DataX安装部署-Reader插件二次开发
DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX详细介绍
请参考:DataX-Introduction
DataX是什么可参考:https://blog.csdn.net/burpee/article/details/53734393
DataX安装部署及小试
1.下载压缩包:
下载页面地址:https://github.com/alibaba/DataX 在页面中【Quick Start】--->【Download DataX下载地址】进行下载。下载后的包名:datax.tar.gz。解压后{datax}目录下有{bin conf job lib log log_perf plugin script tmp}几个目录。
2.安装
将下载后的压缩包直接解压后可用,前提是对应的java及python环境满足要求。
System Requirements:
- Linux
- JDK(1.6以上,推荐1.6)
- Python(推荐Python2.6.X)一定要为python2,因为后面执行datax.py的时候,里面的python的print会执行不了,导致运行不成功,会提示你print语法要加括号,python2中加不加都行 python3中必须要加,否则报语法错,因为执行过程通过python脚本执行,所以python3环境报错无法运行。
- Apache Maven 3.x (Compile DataX)
3.测试
配置测试样例:下面我们配置一组 从TXT文本到另一个TXT文本。
第一步、创建作业的配置文件(json格式)
在bin目录执行 python datax.py -r {your_reader} -w {your_writer}
{your_reader} 为datax\plugin\reader 目录下的插件名字,到包名就可以,{your_writer}相同;
如图:txtfilereaderTest是我二次开发之后的包,在datax\plugin\reader目录下;
执行python datax.py -r txtfilereaderTest -w txtFileWriter;会生成下面红框json模板,只需要将其复制出来,在datax\job\目录下新建一个newJob.josn 然后内容使用该模板。
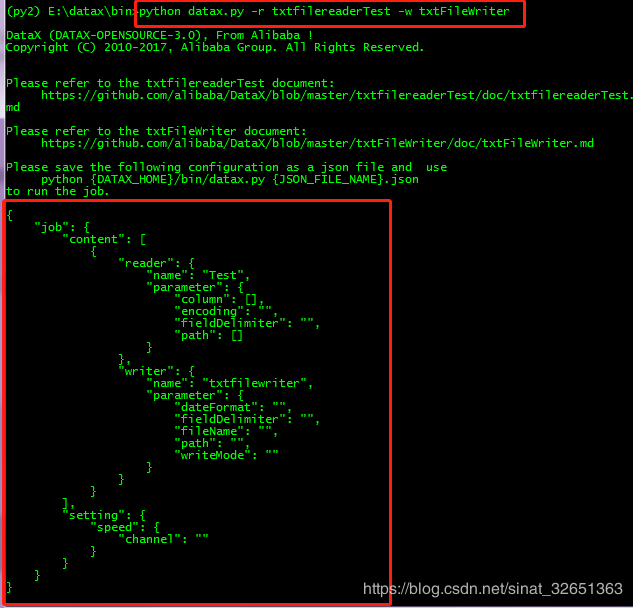
自己配置的模板如下:
- {
- "job": {
- "content": [
- {
- "reader": {
- "name": "Test",
- "parameter": {
- "column": [
- {
- "index": 0,
- "type": "string"
- },
- {
- "index": 1,
- "type": "string"
- }
- ],
- "encoding": "utf-8",
- "fieldDelimiter": ",",
- "skipHeader": "True",
- "path": ["E:/python_project/BigData-Base/etl/test/ADDRESS02.txt"]
- }
- },
- "writer": {
- "name": "txtfilewriter",
- "parameter": {
- "dateFormat": "yyyy-MM-dd",
- "fieldDelimiter": ",",
- "fileName": "ADDRESS.txt",
- "path": "E:/datax/job/",
- "writeMode": "append"
- }
- }
- }
- ],
- "setting": {
- "speed": {
- "channel": "1"
- }
- }
- }
- }
模板具体内容怎么配置可参考:https://github.com/alibaba/DataX ,官方每个包内都有个doc文件夹,里面专门有配置参数说明,按照说明配置即可。
启动:python datax.py {your_file} 如果是Windows则要写绝对路径。
python datax.py E:\datax\job\txtjsonTest.json
windows下乱码修复:
我把这个工具迁移到一台windows主机上使用时候看到控制台友好的中文提示居然都变成了乱码了(话说有中文提示也是我选择他很重要的理由啊)。还好官方也给出了解决方案:
打开CMD.exe命令行窗口
通过 chcp命令改变代码页,UTF-8的代码页为65001
chcp 65001
执行该操作后,代码页就被变成UTF-8了。但是,在窗口中仍旧不能正确显示UTF-8字符。
修改窗口属性,改变字体,在命令行标题栏上点击右键,选择"属性"->"字体",将字体修改为True Type字体"Lucida Console",然后点击确定将属性应用到当前窗口。
运行:
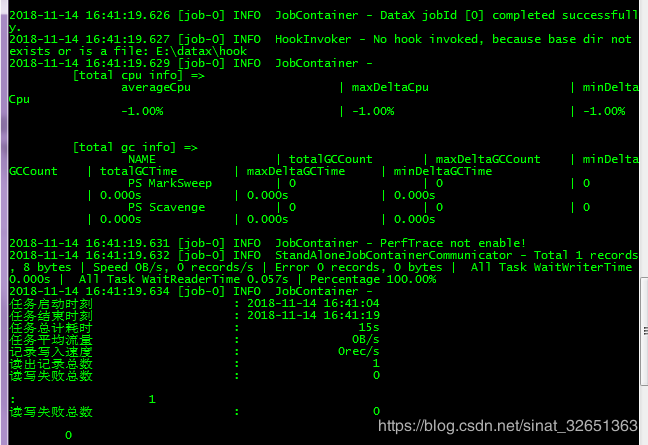
DataX目前支持读写数据格式:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | √ | 读 、写 | |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Hive | √ | √ | 读 、写 | |
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 |
也可以参考其他博客,测试例子基本相同,实际使用根据自己需求调整配置文件即可,目前DataX已经迭代到了3.0版本,开源部分目前是单机版本,不过阿里内部已经可以集群运行了,3.0中也有所体现,未来说不定集群版本也会开源呢。
列举一下官方文档:
github:https://github.com/alibaba/DataX
下载:https://github.com/alibaba/DataX/blob/master/userGuid.md
DataX数据源参考指南:https://github.com/alibaba/DataX/wiki/DataX-all-data-channels
DataX插件开发宝典:https://github.com/alibaba/DataX/blob/master/dataxPluginDev.md
DataX插件二次开发
如果官方提供的插件没有自己需要用的怎么办,就需要自己开发需要的插件了,可参考官方DataX插件开发宝典。
我做了一个Reader插件,读取TXT文档的时候清除单引号的ETLdemo。
1. 创建一个maven工程。
模板:只需要改artifactId,name其他内容不变。
pom.xml内容,红色标记为自己文件
4.0.0 com.alibaba.datax datax-all 0.0.1-SNAPSHOT Test Test txtFilereaderTest,并可以根据用户配置的类型进行类型转换,建议开发、测试环境使用。 jar com.alibaba.datax datax-common ${datax-project-version} slf4j-log4j12 org.slf4j com.alibaba.datax plugin-unstructured-storage-util ${datax-project-version} org.slf4j slf4j-api ch.qos.logback logback-classic com.google.guava guava 16.0.1 maven-compiler-plugin 1.6 1.6 ${project-sourceEncoding} maven-assembly-plugin src/main/assembly/package.xml datax dwzip package single
2. 创建如下文件树
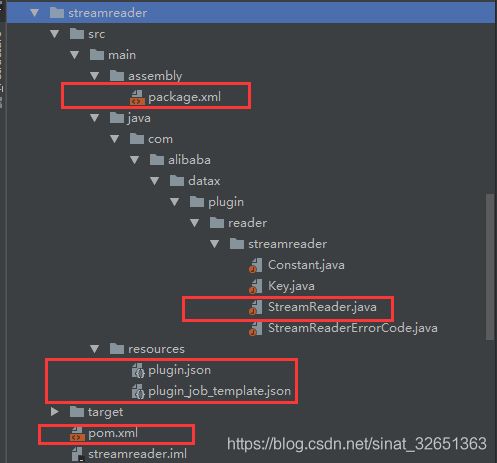
package.xml 文件为最后打包文件
它会读取模板配置:plugin.json;plugin_job_template.json
需要自行修改的已标红,其他目录级别不可变。
dir false src/main/resources plugin.json plugin_job_template.json plugin/reader/txtFilereaderTest target/ txtFilereaderTest-0.0.1-SNAPSHOT.jar plugin/reader/txtFilereaderTest false plugin/reader/txtFilereaderTest/libs runtime
plugin.json文件:
class:你自己的class文件目录,我的是reader插件,所以在reader目录下的txtFilereaderTest包里的Test类。
{ "name": "Test", "class": "com.alibaba.datax.plugin.reader.txtFilereaderTest.Test", "description": "useScene: test. mechanism: use datax framework to transport data from txt file. warn: The more you know about the data, the less problems you encounter.", "developer": "alibaba" }
plugin_job_template.json文件:
该文件用于开始生成模板的文件,reader插件与writer插件各有不同,可参考官方不同包下的doc文件夹里的说明。
{ "name": "Test", "parameter": { "path": [], "encoding": "", "column": [], "fieldDelimiter": "" } }
剩下的如何编写逻辑就要自己实现了,可以先参考官方说明:DataX插件开发宝典
我这里简单实现一下去除文本中单引号,部分代码如下:
重写startRead方法,并且在文件输入流中对读入的文本进行字符串替换处理,将“ ‘北京‘ ”,处理为:“北京”;
自己要实现的所有逻辑都在此编写。
@Override public void startRead(RecordSender recordSender) { LOG.debug("start read source files..."); for (String fileName : this.sourceFiles) { LOG.info(String.format("reading file : [%s]", fileName)); InputStream inputStream; InputStream inputStreamEtl; try { inputStream = new FileInputStream(fileName); try { inputStreamEtl = string_InputStream(inputStream_String(inputStream)); com.alibaba.datax.plugin.unstructuredstorage.reader.UnstructuredStorageReaderUtil.readFromStream(inputStreamEtl, fileName, this.readerSliceConfig, recordSender, this.getTaskPluginCollector()); recordSender.flush(); } catch (Exception e) { e.printStackTrace(); } } catch (FileNotFoundException e) { // warn: sock 文件无法read,能影响所有文件的传输,需要用户自己保证 String message = String .format("找不到待读取的文件 : [%s]", fileName); LOG.error(message); throw DataXException.asDataXException( TxtFileReaderErrorCode.OPEN_FILE_ERROR, message); } } LOG.debug("end read source files..."); } } /** * inputStream to String * @param in * @return "去除字符串中引号" * @throws Exception */ public static String inputStream_String(InputStream in) throws Exception { java.io.ByteArrayOutputStream swapStream = new java.io.ByteArrayOutputStream(); int ch; while ((ch = in.read()) != -1) { swapStream.write(ch); } /** * ETL: 去除字符之间的单引号 * '北京', '大兴', * 北京, 大兴, */ return swapStream.toString().replace("'",""); } /** * String to inputStream * @param str * @return * @throws Exception */ public static ByteArrayInputStream string_InputStream(String str) throws Exception{ ByteArrayInputStream stream= new ByteArrayInputStream(str.getBytes()); return stream; }
3. 打包部署
编写好的文件按照上图文件树放置,然后添加自己插件到Git clone下的源码最外层package.xml和pom.xml 文件。
package.xml
directory:为你的插件包名,不是类名
txtFilereaderTest/target/datax/ **/*.* datax
pom.xml
同上,添加自己包名,添加至reader树内,我使用idea开发,所以maven工程可直接打包。
注意:该pom文件用maven打包会将所有插件都重新打一次包,如果只想打自己的包,将其他reader和writer包都注释掉,不然需要好久
txtFileReaderTest
4. 打包成功
应该包含以下目录及文件:
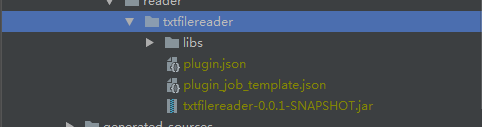
libs为所有依赖,另外两个json文件上面提过,一个加载class文件,一个生成配置;
运行:python datax.py -r txtfilereader -w txtFileWriter;