DataX 定制数据传输: 使用DataX Transformer
DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。

datax同步入口在Engine.java(读取json配置)、JobContainer.java(对任务进行预处理,初始化,分割任务,插件扫描等);datax底层是以双缓冲阻塞队列为整个数据交换的媒介,BufferedRecordExchanger.java(接受、传递数据的实体读写插件共享一个ArrayBlockingQuene),读进程负责读取并向队列中添加读到的记录,写进程负责接收数据并从队列中取出写入记录。
DataX详细介绍:https://github.com/alibaba/DataX
DataX Transformer
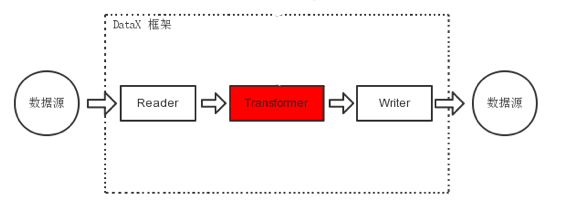
Transformer定义
在数据同步、传输过程中,存在用户对于数据传输进行特殊定制化的需求场景,包括裁剪列、转换列等工作,可以借助ETL的T过程实现(Transformer)。DataX包含了完成的E(Extract)、T(Transformer)、L(Load)支持。
运行模型
UDF手册
- dx_substr
- 参数:3个
- 第一个参数:字段编号,对应record中第几个字段。
- 第二个参数:字段值的开始位置。
- 第三个参数:目标字段长度。
- 返回: 从字符串的指定位置(包含)截取指定长度的字符串。如果开始位置非法抛出异常。如果字段为空值,直接返回(即不参与本transformer)
- 举例:
dx_substr(1,"2","5") column 1的value为“dataxTest”=>"taxTe"
dx_substr(1,"5","10") column 1的value为“dataxTest”=>"Test"
- dx_pad
- 参数:4个
- 第一个参数:字段编号,对应record中第几个字段。
- 第二个参数:“l”,“r”, 指示是在头进行pad,还是尾进行pad。
- 第三个参数:目标字段长度。
- 第四个参数:需要pad的字符。
- 返回: 如果源字符串长度小于目标字段长度,按照位置添加pad字符后返回。如果长于,直接截断(都截右边)。如果字段为空值,转换为空字符串进行pad,即最后的字符串全是需要pad的字符
- 举例:
dx_pad(1,"l","4","A"), 如果column 1 的值为 xyz=> Axyz, 值为 xyzzzzz => xyzz
dx_pad(1,"r","4","A"), 如果column 1 的值为 xyz=> xyzA, 值为 xyzzzzz => xyzz
- dx_replace
- 参数:4个
- 第一个参数:字段编号,对应record中第几个字段。
- 第二个参数:字段值的开始位置。
- 第三个参数:需要替换的字段长度。
- 第四个参数:需要替换的字符串。
- 返回: 从字符串的指定位置(包含)替换指定长度的字符串。如果开始位置非法抛出异常。如果字段为空值,直接返回(即不参与本transformer)
- 举例:
dx_replace(1,"2","4","****") column 1的value为“dataxTest”=>"da****est"
dx_replace(1,"5","10","****") column 1的value为“dataxTest”=>"data****"
- dx_filter (关联filter暂不支持,即多个字段的联合判断,函参太过复杂,用户难以使用。)
- 参数:
- 第一个参数:字段编号,对应record中第几个字段。
- 第二个参数:运算符,支持一下运算符:like, not like, >, =, <, >=, !=, <=
- 第三个参数:正则表达式(java正则表达式)、值。
- 返回:
- 如果匹配正则表达式,返回Null,表示过滤该行。不匹配表达式时,表示保留该行。(注意是该行)。对于>=<都是对字段直接compare的结果.
- like , not like是将字段转换成String,然后和目标正则表达式进行全匹配。
-
, =, <, >=, !=, <= 对于DoubleColumn比较double值,对于LongColumn和DateColumn比较long值,其他StringColumn,BooleanColumn以及ByteColumn均比较的是StringColumn值。
- 如果目标colunn为空(null),对于 = null的过滤条件,将满足条件,被过滤。!=null的过滤条件,null不满足过滤条件,不被过滤。 like,字段为null不满足条件,不被过滤,和not like,字段为null满足条件,被过滤。
- 举例:
dx_filter(1,"like","dataTest")
dx_filter(1,">=","10")
- dx_groovy
- 参数。
- 第一个参数: groovy code
- 第二个参数(列表或者为空):extraPackage
- 备注:
- dx_groovy只能调用一次。不能多次调用。
- groovy code中支持java.lang, java.util的包,可直接引用的对象有record,以及element下的各种column(BoolColumn.class,BytesColumn.class,DateColumn.class,DoubleColumn.class,LongColumn.class,StringColumn.class)。不支持其他包,如果用户有需要用到其他包,可设置extraPackage,注意extraPackage不支持第三方jar包。
- groovy code中,返回更新过的Record(比如record.setColumn(columnIndex, new StringColumn(newValue));),或者null。返回null表示过滤此行。
- 用户可以直接调用静态的Util方式(GroovyTransformerStaticUtil),目前GroovyTransformerStaticUtil的方法列表 (按需补充):
- 举例:
groovy 实现的subStr:
String code = "Column column = record.getColumn(1);\n" +
" String oriValue = column.asString();\n" +
" String newValue = oriValue.substring(0, 3);\n" +
" record.setColumn(1, new StringColumn(newValue));\n" +
" return record;";
dx_groovy(record);
groovy 实现的Replace
String code2 = "Column column = record.getColumn(1);\n" +
" String oriValue = column.asString();\n" +
" String newValue = \"****\" + oriValue.substring(3, oriValue.length());\n" +
" record.setColumn(1, new StringColumn(newValue));\n" +
" return record;";
groovy 实现的Pad
String code3 = "Column column = record.getColumn(1);\n" +
" String oriValue = column.asString();\n" +
" String padString = \"12345\";\n" +
" String finalPad = \"\";\n" +
" int NeedLength = 8 - oriValue.length();\n" +
" while (NeedLength > 0) {\n" +
"\n" +
" if (NeedLength >= padString.length()) {\n" +
" finalPad += padString;\n" +
" NeedLength -= padString.length();\n" +
" } else {\n" +
" finalPad += padString.substring(0, NeedLength);\n" +
" NeedLength = 0;\n" +
" }\n" +
" }\n" +
" String newValue= finalPad + oriValue;\n" +
" record.setColumn(1, new StringColumn(newValue));\n" +
" return record;";
Job定义
- 本例中,配置3个UDF。
{
"job": {
"setting": {
"speed": {
"channel": 1
},
"errorLimit": {
"record": 0
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [
{
"value": "DataX",
"type": "string"
},
{
"value": 19890604,
"type": "long"
},
{
"value": "1989-06-04 00:00:00",
"type": "date"
},
{
"value": true,
"type": "bool"
},
{
"value": "test",
"type": "bytes"
}
],
"sliceRecordCount": 100000
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"print": false,
"encoding": "UTF-8"
}
},
"transformer": [
{
"name": "dx_substr",
"parameter":
{
"columnIndex":5,
"paras":["1","3"]
}
},
{
"name": "dx_replace",
"parameter":
{
"columnIndex":4,
"paras":["3","4","****"]
}
},
{
"name": "dx_groovy",
"parameter":
{
"code": "//groovy code//",
"extraPackage":[
"import somePackage1;",
"import somePackage2;"
]
}
}
]
}
]
}
}
计量和脏数据
Transform过程涉及到数据的转换,可能造成数据的增加或减少,因此更加需要精确度量,包括:
- Transform的入参Record条数、字节数。
- Transform的出参Record条数、字节数。
- Transform的脏数据Record条数、字节数。
- 如果是多个Transform,某一个发生脏数据,将不会再进行后面的transform,直接统计为脏数据。
- 目前只提供了所有Transform的计量(成功,失败,过滤的count,以及transform的消耗时间)。
涉及到运行过程的计量数据展现定义如下:
Total 1000000 records, 22000000 bytes | Transform 100000 records(in), 10000 records(out) | Speed 2.10MB/s, 100000 records/s | Error 0 records, 0 bytes | Percentage 100.00%
注意,这里主要记录转换的输入输出,需要检测数据输入输出的记录数量变化。
涉及到最终作业的计量数据展现定义如下:
任务启动时刻 : 2015-03-10 17:34:21
任务结束时刻 : 2015-03-10 17:34:31
任务总计耗时 : 10s
任务平均流量 : 2.10MB/s
记录写入速度 : 100000rec/s
转换输入总数 : 1000000
转换输出总数 : 1000000
读出记录总数 : 1000000
同步失败总数 : 0
注意,这里主要记录转换的输入输出,需要检测数据输入输出的记录数量变化。
一. DataX3.0概览
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
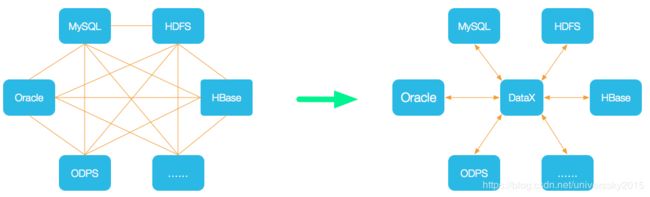
设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。
当前使用现状
DataX在阿里巴巴集团内被广泛使用,承担了所有大数据的离线同步业务,并已持续稳定运行了6年之久。目前每天完成同步8w多道作业,每日传输数据量超过300TB。
此前已经开源DataX1.0版本,此次介绍为阿里巴巴开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX。
二、DataX3.0框架设计

DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
Writer: Writer为数据写入模块,负责不断向Framework取数据,并将数据写入到目的端。
Framework:Framework用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
三. DataX3.0插件体系
经过几年积累,DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入。
DataX Framework提供了简单的接口与插件交互,提供简单的插件接入机制,只需要任意加上一种插件,就能无缝对接其他数据源。详情请看:DataX数据源指南
四、DataX3.0核心架构

DataX 3.0 开源版本支持单机多线程模式完成同步作业运行,本小节按一个DataX作业生命周期的时序图,从整体架构设计非常简要说明DataX各个模块相互关系。
核心模块介绍:
DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。
DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。
切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。
每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务