Python3内置库urllib的使用
1.Python3内置库urllib
1.1 Python3内置库
urllib是Python3中使用url的内置库,包含多个模块。
(1)urllib.request模块:打开和读取urls。
(2)urllib.error模块:包含urllib.request引发的异常。
(3)urllib.parse模块:用于分析urls。
(4)urllib.robotparser模块:用于分析robots.txt文件。
1.2 urllib的官方文档
https://docs.python.org/3/library/index.html
https://docs.python.org/3/library/urllib.request.html
1.3 request和parse模块
1.3.1 request模块中的函数、类
(1)def urlopen(url, data=None, timeout=socket._GLOBAL_DEFAULT_TIMEOUT, cafile=None, capath=None, cadefault=False, context=None)
urlopen的作用是打开url对应的网页,url可以是字符串也可以是Request对象。
(2)class Request:
def __init__(self, url, data=None, headers={},
origin_req_host=None, unverifiable=False,
method=None)
Request是一个对象,包含很多方法。
1.3.2 parse模块中的函数
def urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus)
函数将key-value转换为url格式。
1.4编写代码
1.4.1 get请求
#程序1:爬取百度的html
from urllib import request
#百度的网址不能是https://www.baidu.com/,否则爬取的html不完整
url = 'http://www.baidu.com/'
response = request.urlopen(url)
#使用read返回的是字节码,即bytes
htmls = response.read()
#bytes.decode(encoding="utf-8", errors="strict"):
# 作用:将bytes转换为str,utf-8表示要使用utf-8进行解码
html_str = htmls.decode('utf-8')
#将字节码的html写入一个*.html文件中,保存页面
#可以使用浏览器打开保存html,就会出现保存网页的页面内容
file_handle = open('baidu.html','wb')
file_handle.write(htmls)
file_handle.close()
1.4.2 get请求和Headers
当有些网页为了防止别人他人恶意采集信息而进行反爬虫设置,如一些HTTP服务器只允许来自浏览器的访问请求,而不允许脚本的请求,因此需要使用代码来模拟浏览器。浏览器使用Headers中的User-Agent来标识自身,因此在使用urlopen时需要把Headers的User-Agent也传入。
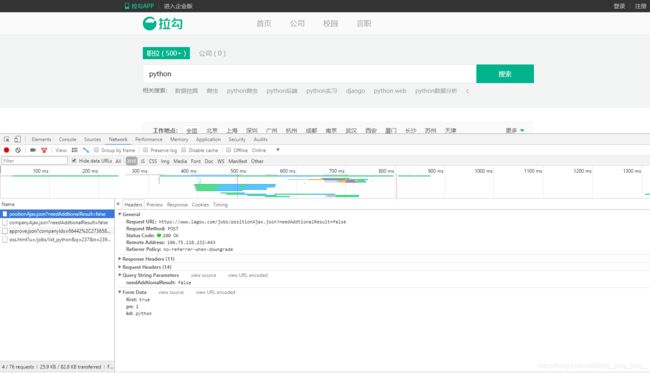
按F12,选择Network-XHR,在Headers一栏就会出现HTTP通信的信息(若没有,就刷新下网页)。

Headers的参数:
(1)User-Agent:这个参数可以携带浏览器名和版本号、操作系统名和版本号、默认语言等信息;作用是用于伪装浏览器。
(2)Referer:可以用来防止盗链,有一些网站图片显示来源https://***.com,就是检查 Referer来鉴定的。
(3)Connection:表示连接状态,记录会话(Session)的状态。
#程序2
from urllib import request
#百度的网址不能是https://www.baidu.com/,否则爬取的html不完整
url = 'http://www.baidu.com/'
heads = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/63.0.3239.132 Safari/537.36',
'Referer': 'https://www.baidu.com/',
'Connection': 'keep-alive'
}
req = request.Request(url,headers=heads)
html_str = request.urlopen(req).read().decode()
print(len(html_str))
运行结果:
155357
1.4.3代理IP
网站会检测某一段时间内某个IP的访问次数,若访问次数过多,会禁止你的访问,因此需要设置代理IP来爬取数据。方法:使用request.ProxyHandler。
#程序3
from urllib import request,parse
def use_proxy(proxy_addr,url):
proxy = request.ProxyHandler({'http':proxy_addr}) #设置proxy
opener = request.build_opener(proxy,request.HTTPHandler) #挂载opener
request.install_opener(opener) #安装opener
htmls = request.urlopen(url).read().decode('utf-8')
return htmls
#获取代理IP:http://31f.cn/
proxy_addr = '115.159.201.179:80'
url = 'http://www.baidu.com'
htmls = use_proxy(proxy_addr,url)
print(len(htmls))
运行结果:
152652
1.4.4 post请求
#程序4
from urllib import request,parse
#在使用\换行后不能使用TAB
url = 'https://www.lagou.com/jobs/list_python?\
city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput='
heads = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/63.0.3239.132 Safari/537.36'
}
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
#urlencode函数将key-value转换成url的格式
# 如first=true&pn=1&kd=python
#encode是编码,将str转换为bytes
data = parse.urlencode(data).encode('utf-8')
req = request.Request(url, data = data, headers = heads)
htmls = request.urlopen(req).read().decode('utf-8')
print(len(htmls))
运行结果:
92665
程序4用于爬取拉勾网下python职位,如下所示。