Yarn 历史任务日志解释和配置
转载来自:https://www.jianshu.com/p/83fcf7478dd7
前言
Yarn中的id种类繁多,比较乱,下面整理下yarn中常出现的几种id,分别介绍一下。
1)jobId
描述:出自MapReduce,对作业的唯一标识。
格式:job_${clusterStartTime}_${jobid}
例子:job_1498552288473_2742
2)applicationId
描述:在yarn中对作业的唯一标识。
格式:application_${clusterStartTime}_${applicationId}
例子:application_1498552288473_2742
3)taskId
描述:作业中的任务的唯一标识
格式:task_${clusterStartTime}_${applicationId}_[m|r]_${taskId}
例子:task_1498552288473_2742_m_000000、task_1498552288473_2742_r_000000
4)attempId
描述:任务尝试执行的一次id
格式:attempt_${clusterStartTime}_${applicationId}_[m|r]_${taskId}_${attempId}
例子:attempt_1498552288473_2742_m_000000_0
5)appAttempId
描述:ApplicationMaster的尝试执行的一次id。
格式:appattempt_${clusterStartTime}_${applicationId}_${appAttempId}
例子:appattempt_1498552288473_2742_000001
6)containerId:
描述:container的id
格式:container_e*epoch*_${clusterStartTime}_${applicationId}_${appAttempId}_${containerId}
例子:container_e20_1498552288473_2742_01_000032、container_1498552288473_2742_01_000032
一、yarn中的几种日志
- 服务类日志
诸如ResourceManage、NodeManager等系统自带的服务输出来的日志默认是存放在${HADOOP_HOME}/logs目录下,此参数可以通过参数YARN_LOG_DIR(yarn-env.sh配置文件,当前配置为:/data1/hadoop/logs/$USER)指定。比如resourcemanager的输出日志为yarn-${USER}-resourcemanager-${hostname}.log,其中${USER}s是指启动resourcemanager进程的用户,${hostname}是resourcemanager进程所在机器的hostname,nodemanager的输出日志格式为:yarn-${USER}-nodemanager-${hostname}.log,这类日志可以查看当前resourcemanager和nodemanager两个服务的运行情况。日志路径: /data1/hadoop/logs/yarn - 任务日志
1)作业的统计日志:(路径为hdfs路径)
历史作业的记录里面包含了一个作业用了多少个Map、用了多少个Reduce、作业提交时间、作业启动时间、作业完成时间等信息;这些信息对分析作业是很有帮助的,我们可以通过这些历史作业记录得到每天有多少个作业运行成功、有多少个作业运行失败、每个队列作业运行了多少个作业等很有用的信息。这部分日志会用于JobHistoryServer。
相关参数:
key : apreduce.jobhistory.done-dir
value : /var/hadoop/mapred/mr-history/done
该参数默认值为:${yarn.app.mapreduce.am.staging-dir}/history/done
key : mapreduce.jobhistory.intermediate-done-dir
value :/var/hadoop/mapred/mr-history/tmp
该参数默认值为:${yarn.app.mapreduce.am.staging-dir}/history/done_intermediate
yarn.app.mapreduce.am.staging-dir:

2)作业的运行日志:(路径为本地路径)
Container日志包含ApplicationMaster日志和普通Task日志等信息,主要包含container的启动脚本,还有container的运行日志。默认情况下,这些日志信息是存放在${HADOOP_HOME}/logs/userlogs目录下,我们可以通过下面的配置进行修改。
相关参数:
key : yarn.nodemanager.log-dirs
value : /data1/hadoop/yarn/log,/data14/hadoop/yarn/log,/data12/hadoop/yarn/log,/data7/hadoop/yarn/log,/data8/hadoop/yarn/log,/data6/hadoop/yarn/log,/data13/hadoop/yarn/log,/data4/h
adoop/yarn/log,/data9/hadoop/yarn/log,/data11/hadoop/yarn/log,/data5/hadoop/yarn/log,/data2/hadoop/yarn/log,/data15/hadoop/yarn/log,/data3/hadoop/yarn/log,/data10/hadoop/yarn/log,/data1
6/hadoop/yarn/log
二、日志的聚合
从上面作业的运行日志中可以发现,container的日志在一台机器的16块盘上都会存在日志,而且并不知道container的日志会在哪个盘上,默认情况下,每块盘上都会创建相同的applicationid,而且applicationid中都会创建相同的containerid,但是并不是每个container中都会存在日志,这块由container自己的机制选择往哪个container目录中写入日志,其他的container目录则为空。这在一定程度上导致了想查看任务的运行日志比较困难。
日志的聚合功能可以解决这个问题。
开启此项功能:
key : yarn.log-aggregation-enable
value : true
此项功能会把各nodemanager上的application的所有盘上的container上传到hdfs
相关参数:
key : yarn.nodemanager.remote-app-log-dir
value : /var/hadoop/yarn
key : yarn.nodemanager.remote-app-log-dir-suffix
value: logs
hdfs上路径:
/var/hadoop/yarn/${user}/logs
查看日志的方式
1)通过web页面
2)命令行 yarn logs -applicationId ${applicationId}
三、日志聚合的机制
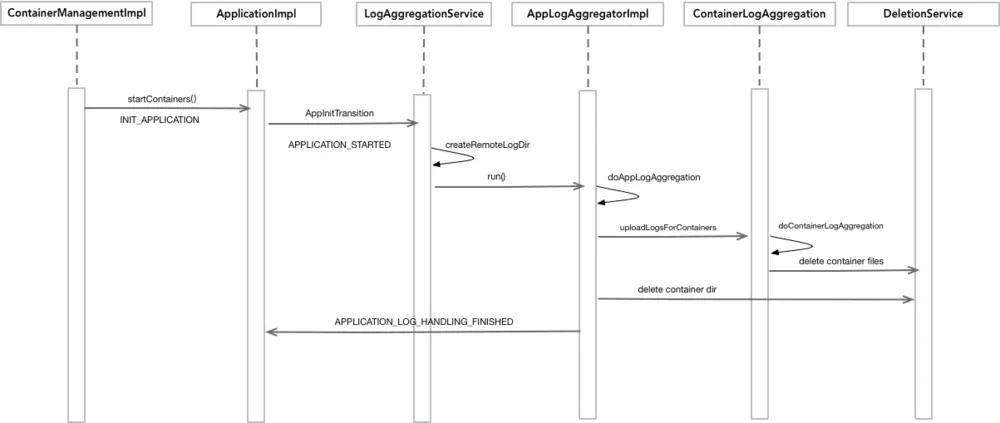
image.png
四、日志清理
相关参数:
key : mapreduce.jobhistory.max-age-ms
value : 2592000000 (30天)
descrption:负责清理hdfs路径下日志 /var/hadoop/mapred/mr-history/done
key : yarn.log-aggregation.retain-seconds
value : 2592000 (30天)
description:负责清理hdfs路径下日志 /var/hadoop/yarn/${user}/logs
服务器上的本地日志在任务执行完进行日志聚合之后会自动进行删除,不过老数据目前还没有清理。
五、日志相关参数
1) yarn.log-aggregation-enable
是否开启日志聚合功能
2) yarn.log-aggregation.retain-seconds
hdfs上的日志保留多久。当前配置路径为:/var/hadoop/yarn/${user}/logs
3) yarn.log-aggregation.retain-check-interval-seconds
多长时间检查一次日志,并将满足条件的删除,如果是0或者负数,则为上一个值的1/10,已经配置为:1296000(15天)
4) yarn.nodemanager.remote-app-log-dir
前缀目录:/var/hadoop/yarn
5) yarn.nodemanager.remote-app-log-dir-suffix
后缀目录:logs
6) yarn.nodemanager.log-aggregation.roll-monitoring-interval-seconds
每隔一段时间进行日志的聚合,当前配置为:3600。如果配置为-1,则会等待任务执行完还会聚合
六、其他
关于清理日志的方法
1.NonAggregatingLogHandler