Sentinel规则之流量控制规则
Sentinel规则之流量控制规则
☞ 博客导航,带你有序的阅读和学习!
文章目录
- Sentinel规则之流量控制规则
- ☞ [博客导航](https://blog.csdn.net/ooyhao/article/details/101559083),`带你有序的阅读和学习!`
- 概述
- 继承结构
- 基本代码
- 基于QPS流量控制
- 流量控制
- 代码测试
- 基于并发线程数控制
- 基于调用关系的流量控制
- 根据调用方限流
- 根据调用链路限流
- 具有关系的资源流量控制:关联流量控制
- 自定义Origin
概述
流量控制(flow control), 其原理是监控应用的QPS或并发线程数等指标,当达到指定的阈值时对流量进行控制,以避免被瞬时的流量高峰冲垮,从而保障应用的高可用性。
文档:https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
继承结构
同一资源可以创建多条限流规则。我们先看一下继承结构:

下面是Rule接口代码:
public interface Rule {
boolean passCheck(Context context, DefaultNode node, int count, Object... args);
}
AbstractRule:
public abstract class AbstractRule implements Rule {
/**
* 资源名,资源名是限流规则的作用对象。
*/
private String resource;
/**
* 流控针对的调用来源,default代表不区分调用来源
*/
private String limitApp;
}
FlowRule:
public class FlowRule extends AbstractRule {
/**
* 限流阈值类型 0:线程数 1:QPS queries per second
*/
private int grade = RuleConstant.FLOW_GRADE_QPS;
/**
* 数量。限流阈值
*/
private double count;
/**
* 流控模式
* public static final int STRATEGY_DIRECT = 0; //direct 直接模式
* public static final int STRATEGY_RELATE = 1; //relate 关联
* public static final int STRATEGY_CHAIN = 2; //chain 链路
*/
private int strategy = RuleConstant.STRATEGY_DIRECT;
/**
* Reference resource in flow control with relevant resource or context.
*/
private String refResource;
/**
* Rate limiter control behavior.
* 流控控制效果(直接拒绝,Warm up,匀速排队)
* 0. default(reject directly), 1. warm up, 2. rate limiter, 3. warm up + rate limiter
*/
private int controlBehavior = RuleConstant.CONTROL_BEHAVIOR_DEFAULT;
private int warmUpPeriodSec = 10;
/**
* Max queueing time in rate limiter behavior.
*/
private int maxQueueingTimeMs = 500;
private boolean clusterMode;
/**
* 集群模式
*/
private ClusterFlowConfig clusterConfig;
/**
* The traffic shaping (throttling) controller.
*/
private TrafficShapingController controller;
@Override
public boolean passCheck(Context context, DefaultNode node, int acquireCount, Object... args) {
return true;
}
}
单条限流规则主要由以下几个因素组成,我们可以组合这些元素实现不同的限流效果:
resource: 资源名,即限流规则的作用对象count: 限流阈值grade: 限流阈值类型(QPS或是并发线程数)limitApp: 流控针对的调用来源,若为default则不区分来源strategy: 调用关系限流策略controlBehavior:流量控制效果(直接拒绝,Warm Up,均速排队)
基本代码
// EchoController
@RestController
public class EchoController {
@Autowired
private EchoService echoService;
@GetMapping("/echo/{str}")
public String echo(@PathVariable String str, HttpServletRequest request){
return echoService.echo(str);
}
}
// EchoService
public interface EchoService {
String echo(String str);
}
// EchoServiceImpl
@Service
public class EchoServiceImpl implements EchoService {
@Override
@SentinelResource(value = "echo",blockHandler = "handleBlockException")
public String echo(String str) {
return "echo str:"+str;
}
public String handleBlockException(String str, BlockException ex){
return "str:"+str+" | e:"+ex;
}
}
基于QPS流量控制
当QPS超过某个阈值的时候,则采用措施进行流量控制(基于并发线程数的没有这个控制)。流量控制的手段包括以下几种:直接拒绝,Warm Up,均速排队。对应FlowRule 中的controlBeHavior字段。
https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6#22-qps%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
流量控制
-
直接拒绝:(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式是默认的流量控制方式,当QPS超过任何规则的阈值后,新的请求就会立即拒绝,拒绝方式为抛出
FlowException. 这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。 -
Warm Up:(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处理低水平的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值的上限,给系统一个预热的时间,避免冷系统被压垮。
通常冷启动的过程系统允许通过的 QPS 曲线如下图所示:
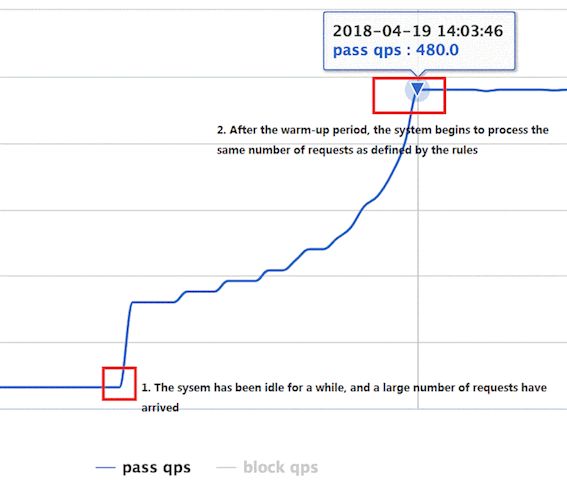
-
均速排队:(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式后严格控制请求通过的时间间隔,也即是让请求以均匀的速度通过,对应的是漏桶算法。
该方式的作用如下图所示:
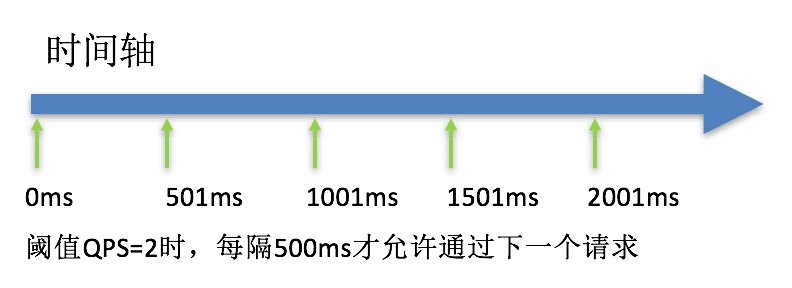
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
代码测试
初始化规则:
/*初始化规则*/
public static void initRule(){
List<FlowRule> rules = new ArrayList<>();
//定义规则
FlowRule rule = new FlowRule();
//定义资源
rule.setResource("echo");
//定义模式
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
//定义阈值
rule.setCount(2);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
public static void testFlowRule(){
initRule();
Entry entry = null;
for (int i = 0; i < 10; i++) {
try {
entry = SphU.entry("echo");
System.out.println("访问成功");
} catch (BlockException e) {
System.out.println("当前访问人数过多,请刷新后重新!");
}finally {
if (entry != null){
entry.exit();
}
}
}
}
// ============== 执行结果 =================
/**
访问成功
访问成功
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
当前访问人数过多,请刷新后重试!
*/
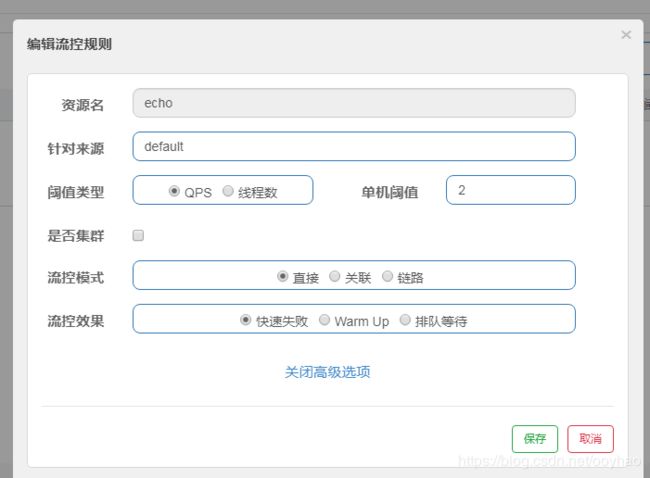
通过上面的代码可以测试出:当我们使用QPS为阈值类型时,并设置阈值为2,定义资源,其他默认,则表示一秒内,只需要通过两次请求,其他的均失败。
initRule()方法相当于在页面这样设置:
基于并发线程数控制
代码测试:
public static void initFlowRuleForThreadNum() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
//定义以线程数控制
rule.setGrade(RuleConstant.FLOW_GRADE_THREAD);
//定义资源名
rule.setResource("echo");
//定义并发线程数阈值
rule.setCount(2);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
public static void testFlowRuleForThreadNum() {
initFlowRuleForThreadNum();
for (int i = 0; i < 5; i++) {
new Thread() {
@Override
public void run() {
for (int j = 0; j < 5; j++) {
Entry entry = null;
try {
entry = SphU.entry("echo");
System.out.println("操作成功!");
} catch (BlockException ex) {
System.out.println("当前访问人数过多,请刷新后重试!");
} finally {
if (entry != null) {
entry.exit();
}
}
}
}
}.start();
}
}
// ========================测试结果==================
/**操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
操作成功!
当前访问人数过多,请刷新后重试!
操作成功!*/
上面的初始化规则,相当于:

基于调用关系的流量控制
https://github.com/alibaba/Sentinel/wiki/%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6#%E5%9F%BA%E4%BA%8E%E8%B0%83%E7%94%A8%E5%85%B3%E7%B3%BB%E7%9A%84%E6%B5%81%E9%87%8F%E6%8E%A7%E5%88%B6
根据调用方限流
ContextUtil.enter(resourceName, origin) 方法中的origin 参数标明了调用身份。这些信息会在ClusterBuilderSlot 中统计。
流量规则中的limitApp 字段用于根据调用来源进行流量控制。该字段的值有以下三种选择,分别对应不同的场景:
default:表示不区分调用者,来自任何调用者的请求都将进行限流统计。如果这个资源名的调用总和超过了这条规则定义的阈值,则出发限流。{some_origin_name}: 表示针对特定的调用者,只有来自这个调用者的请求才会进行流量控制。例如NodeA配置了一条针对调用者caller1的规则,那么当且仅当来自caller1对NodeA的请求才会触发流量控制。other:表示针对除{some_origin_name}以外的其余调用方的流量进行流量控制。例如:资源NodeA配置了一条针对调用者caller1的限流规则,同时又配置了一条调用者为other的规则,那么任意来自非caller1对NodeA的调用,都不能超过other这条规则定义的阈值。
同一资源名可以配置多条规则,规则生效的顺序为:{some_origin_name} > other > default.
代码测试:
/*定义根据调用者的流控规则*/
public static void initFlowRuleForCaller(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
//定义资源名
rule.setResource("echo");
//定义阈值类型
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
//定义阈值
rule.setCount(2);
//定义限制调用者
rule.setLimitApp("caller");
rules.add(rule);
FlowRule rule1 = new FlowRule();
rule1.setResource("echo");
rule1.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule1.setLimitApp("other");
rule1.setCount(3);
rules.add(rule1);
FlowRuleManager.loadRules(rules);
}
public static void testFlowRuleForCaller(){
initFlowRuleForCaller();
for (int i = 0; i < 5; i++) {
ContextUtil.enter("c1","caller");
Entry entry = null;
try {
entry = SphU.entry("echo");
System.out.println("访问成功");
} catch (BlockException e) {
System.out.println("网络异常,请刷新!");
}finally {
if (entry != null){
entry.exit();
}
}
}
}
// =========测试结果:=========
/*
访问成功
访问成功
网络异常,请刷新!
网络异常,请刷新!
网络异常,请刷新!*/
// ===========将caller换成caller1测试,结果如下============
/*
访问成功
访问成功
访问成功
网络异常,请刷新!
网络异常,请刷新!*/
控制页面流控规则列表:

前面都是自己手动使用ContextUtil自己去埋点定义,那么在web场景下如何识别origin呢?
这一部分放到最后,:如何自定义origin ?
根据调用链路限流
NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树。这棵树的根节点是一个名字为 machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点。
一棵典型的调用树如下图所示:
machine-root
/ \
/ \
Entrance1 Entrance2
/ \
/ \
DefaultNode(nodeA) DefaultNode(nodeA)
上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流。比如我们可以设置 FlowRule.strategy 为 RuleConstant.CHAIN,同时设置 FlowRule.ref_identity 为 Entrance1 来表示只有从入口 Entrance1 的调用才会记录到 NodeA 的限流统计当中,而不关心经 Entrance2 到来的调用。
调用链的入口(上下文)是通过 API 方法 ContextUtil.enter(contextName) 定义的,其中 contextName 即对应调用链路入口名称。
代码测试:
- 规则定义
public static void initFlowRuleForLink(){
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
//定义流控模式
rule.setStrategy(RuleConstant.STRATEGY_CHAIN);
//定义资源名
rule.setResource("echo");
//定义入口资源
rule.setRefResource("Entrance1");
//定义阈值类型
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
//定义阈值
rule.setCount(2);
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
- 页面显示
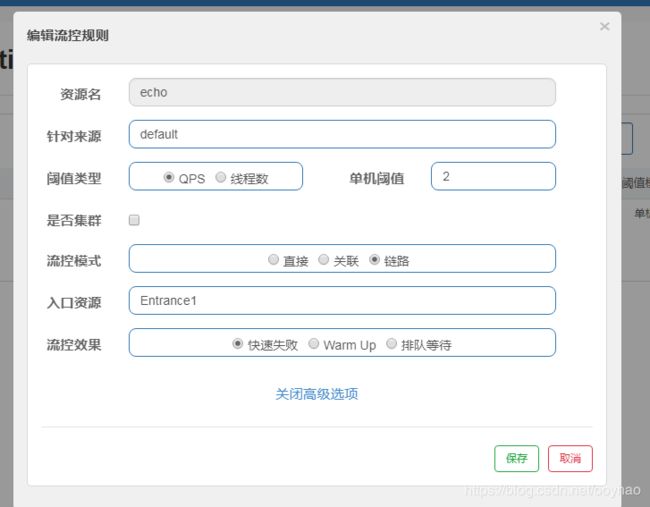
- 测试
public static void testFlowRuleForLink(){
initFlowRuleForLink();
for (int i = 0; i < 5; i++) {
ContextUtil.enter("Entrance1");
Entry entry = null;
try {
entry = SphU.entry("echo");
System.out.println("访问成功");
} catch (BlockException e) {
System.out.println("网络异常,请刷新!");
}finally {
if (entry != null){
entry.exit();
}
}
}
}
//========测试结果======
/*访问成功
访问成功
网络异常,请刷新!
网络异常,请刷新!
网络异常,请刷新!*/
//========ContextUtil.enter("Entrance1");修改为ContextUtil.enter("Entrance2");====
/*
访问成功
访问成功
访问成功
访问成功
访问成功
*/
根据测试结果可以看出,这里只对入口为Entrance1 进行流量控制,对Entrance2 不进行流量控制。
具有关系的资源流量控制:关联流量控制
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,read_db 和 write_db 这两个资源分别代表数据库读写,我们可以给 read_db 设置限流规则来达到写优先的目的:设置 FlowRule.strategy 为 RuleConstant.RELATE 同时设置 FlowRule.ref_identity 为 write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
自定义Origin
alibaba的github FAQ中有提到:
https://github.com/alibaba/Sentinel/wiki/FAQ#q-%E6%80%8E%E4%B9%88%E9%92%88%E5%AF%B9%E7%89%B9%E5%AE%9A%E8%B0%83%E7%94%A8%E7%AB%AF%E9%99%90%E6%B5%81%E6%AF%94%E5%A6%82%E6%88%91%E6%83%B3%E9%92%88%E5%AF%B9%E6%9F%90%E4%B8%AA-ip-%E6%88%96%E8%80%85%E6%9D%A5%E6%BA%90%E5%BA%94%E7%94%A8%E8%BF%9B%E8%A1%8C%E9%99%90%E6%B5%81%E8%A7%84%E5%88%99%E9%87%8C%E9%9D%A2-limitapp%E6%B5%81%E6%8E%A7%E5%BA%94%E7%94%A8%E7%9A%84%E4%BD%9C%E7%94%A8
在web情况下,会有一个名为CommonFilter 的Filter对请求进行过滤:我们来看一下源码:
public class CommonFilter implements Filter {
private final static String HTTP_METHOD_SPECIFY = "HTTP_METHOD_SPECIFY";
private final static String COLON = ":";
private boolean httpMethodSpecify = false;
@Override
public void init(FilterConfig filterConfig) {
httpMethodSpecify = Boolean.parseBoolean(filterConfig.getInitParameter(HTTP_METHOD_SPECIFY));
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
HttpServletRequest sRequest = (HttpServletRequest)request;
Entry urlEntry = null;
try {
String target = FilterUtil.filterTarget(sRequest);
UrlCleaner urlCleaner = WebCallbackManager.getUrlCleaner();
if (urlCleaner != null) {
target = urlCleaner.clean(target);
}
if (!StringUtil.isEmpty(target)) {
//******* 主要看这个方法,这是用来转化origin的。
String origin = parseOrigin(sRequest);
ContextUtil.enter(WebServletConfig.WEB_SERVLET_CONTEXT_NAME, origin);
if (httpMethodSpecify) {
String pathWithHttpMethod = sRequest.getMethod().toUpperCase() + COLON + target;
urlEntry = SphU.entry(pathWithHttpMethod, ResourceTypeConstants.COMMON_WEB,
EntryType.IN);
} else {
urlEntry = SphU.entry(target, ResourceTypeConstants.COMMON_WEB, EntryType.IN);
}
}
chain.doFilter(request, response);
} catch (BlockException e) {
HttpServletResponse sResponse = (HttpServletResponse)response;
WebCallbackManager.getUrlBlockHandler().blocked(sRequest, sResponse, e);
} catch (IOException | ServletException | RuntimeException e2) {
Tracer.traceEntry(e2, urlEntry);
throw e2;
} finally {
if (urlEntry != null) {
urlEntry.exit();
}
ContextUtil.exit();
}
}
private String parseOrigin(HttpServletRequest request) {
RequestOriginParser originParser = WebCallbackManager.getRequestOriginParser();
String origin = EMPTY_ORIGIN;
if (originParser != null) {
origin = originParser.parseOrigin(request);
if (StringUtil.isEmpty(origin)) {
return EMPTY_ORIGIN;
}
}
return origin;
}
@Override
public void destroy() {}
private static final String EMPTY_ORIGIN = "";
}
parseOrigin方法:
private String parseOrigin(HttpServletRequest request) {
//这个方法需要从WebCallbackManager中拿出一个RequestOriginParser.
RequestOriginParser originParser = WebCallbackManager.getRequestOriginParser();
String origin = EMPTY_ORIGIN;
if (originParser != null) {
origin = originParser.parseOrigin(request);
if (StringUtil.isEmpty(origin)) {
return EMPTY_ORIGIN;
}
}
return origin;
}
RequestOriginParser接口:
public interface RequestOriginParser {
String parseOrigin(HttpServletRequest request);
}
在项目中这个接口是没有实现的,所以正常情况下origin = "". 我们需要自己实现,并将其加入到spring容器中即可。
/**
* @author hao.ouYang
* @create 2019-10-22 18:25
*/
@Component
public class IOriginParser implements RequestOriginParser {
@Override
public String parseOrigin(HttpServletRequest request) {
String id = request.getParameter("id");
System.out.println(id);
return id;
}
}