《Java并发编程之美》学习笔记(二):基础知识
-
什么是并发编程?
并发,同一时间段内多个任务同时都在执行,并且都没有执行结束。并行,单位时间内多个任务同时执行。由于一个时间段是由多个单位时间累积而成,所以说,并发的多个任务在单位时间内不一定同时执行。
在单核CPU时代,多任务是并发执行的,线程都有CPU分配的时间片,同一时间单个cpu只能执行一个任务,其他任务处于挂起状态。并且线程间的频繁上下文切换会带来额外的性能开销。
在多核CPU情况下,线程A和线程B都在各自的CPU上执行,实现了真正意义上的并行。
-
为什么要进行多线程并发编程?
1.多核CPU时代的到来,打破了单核CPU对多线程效能的限制。能减少上下文切换的开销。
2.随着对应用系统性能和吞吐量要求的提高,出现了海量数据和请求。
-
Java中的线程安全问题
1.共享资源:被多个线程所持有或者是多个线程都可以去访问的资源。
2.线程安全问题:多个线程同时读写一个共享资源并且没有任何同步措施,导致出现脏数据或者其他不可预见的结果。
-
共享变量的内存可见性问题
java内存模型:是一个抽象的概念,其规定,将所有的变量都放到主内存中,当程序使用变量时,从主内存里的变量复制到自己的工作空间或者工作内存中,线程读写时所操作的是自己内存中的变量。
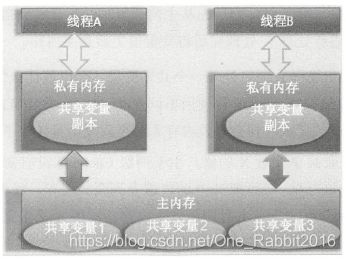
实际中的工作内存:cpu框架+内存

CPU简单介绍:cpu每核都有自己的控制器和运算器;CPU每一核都有一级缓存;所有CPU共享二级缓存;
控制器包括:一组寄存器(容量小,临时记忆,处理速度快,是内存的100倍)和操作控制器
运算器:执行算数逻辑运算。
当一个线程操作共享变量时, 它首先从主内存复制共享变量到自己的工作内存, 然后对工作内存里的变量进行处理, 处理完后将变量值更新到主内存。假设线程A 和线程B 使用不同CPU 执行,并且当前两级Cache 都为空,那么这时候由于C ache 的存在,将会导致内存不可见问题:
假设共享变量X=0值,在主内存中,此时线程A需要使用,但是在cache1,cache2中都没命中,则需要去主内存中复制到两级缓存中,然后线程A将X=1,保存到1级缓存,同步到2级缓存,然后同步主内存;
其次线程B需要使用X,同样,他的1级缓存没有命中,但是2级缓存有之前线程A写入的X=1; 然后线程B把 X=2,并同步到了两级缓存和主内存,此时主内存,2级缓存,X=2;
这时候线程A 有获取X,并且他的一级缓存命中x=1;问题就来了,线程A 和线程B 的一级缓存是各自不可见的。所以A看不到B已经把X改成2了。那么如何解决共享变量内存不可见问题?继续往下看
-
Java中的synchronized关键字
synchronized 块是Java 提供的一种原子性内置锁, Java 中的每个对象都可以把它当作一个同步锁来使用, 这些Java 内置的使用者看不到的锁被称为内部锁,也叫作监视器锁。线程的执行代码在进入synchronized 代码块前会自动获取内部锁,这时候其他线程访问该同步代码块时会被阻塞挂起。
如何释放锁?拿到内部锁的线程会在正常退出同步代码块或者抛出异常后或者在同步块内调用了该内置锁资源的wait 系列方法时释放该内置锁。
内置锁是排它锁,也就是当一个线程获取这个锁后, 其他线程必须等待该线程释放锁后才能获取该锁。
由于Java 中的线程是与操作系统的原生线程一一对应的,所以当阻塞一个线程时,需要从用户状态切换到内核状态执行阻塞操作,这是很耗时的操作,而synchronized 的使用就会导致上下文切换。
synchronized的内存语义:这个内存语义就可以解决共享变量内存可见性问题。
1.加锁时(进入synchronized 块),会清空锁块内本地内存中将会被用到的共享变量,在使用这些共享变量时从主内存进行加载;
2.释放时(退出synchronized 块),将本地内存中修改的共享变量刷新到主内存。
除可以解决共享变量内存可见性问题外, synch ronized 经常被用来实现原子性操作。另外请注意,synchronized 关键字会引起线程上下文切换并带来线程调度开销。
-
Java中的volatile关键字
由于加锁的方式太笨重,还会带来线程上下文的切换开销。对于解决内存可见性问题,java还提供了一种弱形式同步volatile,该关键字可以确保对一个变量的更新对其他线程马上可见。
当一个变量被声明为volatile 时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存。当其他线程读取该共享变量时,会从主内存重新获取最新值,而不是使用当前线程的工作内存中的值。
volatile 的内存语义:当线程写入了volatile 变量值时就等价于线程退出synchronized同步块(把写入工作内存的变量值同步到主内存),读取volatile 变量值时就相当于进入同步块( 先清空本地内存变量值,再从主内存获取最新值)
synchronized于volatile比较:二者都可以解决内存可见性问题。
synchronized:独占锁,会造成其他线程堵塞,同时会存在线程上下文切换和线程重新调度的开销。但是操作是原子性。
volatile:非阻塞算法, 不会造成线程上下文切换的开销。操作非原子性。
一般在什么时候才使用volatile 关键字呢?
1.写入变量值不依赖、变量的当前值时。因为如果依赖当前值,将是获取一计算一写入三步操作,这三步操作不是原子性的,而volatile 不保证原子性。
2.读写变量值时没有加锁。因为加锁本身已经保证了内存可见性,这时候不需要把变量声明为volatile 的。
-
Java中的原子性
(1)使用synchronized关键字,线程安全,解决内存可见性问题,操作原子性。但是会阻塞线程,有上下文切换的开销。
(2)使用非阻塞的CAS算法实现原子性操作。
-
Java中的CAS操作
CAS 即Compa re and Swap ,其是JDK 提供的非阻塞原子性操作, 它通过硬件保证了比较更新操作的原子性。JDK 里面的Unsafe 类提供了一系列的compareAndSwap *方法。
关于CAS 操作有个经典的ABA 问题:ABA 问题的产生是因为变量的状态值产生了环形转换,就是变量的值可以从A 到B,
然后再从B 到A。如果变量的值只能朝着一个方向转换,比如A 到B , B 到C , 不构成环形,就不会存在问题。JDK 中的AtomicStampedReference 类给每个变量的状态值都配备了一个时间戳, 从而避免了ABA 问题的产生。
-
Unsafe类
JDK 的rt.jar 包中的Unsafe 类提供了硬件级别的原子性操作, Unsafe 类中的方法都是native 方法,它们使用JNI 的方式访问本地C++实现库。

结果为TRUE;
-
Java指令重排序
Java 内存模型允许编译器和处理器对指令重排序以提高运行性能, 并且只会对不存在数据依赖性的指令重排序。
在单线程下重排序可以保证最终执行的结果与程序顺序执行的结果一致,但是在多线程下就会存在问题。
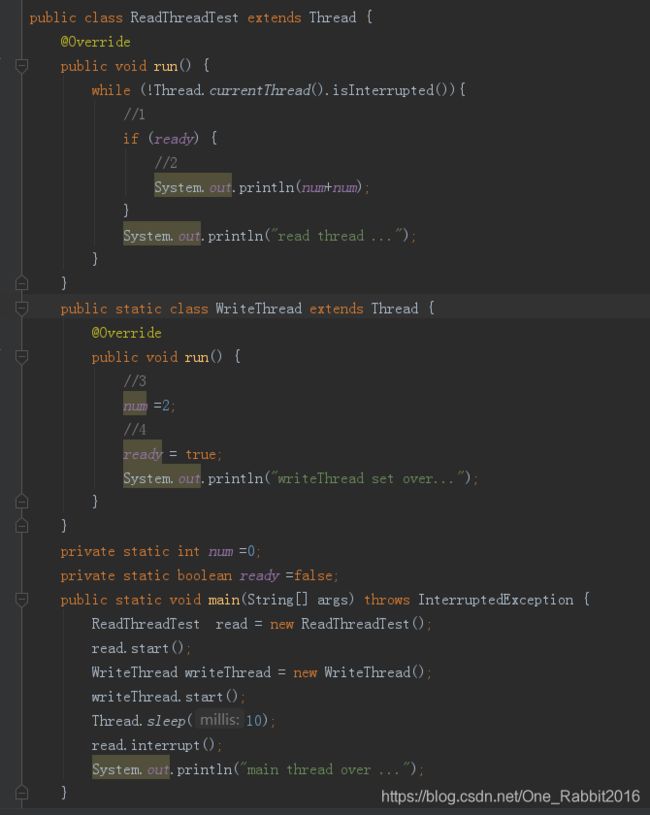
这里先看看指令重排序会造成什么影响,如上代码在不考虑、内存可见性问题的情况下一定会输出4 ? 答案是不一定,由于代码(1 ) ( 2 ) ( 3 ) ( 4 )之间不存在依赖关系, 所以写线程的代码(3) ( 4 )可能被重排序为先执行( 4 )再执行。) , 那么执行( 4 )后, 读线程可能已经执行了(1 )操作, 并且在( 3 )执行前开始执行( 2 )操作, 这时候输出结果为0。而不是4
重排序在多线程下会导致非预期的程序执行结果,而使用volatile 修饰ready 就可以避免重排序和内存可见性问题。
写volatile 变量时,可以确保volatile 写之前的操作不会被编译器重排序到volatile 写之后。读volatile 变量时,可以确保volatile 读之后的操作不会被编译器重排序到volatile读之前。
-
伪共享
(1)什么是伪共享?
为了解决计算机系统中主内存与CPU 之间运行速度差问题,会在CPU 与主内存之间添加一级或者多级高速缓冲存储Cache
 之前提到过,每核cpu独享1级缓存,共享2级缓存。
之前提到过,每核cpu独享1级缓存,共享2级缓存。
在Cache内部是按行存储的,其中每一行称为一个Cache行,是Cache与主内存进行数据交换的单位。
 当CPU 访问某个变量时,首先会去看CPU Cache 内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache 行大小的内存复制到Cache 中。由于存放到Cache 行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache 行中。(程序运行的局部性原理)
当CPU 访问某个变量时,首先会去看CPU Cache 内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache 行大小的内存复制到Cache 中。由于存放到Cache 行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache 行中。(程序运行的局部性原理)
当多个线程同时修改一个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,所以相比将每个变量放到一个缓存行,性能会有所下降,这就是伪共享。
所以在单个线程下顺序修改一个缓存行中的多个变量,会充分利用程序运行的局部性原则,从而加速了程序的运行。而在多线程下并发修改一个缓存行中的多个变量时就会竞争缓存行,从而降低程序运行性能。
(2)如何避免伪共享?
在JDK 8 之前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中。
JDK 8 提供了一个sun.misc.Contended 注解,用来解决伪共享问题。这注解用来修饰类,当然也可以修饰变量。
在默认情况下,@Contended 注解只用于Java 核心类, 比如此包下的类。如果用户类路径下的类需要使用这个注解, 则需要添加NM 参数:-XX:-RestrictContended 。填充的宽度默认为128 ,要自定义宽度则可以设置-XX : Con nd巳dPaddingWidth 参数。
(3)总结:在多线程下访问同一个缓存行的多个变量时才会出现伪共享,在单线程下访问一个缓存行里面的多个变量反而会对程序运行起到加速作用
-
锁的概念
(1)乐观锁与悲观锁
乐观锁和悲观锁是在数据库中引入的名词。
悲观锁指对数据被外界修改持保守态度,认为数据很容易就会被其他线程修改,所以在数据被处理前先对数据进行加锁,并在整个数据处理过程中,使数据处于锁定状态。悲观锁的实现往往依靠数据库提供的锁机制,即在数据库中,在对数据记录操作前给记录加排它锁。如果获取锁失败, 则说明数据正在被其他线程修改, 当前线程则等待或者抛出异常。如果获取锁成功,则对记录进行操作,然后提交事务后释放排它锁。select * from table for update; commint;
乐观锁是相对悲观锁来说的,它认为数据在一般情况下不会造成冲突,所以在访问记录前不会加排它锁,而是在进行数据提交更新时,才会正式对数据冲突与否进行检测; update table set a=1 where id = 1 and version=version;这有点CAS 操作的意思。
乐观锁并不会使用数据库提供的锁机制, 一般在表中添加version 宇段或者使用业务状态来实现。乐观锁直到提交时才锁定,所以不会产生任何死锁。
(2)公平锁与非公平锁
根据线程获取锁的抢占机制,锁可以分为公平锁和非公平锁,公平锁表示线程获取锁的顺序是按照线程请求锁的时间早晚来决定的,也就是最早请求锁的线程将最早获取到锁。而非公平锁则在运行时闯入,也就是先来不一定先得。
ReentrantLock 提供了公平和非公平锁的实现。
公平锁: ReentrantLock pairLock =new ReentrantLock(true) 。
非公平锁: ReentrantLock pairLock =new ReentrantLock(false) 。如果构造函数不传递参数,则默认是非公平锁。
在没有公平性需求的前提下尽量使用非公平锁,因为公平锁会带来性能开销。
(3)独占锁与共享锁、
根据锁只能被单个线程持有还是能被多个线程共同持有,锁可以分为独占锁和共享锁。
独占锁保证任何时候都只有一个线程能得到锁, ReentrantLock 就是以独占方式实现的。共享锁则可以同时由多个线程持有,例如ReadWriteLock 读写锁,它允许一个资源可以被多线程同时进行读操作
独占锁是一种悲观锁,由于每次访问资源都先加上互斥锁,这限制了并发性,因为读操作并不会影响数据的一致性,而独占锁只允许在同一时间由一个线程读取数据,其他线程必须等待当前线程释放锁才能进行读取。
共享锁则是一种乐观锁,它放宽了加锁的条件,允许多个线程同时进行读操作。
(4)可重入锁
当一个线程要获取一个被其他线程持有的独占锁时,该线程会被阻塞。
那么当一个线程再次获取它自己己经获取的锁时,不会被阻塞,那么我们说该锁是可重入的,也就是只要该线程获取了该锁,那么可以无限次数(严格来说是有限次数)地进入被该锁锁住的代码。

在如上代码中,调用helloB 方法前会先获取内置锁,然后打印输出。之后调用helloA方法,在调用前会先去获取内置锁,如果内置锁不是可重入的,那么调用线程将会一直被阻塞。
实际上, synchronized 内部锁是可重入锁。可重入锁的原理是在锁内部维护一个线程标示,用来标示该锁目前被哪个线程占用,然后关联一个计数器。一开始计数器值为0,说明该锁没有被任何线程占用。当一个钱程获取了该锁时,计数器的值会变成1 ,这时其他线程再来获取该锁时会发现锁的所有者不是自己而被阻塞挂起。
但是当获取了该锁的线程再次获取锁时发现锁拥有者是自己,就会把计数器值加+1,当释放锁后计数器值-1 。当计数器值为0 时,锁里面的线程标示被重置为null , 这时候被阻塞的线程会被唤醒来竞争获取该锁。
(5)自旋锁
由于Java 中的线程是与操作系统中的线程一一对应的,所以当一个线程在获取锁(比如独占锁)失败后,会被切换到内核态而被挂起。当该线程获取到锁时又需要将其切换到内核状态而唤醒该线程。而从用户态切换到内核态的开销是比较大的,在一定程度上会影响并发性能。
自旋锁则是,当前线程在获取锁时,如果发现锁已经被其他线程占有,它不马上阻塞自己,在不放弃CPU 使用权的情况下,多次尝试获取(jdk1.6之后,默认开启,默认次数是10 ,可以使用-XX :PreBlockSpinsh 参数设置该值;-XX:+UserSpinning参数可以开启关闭自旋),很有可能在后面几次尝试中其他线程己经释放了锁。如果尝试指定的次数后仍没有获取到锁则当前线程才会被阻塞挂起。由此看来自旋锁是使用CPU 时间换取线程阻塞与调度的开销,但是很有可能这些CPU 时间白白浪费了。
在Jdk 1.6中引入了自适应的自旋锁,这意味着自旋的时间不是固定的,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态决定的。简单来说,就是在同一个锁对象上,自旋等待成功获取到锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也有可能再次成功,进而将允许自旋等待持续相对更长的时间,比如100个循环。反之,如果某个锁,自旋很少成功,那以后在获取这个锁时将直接忽略自旋过程,以免浪费CPU资源。
学习笔记(一)和学习笔记(二)一些概念性的东西,之前对于多线程,在开发中很少用到,从来没系统性的看过书,面试的时候会翻看下相关知识。现在梳理下,为之后深入学习,打好基础。