeline(object):
def process_item(self, item, spider):
fpath = 'E:/python/weather.txt'
with open(fpath,'a') as f:
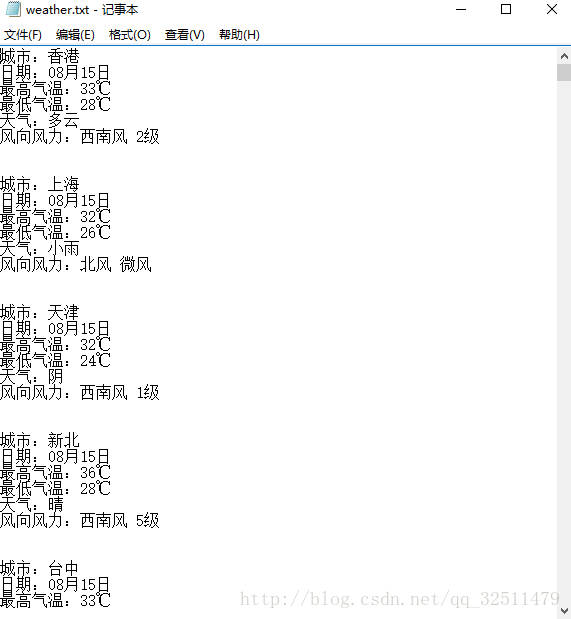
f.write('城市:' + item['city'] + '\n')
f.write('日期:' + item['date'] + '\n')
f.write('最高气温:' + item['high_temp'] + '\n')
f.write('最低气温:' + item['low_temp'] + '\n')
f.write('天气:' + item['weather'] + '\n')
f.write('风向风力:' + item['wind'] + '\n')
f.write('\n\n')
return item若还想有其他的储存形式,则可以在TianqiPipeline类中加方法,然后在settings.py中写入这个方法就行了
Setting.py
最后是settings.py,它的主要功能就是使爬虫运行起来,
当然我们需要把在Pipeline中写的方法添加进去,它才可以按照方法运行。

我们只需要修改ITEM_PIPELINES就可以了,把在Pipeline写的方法写入
后面的数字越小代表最先处理
结果展示:
让我们来看下结果吧