DolphinScheduler-1.3.0-dev新功能尝鲜
1
DolphinScheduler是什么
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
DS曾用名称EasyScheduler,在进入Apache孵化器后,更名为DolphinScheduler。DS-1.2.0版本是进入Apache基金会后发布的第一个Apache版本,也是目前生产环境使用较多的版本。
最近,DS-1.3.0在封版进行测试和bug修复工作,即将ga,各位敬请期待。
本文较长,前半部分是组件部署,功能测试在后半部分,木有耐心的老铁可以直接阅读后面的内容。
官网
https://dolphinscheduler.apache.org/en-us/
github
https://github.com/apache/incubator-dolphinscheduler
ds-1.3.0特性及RoadMap录播
https://www.slidestalk.com/DolphinScheduler/Dolphin_Scheduler_Roadmap?video
2
DS-1.3.0新特性
架构调整
Master-Worker直接通信,降低延迟
去除Worker的DB操作,职责更单一
减轻DB元数据库的压力,减少极端情况下可能的调度延时
Master添加多种任务分发策略
随机
轮询
CPU和内存线性加权
新增任务类型
数据同步节点
DataX
Sqoop
条件分支节点
易用性
提供Ambari插件
支持k8s
资源中心目录化
其他特性(部分)
适配Windows任务
工作流复制
删流程实例级联删除任务日志
简化配置,优化部署体验
3
DS-1.3.0部署(CDH5.16.2)
集群环境
CDH5.16.2
DS源码编译
代码拉取
git clone https://github.com/apache/incubator-dolphinscheduler.git适配CDH5.16.2
创建CDH分支
git checkout dev-1.3.0
git checkout -b dev-1.3.0-cdh5.16.2适配CDH5.16.2
修改外层pom文件
# 修改hadoop版本,也可以不修改
2.6.0
# 修改hive版本,必须进行调整
1.1.0
# 修改打包的version(所有模块均需要进行修改)
1.3.0-cdh5.16.2 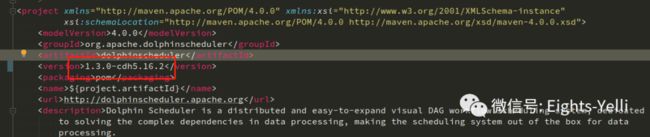
源码编译
mvn -U clean package -Prelease -Dmaven.test.skip=true正常编译完成后,会在dolphinscheduler-dist下生成:
apache-dolphinscheduler-incubting-1.3.0-cdh5.16.2-dolphinscheduler-bin.tar.gz。从1.2.1开始,ds打包之后并不会生成前端的tar.gz文件

组件部署
准备工作
创建部署用户免密(部署机都需要做)
# 添加部署用户
useradd dscheduler;
# 设置密码
echo "dscheduler" | passwd --stdin dscheduler
# 配置免密
echo 'dscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' >> /etc/sudoers
# 切换到部署用户并生成ssh key
su dscheduler;
ssh-keygen -t rsa;
ssh-copy-id -i ~/.ssh/id_rsa.pub dscheduler@[hostname];创建MySQL数据库
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE
utf8_general_ci;
CREATE USER 'dscheduler'@'%' IDENTIFIED BY 'dscheduler';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dscheduler'@'%' IDENTIFIED BY 'dscheduler';
flush privileges;部署实施
上传安装包

解压安装包&修改权限
# /u01 为存放ds安装包的目录,跟根据实际情况进行调整
tar -zxvf apache-dolphinscheduler-incubating-1.3.0-cdh5.16.2-dolphinscheduler-bin.tar.gz -C /u01
# 改一波目录名称
mv apache-dolphinscheduler-incubating-1.3.0-cdh5.16.2-dolphinscheduler-bin.tar.gz ds-130-backend
# 修改所属用户和权限
chmod -R 755 ds-130-backend;
chown -R dscheduler:dscheduler ds-130-backend;ds安装包各目录功能如下

bin - 服务启动脚本
conf - 配置文件目录
DISCLAIMER
install.sh - 一键部署脚本
lib - 依赖的jar包
LICENSE
licenses
NOTICE
script - 集群启动停止,更新数据库等脚本
sql - sql文件
ui - 前端UI初始化元数据库
ds默认的元数据库是pg,Hadoop平台一般使用mysql作为元数据,这里使用mysql
需要上传mysql的连接jar到ds的lib目录下,必须要做

修改数据库配置
vi /u01/ds-130-backend/conf/datasource.properties;
# 修改pg为mysql 填写刚才配置的数据库用户密码
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://xxxxxx:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8
spring.datasource.username=xxxxxx
spring.datasource.password=xxxxxx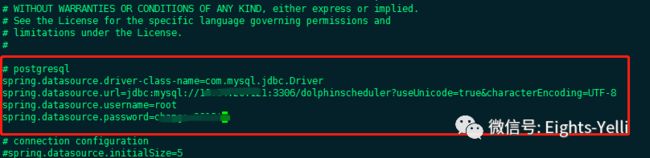
初始化数据库
./script/create-dolphinscheduler.sh![]()
配置ds的环境变量
vi /u01/ds-130--backend/conf/env/dolphinscheduler_env.sh
# 测试集群上没有datax和flink请忽略相关配置
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH/lib/hadoop/etc/hadoop
export SPARK_HOME1=/opt/cloudera/parcels/CDH/lib/spark
export SPARK_HOME2=/opt/cloudera/parcels/SPARK2/lib/spark2
export PYTHON_HOME=/usr/local/anaconda3/bin/python
export JAVA_HOME=/usr/java/jdk1.8.0_131
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export FLINK_HOME=/opt/soft/flink
export DATAX_HOME=/opt/soft/datax/bin/datax.py集群部署参数配置
ds在1.3.0之前,一键部署的配置文件在install.sh中。1.3.0版本的install.sh脚本只是一个部署脚本,部署配置文件在conf/config/install_config.conf中
下面是1.3.0的配置文件,与之前版本的配置文件相比,精简了不少,只保留了必要的配置,如果是从老版本升级,需要自行去对应的模块配置文件中进行修改
对比1.2.0配置文件中去除的配置如下(升级需要关注,新版本建议各位老铁细看一下配置的变更项,这次测试的1.3.0的dev版本,正式版本ga之后会出一个详细的配置解读)
excel文件路径 xlsFilePath -> alert.properties | xls.file.path
alert master worker api模块的配置 -> 对应模块的properties文件修改
执行任务配置 -> conf/common.properties修改
programPath
downloadPath
execPath
开发状态 devState -> conf/common.properties修改
zk的连接配置和znode相关配置,如果使用一套zk托管了多套ds,需要自行修改配置 -> conf/zookeeper.properties
配置文件中,在配置worker机器的时候,需要在后面配置上worker的所属worker group,这是因为在新版本中,worker group分组信息从mysql移动到了zk中
# NOTICE : If the following config has special characters in the variable `.*[]^${}\+?|()@#&`, Please escape, for example, `[` escape to `\[`
# postgresql or mysql
dbtype="mysql"
# db config
# db address and port
dbhost="xxxx:3306"
# db username
username="xxxx"
# database name
dbname="dolphinscheduler"
# db passwprd
# NOTICE: if there are special characters, please use the \ to escape, for example, `[` escape to `\[`
password="xxxx"
# zk cluster
zkQuorum="xxx:2181,xxx:2181,xxx:2181"
# Note: the target installation path for dolphinscheduler, please not config as the same as the current path (pwd)
installPath="/opt/ds-1.3.0-dev-agent"
# deployment user
# Note: the deployment user needs to have sudo privileges and permissions to operate hdfs. If hdfs is enabled, the root directory needs to be created by itself
deployUser="dscheduler"
# alert config
# mail server host
mailServerHost="xxx"
# mail server port
# note: Different protocols and encryption methods correspond to different ports, when SSL/TLS is enabled, make sure the port is correct.
mailServerPort="25"
# sender
mailSender="xxx"
# user
mailUser="xxx"
# sender password
# note: The mail.passwd is email service authorization code, not the email login password.
mailPassword="xxx"
# TLS mail protocol support
starttlsEnable="false"
# SSL mail protocol support
# only one of TLS and SSL can be in the true state.
sslEnable="false"
#note: sslTrust is the same as mailServerHost
sslTrust="xxx"
# resource storage type:HDFS,S3,NONE
resourceStorageType="HDFS"
# if resourceStorageType is HDFS,defaultFS write namenode address,HA you need to put core-site.xml and hdfs-site.xml in the conf directory.
# if S3,write S3 address,HA,for example :s3a://dolphinscheduler,
# Note,s3 be sure to create the root directory /dolphinscheduler
defaultFS="hdfs://master.eights.com:8020"
# if resourceStorageType is S3, the following three configuration is required, otherwise please ignore
s3Endpoint="http://192.168.xx.xx:9010"
s3AccessKey="xxxxxxxxxx"
s3SecretKey="xxxxxxxxxx"
# if not use hadoop resourcemanager, please keep default value; if resourcemanager HA enable, please type the HA ips ; if resourcemanager is single, make this value empty
yarnHaIps="192.168.xx.xx,192.168.xx.xx"
# if resourcemanager HA enable or not use resourcemanager, please skip this value setting; If resourcemanager is single, you only need to replace yarnIp1 to actual resourcemanager hostname.
singleYarnIp="master.eights.com"
# resource store on HDFS/S3 path, resource file will store to this hadoop hdfs path, self configuration, please make sure the directory exists on hdfs and have read write permissions。/dolphinscheduler is recommended
resourceUploadPath="/dscheduler"
# who have permissions to create directory under HDFS/S3 root path
# Note: if kerberos is enabled, please config hdfsRootUser=
hdfsRootUser="hdfs"
# kerberos config
# whether kerberos starts, if kerberos starts, following four items need to config, otherwise please ignore
kerberosStartUp="false"
# kdc krb5 config file path
krb5ConfPath="$installPath/conf/krb5.conf"
# keytab username
keytabUserName="[email protected]"
# username keytab path
keytabPath="$installPath/conf/hdfs.headless.keytab"
# api server port
apiServerPort="12345"
# install hosts
# Note: install the scheduled hostname list. If it is pseudo-distributed, just write a pseudo-distributed hostname
ips="master.eights.com"
# ssh port, default 22
# Note: if ssh port is not default, modify here
sshPort="22"
# run master machine
# Note: list of hosts hostname for deploying master
masters="master.eights.com"
# run worker machine
# note: need to write the worker group name of each worker, the default value is "default"
workers="master.eights.com:default"
# run alert machine
# note: list of machine hostnames for deploying alert server
alertServer="master.eights.com"
# run api machine
# note: list of machine hostnames for deploying api server
apiServers="master.eights.com"
# whether to start monitoring self-starting scripts
monitorServerState="false"添加Hadoop集群配置文件
如果集群未启用HA,直接在install_config.conf文件中进行编写
如果集群启用了HA,请将hadoop的hdfs-site.xml和core-site.xml拷贝到/conf目录下
修改JVM参数
两个文件
/bin/dolphinscheduler-daemon.sh
/scripts/dolphinscheduler-daemon.sh
export DOLPHINSCHEDULER_OPTS="-server -Xmx16g -Xms1g -Xss512k
-XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled
-XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods
-XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70"一键部署&进程检查&单服务启停
一键部署
sh install.sh
进程检查
su dscheduler;
jps;
服务启停
# 一键停止
sh ./bin/stop-all.sh
# 一键开启
sh ./bin/start-all.sh
# 启停master
sh ./bin/dolphinscheduler-daemon.sh start master-server
sh ./bin/dolphinscheduler-daemon.sh stop master-server
# 启停worker
sh ./bin/dolphinscheduler-daemon.sh start worker-server
sh ./bin/dolphinscheduler-daemon.sh stop worker-server
# 启停api-server
sh ./bin/dolphinscheduler-daemon.sh start api-server
sh ./bin/dolphinscheduler-daemon.sh stop api-server
# 启停logger
sh ./bin/dolphinscheduler-daemon.sh start logger-server
sh ./bin/dolphinscheduler-daemon.sh stop logger-server
# 启停alert
sh ./bin/dolphinscheduler-daemon.sh start alert-server
sh ./bin/dolphinscheduler-daemon.sh stop alert-server前端访问
1.3.0中的前端不需使用nginx
直接使用[api-server]:12345/dolphinscheduler进行访问
访问成功 - 账号admin,密码dolphinscheduler123

4
新增组件功能测试
shell使用资源文件
在资源中心中创建一个文件夹-文件夹测试,然后创建一个资源文件-这是一个文件测试.sh

文件内容,打印简单的字符串

新建shell任务,按照老版本的方式引用资源文件

运行任务,出现找不到文件的异常

找到worker机器,查看生成的执行文件,发现创建资源文件的时候,新建了资源的上级目录文件夹

修改shell中引用资源文件的方式,加上上级资源目录

重新运行任务,成功

总结:ds-1.3.0引入了资源目录,在任务节点应用的时候,需要加上对应资源的目录层级!!!
条件分支任务
创建一个条件分支任务,每个shell都是简单打印1,2,3
根据shell-1的执行情况,决定执行shell-2还是shell-3
条件节点的配置如下,这里特别注意,条件节点中的自定义参数,自定义的是前置任务的状态判断!!!这个自定义参数必须要选的,不然条件分支会一直处于成功状态。

shell-1执行成功测试

执行结果,1节点执行成功,然后执行2节点,3节点未执行
shell-1执行失败测试

执行结果,1节点执行失败,执行3节点,2节点未执行
总结:条件节点!这个真的可以。
Sqoop
目前的Sqoop任务基本满足需求,单表导入|查询接入|Hive导出这里就不进行测试了
下面是槽点(手动狗头
 )
)
接入和导出不支持-D类型的Hadoop自定义参数,如设置MR任务的名称,MR的内存和数量等自定义参数
导入大表的时候有可能OOM,目前不支持设置Map和Reduce的内存
不支持split-by字段。在-m大于1的条件下,如果关系库表的主键不是自增的,Sqoop有可能会造成导入Hadoop的数据重复,一般的解决方案是指定一个split-by字段。因此,split-by需要支持。
不可自定义参数,比如导入mysql,某些表可以加上--direct加快导入速度
解决方案
任务名称是通用的,需要在Sqoop页面上补充作为必选项
增加两个自定义参数框,用于用户编写所需的自定义参数
MR任务级别的参数,如设置MR的内存,Mapper数量和Reducer数量等
Sqoop任务级别的参数,类似--direct和--fetch-size这些在特定场景下使用的参数
类似DataX节点,直接增加一个自定义配置
5
新功能-点点点
工作流复制

DAG格式化
美化前

美化后

6
总结
DS-1.3.0架构大的变动就是任务队列的变化,在之前的版本中任务队列是存到zk上的,worker去抢锁,然后消费对应znode中累积的任务数据,而1.3.0引入了netty框架进行master-worker之间的任务数据传输。减少了分布式锁的竞争,降低任务触发延迟
引入了数据同步节点,DataX和Sqoop,虽然封装的程度还不算很完善,但是能用。当然,为了好用需要更多的社区用户提交issue,提pr!!!
条件分支节点真的可以,不过建议大家多尝试一下条件节点的逻辑组合,有点绕,需要多尝试!!!
资源目录终于是有了,但是还有进步的空间。点击按钮创建目录,还是没有右键来得自然