Python项目实战——纽约出租车运行情况分析建模
一、项目概述
根据出租车的运营数据,针对客户旅途时间展开分析与建模,对客流趋势及区域分布进行分析,对出租车历史数据进行分析,为客户预测预计到达时间等
过程设计:
提出问题
理解数据
数据清理
数据分析
得出结论
重要字段说明 :
编号: id
出租车类型: vendor_id
上车时间: pickup_datetime、
下车时间: dropoff_datetime、
乘客数量: passenger_count 、
上车地点 : pickup_longitude(经度)、pickup_latitude(纬度)、
下车地点: dropoff_longitude (经度)、 dropoff_latitude(纬度)、
旅途持续时间(秒): trip_duration。
首先导入需要的模块
#导入包
import os
import pandas as pd
import numpy as np
from matplotlib.pyplot import *
from matplotlib import animation
from matplotlib import cm
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from dateutil import parser
import io
import base64
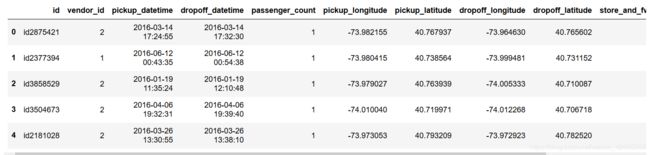
导入数据,查看前五行:
df=pd.read_csv(r'C:\Users\www12\Desktop\python\pythonDA\NewYork\train.csv')
df.head()
print(df.shape[0])
1458644
二、聚类区域划分
查看纽约市地图,划分出分析区域的经纬度,再根据数据分布情况,选择对经度[-74.03,-73.77],纬度[40.63,40.85]之间数据较为集中的区域进行分析,筛选掉区域之外的地点。
xlim=[-74.03,-73.77]
ylim=[40.63,40.85]
df=df[(df['pickup_longitude']>=xlim[0]) & (df['pickup_longitude']<=xlim[1])]
df=df[(df['dropoff_longitude']>=xlim[0]) & (df['dropoff_longitude']<=xlim[1])]
df=df[(df['pickup_latitude']>=ylim[0]) & (df['pickup_longitude']<=ylim[1])]
df=df[(df['dropoff_latitude']>=ylim[0]) & (df['dropoff_latitude']<=ylim[1])]
print(df.shape[0])
1439073
合并上下车经纬度数据,绘制出图像:
longitude=list(df['pickup_longitude'])+list(df['dropoff_longitude'])
latitude=list(df['pickup_latitude'])+list(df['dropoff_latitude'])
plt.figure(figsize=(10,10))
plt.plot(longitude,latitude,'.',alpha=0.4,markersize=0.05)
plt.show()
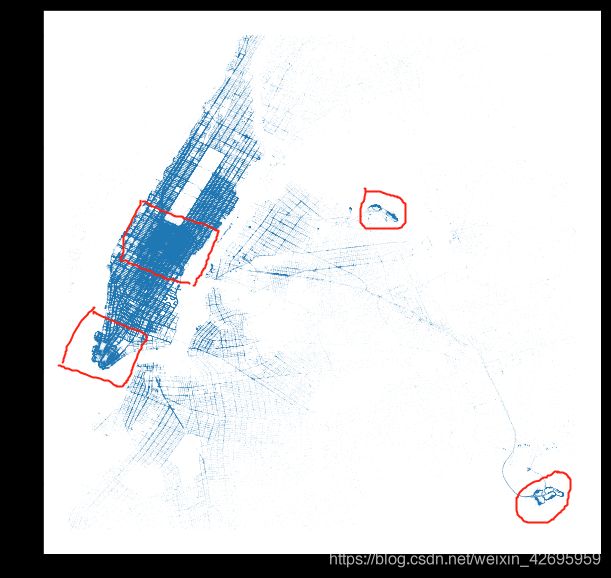
结合纽约市地图,我们可以看出客流量较为密集的几个区域,分布在曼哈顿区、港口、肯尼迪机场和拉瓜迪亚机场,我在图上标记出了这几个地方。
然后我们需要对图上客流量较为密集的几个区域进行划分,用聚类试试:
loc_df=pd.DataFrame() #提取经纬度数据
loc_df['longitude']=longitude
loc_df['latitude']=latitude
kmeans=KMeans(n_clusters=15,random_state=2,n_init=10).fit(loc_df)
loc_df['label']=kmeans.labels_
#聚类,分成15个簇,绘图,标记不同的颜色
loc_df=loc_df.sample(200000)
plt.figure(figsize=(10,10))
for label in loc_df.label.unique(): ####????###
plt.plot(loc_df.longitude[loc_df.label == label],loc_df.latitude[loc_df.label == label],'.',alpha=0.3,markersize=0.3)
plt.title('Clusters of New York')
plt.show()

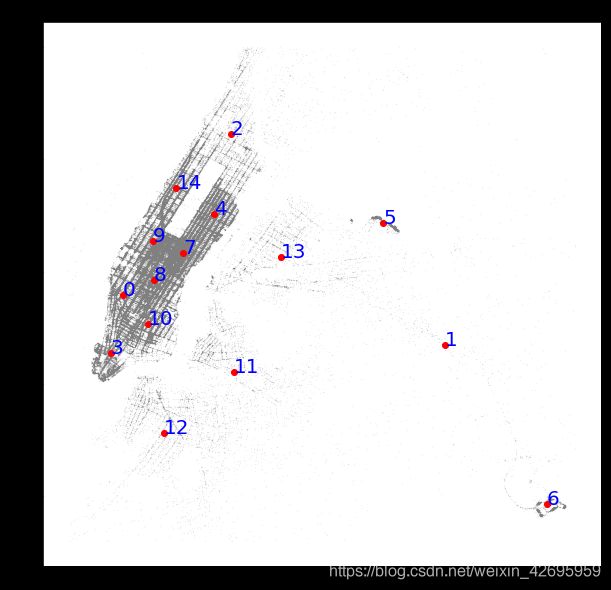
划分出了15个区域,并标记了不同的颜色,接着给每个区域作个标记
fig,ax=plt.subplots(figsize=(10,10))
for label in loc_df.label.unique(): #找到每个区域的中心点,给区域作个标记。
ax.plot(loc_df.longitude[loc_df.label == label],loc_df.latitude[loc_df.label == label],'.',alpha=0.3,markersize=0.3,color='gray')
ax.plot(kmeans.cluster_centers_[label,0],kmeans.cluster_centers_[label,1],'o', color = 'r')
ax.annotate(label, (kmeans.cluster_centers_[label,0],kmeans.cluster_centers_[label,1]), color = 'b', fontsize = 20)
ax.set_title('Cluster centers')
plt.show()
然后,我们想看一下出租车在不同的区域之间的真实运行情况,比如出发方向,哪个地方到哪个地方的客流更多一些?等,同时也应该加上时间因素,考虑到时间因素对运行的影响,比如早高峰时段,晚高峰时段的运行情况是什么样的?去机场一般是什么时间段?
三、客流趋势动态展示
对各个区域之间客流趋向进行标记
df['pickup_cluster'] = kmeans.predict(df[['pickup_longitude','pickup_latitude']]) #使用predict方法进行新数据类别的预测,将上车地点所在簇记为pickup_cluster
df['dropoff_cluster'] = kmeans.predict(df[['dropoff_longitude','dropoff_latitude']]) #将上车地点所在簇记为dropoff_cluste
df['pickup_hour']=df.pickup_datetime.apply(lambda x:parser.parse(x).hour) #模块parser从字符串中解析出时间对象,上车时间记为pickuphour
clusters=pd.DataFrame()
clusters['x']=kmeans.cluster_centers_[:,0] #取出簇中心的横坐标、纵坐标
clusters['y']=kmeans.cluster_centers_[:,1]
clusters['label'] = range(len(clusters))
loc_df = loc_df.sample(5000)
展示客流的方向与趋势,箭头的宽度与车流量成正比
fig, ax = plt.subplots(1, 1, figsize = (10,10)) #创建一个1x1的子图,大小为10*10
#画出地图
def animate(hour):
ax.clear()
ax.set_title('Relative Traffic - Hour ' + str(int(hour)) + ':00') #设置标题
plt.figure(figsize = (10,10))
for label in loc_df.label.unique():
ax.plot(loc_df.longitude[loc_df.label == label],loc_df.latitude[loc_df.label == label],'.', alpha = 1, markersize = 2, color = 'gray')
#画出每个簇中的地点的经度,纬度,小圆点,灰色
ax.plot(kmeans.cluster_centers_[label,0],kmeans.cluster_centers_[label,1],'o', color = 'r')
#画出每个簇的中心的坐标,大圆点,红色
#画客流方向 ,并以动画形式展示
for label in clusters.label: #以每个簇为起始点
for dest_label in clusters.label: #每个簇为终点
num_of_rides = len(df[(df.pickup_cluster == label) & (df.dropoff_cluster == dest_label) & (df.pickup_hour == hour)])
#num_of_rides表示客流量,等于(所有时间段的)每个簇上车点数量+每个簇下车点数量.
dist_x = clusters.x[clusters.label == label].values[0] - clusters.x[clusters.label == dest_label].values[0]
#diet_x表示每个簇到其他簇的横坐标
dist_y = clusters.y[clusters.label == label].values[0] - clusters.y[clusters.label == dest_label].values[0]
pct = np.true_divide(num_of_rides,len(df[df.pickup_hour == hour]))
arr = arrow(clusters.x[clusters.label == label].values, clusters.y[clusters.label == label].values, -dist_x, -dist_y, edgecolor='white', width = pct)
ax.add_patch(arr)
arr.set_facecolor('g')
ani = animation.FuncAnimation(fig,animate,sorted(df.pickup_hour.unique()), interval = 1000)
plt.close()
ani.save('animation2.html', writer='imagemagick', fps=2)
下面是可视化动态展示纽约一天各个时段出租车的客流趋势:
邻居分析
我们已经得到客流趋势的大概情况,但是具体各个区域之间的客流量数据还不清楚,我们想知道前往各个区域的具体客流量是多少,以及上下车地点在地图上属于哪个区,根据这样一份纽约各个区的经纬度位置数据,将用户的上下车地点分到各个实际的区,如Queens(皇后区),Midtown(曼哈顿区),并计算出各个区之间的客流量数据,并以可视化方式呈现。
首先导入真实的区域数据
neighborhood = {-74.0019368351: 'Chelsea',-73.837549761: 'Queens',-73.7854240738: 'JFK',-73.9810421975:'Midtown-North-West',-73.9862336241: 'East Village',
-73.971273324:'Midtown-North-East',-73.9866739677: 'Brooklyn-parkslope',-73.8690098118: 'LaGuardia',-73.9890572967:'Midtown',-74.0081765545: 'Downtown'
,-73.9213024854: 'Queens-Astoria',-73.9470256923: 'Harlem',-73.9555565018: 'Uppe East Side',
-73.9453487097: 'Brooklyn-Williamsburgt',-73.9745967889:'Upper West Side'}
#添加区域信息
#构造区域名数据框
rides_df=pd.DataFrame(columns=neighborhood.values())
rides_df['name']=neighborhood.values()
将上下车地点与区域位置进行匹配
neigh = KNeighborsClassifier(n_neighbors=1)
neigh.fit(np.array(list(neighborhood.keys())).reshape(-1, 1), list(neighborhood.values()))
# 使用经度作为训练数据,区域名作为目标值(类似于标签)来拟合模型。
#分别取出上车、下车的经度数据,用模型进行预测出最近的区域,作为起始区域,下车区域
df['pickup_neighborhood'] = neigh.predict(df.pickup_longitude.reshape(-1,1))
df['dropoff_neighborhood'] = neigh.predict(df.dropoff_longitude.reshape(-1,1))
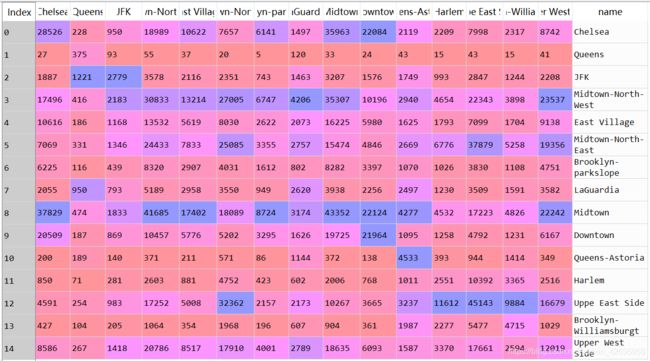
计算各区域之间客流量,生成矩阵
for col in rides_df.columns[:-1]:#取列名的第一个至倒数第二列
rides_df[col] = rides_df.name.apply(lambda x: len(df[(df.pickup_neighborhood == x) & (df.dropoff_neighborhood == col)]))
计算方法:
#对name列每一个(区域名),计算,给列名的每一列赋值,该区域到其他区域的客流量=(name为起始点区域名的个数+col为下车点区域名的个数)
查看矩阵前五行数据:
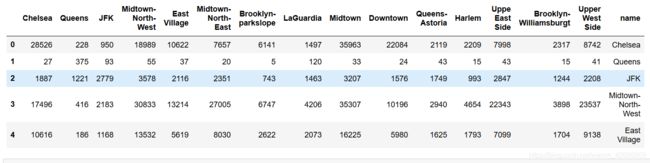
结果: