Python Scrapy 爬取知乎首页问题及相应问题的首页回答
首先分析一下所给题目的要求:
题目:爬取知乎首页问题及问题的回答
1) 登录后的知乎首页
2) 只需第一页的问题及相应问题的第一页回答(回答只需提取文字)
3) 使用Scrapy框架
分析:
1:所要爬取的问题来自于“登录”后的知乎首页,那么首先要解决的是“知乎的登录问题”。
2:问题只需要第一页上面的几个问题(回答也是),意味着不用去考虑知乎首页动态加载的问题,只需要获取登录后的首页所包含的问题链接,然后再对所提取的response用BeautifulSoup进行解析,提取所要的信息。回答只需要提取文字,意味着不用考虑回答中图片的下载问题。
3:要使用Scrapy框架来爬取,在看到这个题目之前,只学过request,所以还要去学一下Scrapy框架。mooc上面北理的“Python网络爬虫与信息提取”里面有Scrapy框架的部分,还有Scrapy的文档,学完之后再结合博客上的“小白进阶之Scrapy”的几篇总结,基本上可以完成这个题目。
PS:第一次用Scrapy框架(小白一枚),文章可能有不严谨的地方,欢迎指正!
Scrapy框架的小总结:
爬虫框架是实现爬虫功能的一个软件结构和功能组件集合,是一个半成品。简单来说,框架可以帮我们处理一部分事情,比如下载模块不用我们自己写了,我们只需专注于提取数据就好了,最重要的是,框架使用了异步的模式,可以加快我们的下载速度,而不用自己去实现异步框架。
Scrapy的框架结构(5+2结构):

数据流(requests,response)的三个路径 :
第一条路径:
① :Engine从Spider处获得爬取请求(Request)
② :Engine将爬取请求转发给Scheduler,用于调度
第二条路径:
③ :Engine从Scheduler处获得下一个要爬取的请求
④ :Engine将爬取请求通过中间件发送给Downloader
⑤ :爬取网页后,Downloader形成响应(Response) 通过中间件发给Engine
⑥ : Engine将收到的响应通过中间件发送给Spider处理
第三条路径:
⑦ :Spider处理响应后产生爬取项(scraped Item) 和新的爬取请求(Requests)给Engine
⑧ :Engine将爬取项发送给Item Pipeline(框架出口)并且Engine将爬取请求发送给Scheduler
数据流的出入口:
Engine控制各模块数据流,不间断从Scheduler处 获得爬取请求,直至请求为空
框架入口:Spider的初始爬取请求
框架出口:Item Pipeline
各模块(结构)的作用:
Spider(需要用户编写配置代码):
(1)解析Downloader返回的响应(Response)
(2)产生爬取项(scraped item)
(3)产生额外的爬取请求(Request)
Item Pipelines (需要用户编写配置代码):
(1)以流水线方式处理Spider产生的爬取项
(2)由一组操作顺序组成,类似流水线,每个操 作是一个Item Pipeline类型
(3)可能操作包括:清理、检验和查重爬取项中 的HTML数据、将数据存储到数据库
Engine(不需要用户修改):
(1)控制所有模块之间的数据流
(2)根据条件触发事件
Downloader(不需要用户修改): 根据请求下载网页
Scheduler(不需要用户修改): 对所有爬取请求进行调度管理
Downloader Middleware(用户可以编写配置代码):
目的:实施Engine、Scheduler和Downloader 之间进行用户可配置的控制
功能:修改、丢弃、新增请求或响应
Spider Middleware(用户可以编写配置代码):
目的:对请求和爬取项的再处理
功能:修改、丢弃、新增请求或爬取项
具体编程分析():
对于这道题只需要编写Spider和Item Pipelines这两个模块中的文件即可。
安装好Scrapy库后,要创建一个项目,CMD进入你需要放置项目的目录 输入:
- scrapy startproject XXXX #XXXX是你的项目名称
这个命令会在对应目录中生成一些文件,也就是项目。

项目创建完成后:
第一件事:是在items.py文件中定义一些字段,这些字段用来临时存储你需要保存的数据。方便后面保存数据到其他地方,比如本地文本之类的。
第二件事:在spiders文件夹中编写自己的爬虫(CMD进入所生成的项目的目录,用语句:scrapygenspider[options]
第三件事:在pipelines.py中存储自己的数据。
还有一件事:一般来说不是非做不可的,settings.py文件并不是一定要编辑的,只有有需要的时候才会编辑,我最后把提取的内容存为了txt文件,所以要在settings.py文件中设置。
ITEM_PIPELINES = {
'scrapy_zhihu.pipelines.ScrapyZhihuPipeline': 300,
} #在settings.py文件中找到ITEM_PIPELINES并取消注释,将里面的值赋为300。 所以我们只需要编辑:items.py,spider_name.py和pipelines.py这3个文件即可。
再明确一下其中最重要的spider_name.py文件的三个任务:
(1):生成HTTP请求request(即要访问的URL,如登录时访问的首页URL,首页中提取出来的问题URL)
(2):处理(解析)Download生成的response(即提取所需要的的信息,用BeautifulSoup对response解析)
(3):生成Item(提取的信息,return item)
知乎的登录问题:
一般不用登录的网页,爬取的时候直接把网页的链接当成request就可以,比较简单。而现在要提取的是首页的问题,那么首先必须得先登录,即spider_name.py文件中申请的request是包含了你的登录信息的。而request中的登录信息就是浏览器的cookies,那这个cookies在哪呢?
首先打开一个浏览器并登录你的知乎账号,然后按F12,右上角点击Application,找到左边一栏的Cookies,它就包含了你的登录信息(用的是Chrome浏览器)。
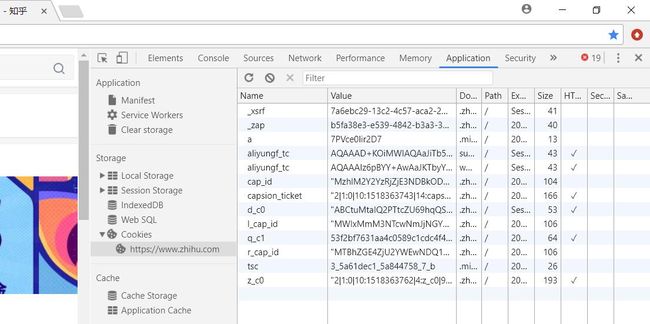
可以发现cookies就是一个字典(Name当成key),我们把它全部都复制下来放到一个字典里面。
- #登录用的cookis
- cookies = {
- "_xsrf" : "204e9e85-ee81-4105省略...",
- "_zap" : "18e5599a-4e8a省略...",
- "aliyungf_tc" : "AQAAAIxDfh/mF省略...",
- "capsion_ticket" : '"2|1:0|10:1518403781|省略...',
- "d_c0" : '"AIArj3sOIg2PTrI8uwZzbyQs省略..."', #注意value值中双引号也要放进去。
- "q_c1" : "8a49a7dc25664e6ea76fe6c57省略...",
- "z_c0" : '"2|1:0|10:1518403797|4:z_c0|80:MS4x省略..."',
- }
知乎的模拟登录问题,网上有挺多总结的,直接复制浏览器的cookis应该是最简单粗暴的了。
登录的问题搞清楚之后,那么我们直接就开始编写items.py,spider_name.py和pipelines.py这3个文件了。
首先我想先编写spider_name.py这个文件(爬虫),完成它的三个任务之后可以打印出来所提取的信息,看看效果如何,如何再去编写其他两个文件,存储所提取的信息。
zhihu_spider.py文件的编写:
创建项目后,CMD进入生成的项目目录。
- C:\python\scrapy_zhihu>scrapy genspider zhihu_spider www.zhihu.com
下面是Scrapy文档中Spiders模块中的一部分,理解下面这些定义才能编写zhihu_spider.py,更多内容见Scrapy文档。
Spiders¶
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
对spider来说,爬取的循环类似下文:
-
以初始的URL初始化Request,并设置回调函数。当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用
start_requests()来获取的。start_requests()读取start_urls中的URL,并以parse为回调函数生成Request。 -
在回调函数内分析返回的(网页)内容,返回
Item对象、dict、Request或者一个包括三者的可迭代容器。返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。 -
在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
-
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。
scrapy.Spider¶
-
class
scrapy.spiders.Spider¶ -
Spider是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。 Spider并没有提供什么特殊的功能。其仅仅提供了
start_requests()的默认实现,读取并请求spider属性中的start_urls, 并根据返回的结果(resulting responses)调用spider的parse方法。-
name¶ -
定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的。
如果该spider爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加 后缀 )来命名spider。例如,如果spider爬取
mywebsite.com,该spider通常会被命名为mywebsite。
-
allowed_domains¶ -
可选。包含了spider允许爬取的域名(domain)列表(list)。当
OffsiteMiddleware启用时,域名不在列表中的URL不会被跟进。
-
start_urls¶ -
URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。因此,第一个被获取到的页面的URL将是该列表之一。后续的URL将会从获取到的数据中提取。
-
start_urls, 并根据返回的结果(resulting responses)调用spider的 parse 方法。
-
name¶ -
定义spider名字的字符串(string)。spider的名字定义了Scrapy如何定位(并初始化)spider,所以其必须是唯一的。不过您可以生成多个相同的spider实例(instance),这没有任何限制。 name是spider最重要的属性,而且是必须的。
如果该spider爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加 后缀 )来命名spider。例如,如果spider爬取
mywebsite.com,该spider通常会被命名为mywebsite。
-
allowed_domains¶ -
可选。包含了spider允许爬取的域名(domain)列表(list)。当
OffsiteMiddleware启用时,域名不在列表中的URL不会被跟进。
-
start_urls¶ -
URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取。因此,第一个被获取到的页面的URL将是该列表之一。后续的URL将会从获取到的数据中提取。
-
start_requests( ) ¶ -
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request。
当spider启动爬取并且未制定URL时,该方法被调用。当指定了URL时,
make_requests_from_url()将被调用来创建Request对象。该方法仅仅会被Scrapy调用一次,因此您可以将其实现为生成器。该方法的默认实现是使用
start_urls的url生成Request。如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。例如,如果您需要在启动时以POST登录某个网站,你可以这么写:
class MySpider(scrapy.Spider): name = 'myspider' def start_requests(self): return [scrapy.FormRequest("http://www.example.com/login", formdata={'user': 'john', 'pass': 'secret'}, callback=self.logged_in)] def logged_in(self, response): # here you would extract links to follow and return Requests for # each of them, with another callback pass
-
make_requests_from_url( url ) ¶ -
该方法接受一个URL并返回用于爬取的
Request对象。该方法在初始化request时被start_requests()调用,也被用于转化url为request。默认未被复写(overridden)的情况下,该方法返回的Request对象中,
parse()作为回调函数,dont_filter参数也被设置为开启。 (详情参见Request).
-
parse( response ) ¶ -
当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse负责处理response并返回处理的数据以及(/或)跟进的URL。Spider对其他的Request的回调函数也有相同的要求。该方法及其他的Request回调函数必须返回一个包含
Request、dict 或Item的可迭代的对象。参数: response ( Response) – 用于分析的response
理解完之后,梳理一下代码的整体思路:
由方法:start_requests()产生(初始化)第一个request(它包含了登录信息的cookies),当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数(get_questions_url())。
- #初始化登录后的首页的request
- def start_requests(self):
- return [scrapy.Request("https://www.zhihu.com/",cookies = self.cookies,callback = self.get_questions_url,headers = self.headers)]
方法:start_requests()的回调函数为get_questions_url(),即start_requests()调用了get_questions_url(),get_questions_url(self,response)中的respons就是表示登录后的首页,用BeautifulSoup解析出首页所包含的问题的URL(链接),再把这些URL全部生成为request,然后设置回调函数为parse()(用yield生成器,一个request调用一次parse())。
- #获取首页的问题链接,并生成对应的request
- def get_questions_url(self,response):
- data = response.body
- soup = BeautifulSoup(data,"html.parser")
- for item in soup.find_all('a',attrs={'data-za-detail-view-element_name':"Title"}):
- if item['href'][1:9] == 'question' : #首页中的链接还有专栏的文章,去掉这些链接
- question_url = "https://www.zhihu.com" + item['href']
- yield scrapy.Request(question_url,cookies = self.cookies,callback=self.parse,headers=self.headers)
方法:parse(self,response)的参数response表示从首页中所提取的问题,用BeautifulSoup解析问题中的信息,在还没有编写items.py和pipelines.py这两个文件时,可以先打印出所提取的信息是否准确并适当修改。

最后,items.py和pipelines.py编写完成后的zhihu_spider.py完整代码如下:
- # -*- coding: utf-8 -*-
- #引入要用到的库
- import scrapy
- import re
- from bs4 import BeautifulSoup
- from scrapy_zhihu.items import ScrapyZhihuItem #引入items.py文件中的ScrapyZhihuItem类,zhihu_spoder.py任务之一是要return item 这个item就是这个类的实例
- class ZhihuSpiderSpider(scrapy.Spider): #zhihu_spider是ZhihuSpiderSpider类的一个实例,下面定义了类的属性和方法。
- name = 'zhihu_spider'
- allowed_domains = ['www.zhihu.com']
- # start_urls = ['http://www.zhihu.com'] #命令行创建爬虫时默认生成的,可以不用。包含了Spider在启动时进行爬取的url列表。
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36'
- }
- #登录用的cookis
- cookies = {
- "_xsrf" : "204e9e85省略...",
- "_zap" : "18e55省略...",
- "aliyungf_tc" : "AQAAAI省略...",
- "capsion_ticket" : '"2|1:0|10:151840省略...',
- "d_c0" : '"AIArj3sOIg2PT省略...',
- "q_c1" : "8a49a7dc256省略...",
- "z_c0" : '"2|1:0|10:1518403797|4:z_c0|80:MS4xZXg5dEFBQU省略...',
- }
- #初始化登录后的首页的request
- def start_requests(self):
- return [scrapy.Request("https://www.zhihu.com/",cookies = self.cookies,callback = self.get_questions_url,headers = self.headers)]
- #获取首页的问题链接,并生成对应的request
- def get_questions_url(self,response):
- data = response.body
- soup = BeautifulSoup(data,"html.parser")
- for item in soup.find_all('a',attrs={'data-za-detail-view-element_name':"Title"}):
- if item['href'][1:9] == 'question' : #首页中的链接还有专栏的文章,去掉这些链接
- question_url = "https://www.zhihu.com" + item['href']
- yield scrapy.Request(question_url,cookies = self.cookies,callback=self.parse,headers=self.headers)
- #用BeautifulSoup解析response(问题页面)中的信息,并且return item
- def parse(self,response):
- item = ScrapyZhihuItem() #实例化ScrapyZhihuItem类
- soup = BeautifulSoup(response.body,"html.parser")
- #所要信息的提取
- url = response.url
- answer = soup.find(class_='ContentItem AnswerItem')
- author_name = re.findall(r".*itemId",answer['data-zop'])[0][15:-9]
- question_title = soup.find('h1',class_='QuestionHeader-title').get_text()
- question_detail = soup.find('div',class_='QuestionHeader-detail').get_text()[0:-4]
- vote = soup.find_all('span',class_='Voters')
- answer_detail = soup.find('span',class_='RichText CopyrightRichText-richText').get_text('\n','') #实现换行
- #item字典的赋值
- item['question_title'] = question_title
- item['question_detail'] = question_detail
- item['question_url'] = url
- item['answer_detail'] = answer_detail
- item['answer_author'] = author_name
- #赞同者这个信息有时候有,有时候没有
- if len(vote) != 0: #
- voters = vote[0].get_text()
- item['answer_voters'] = voters
- else:
- item['answer_voters'] = '无'
- return item
- #首页中所包含的问题的request(链接)所生成的response里面只包含了一个回答(soup.prettify()打印后发现)。
- #但是平时我们从首页中点击相应的问题链接,进入具体问题的页面却发现有3个回答(多出来的两个回答上面显示“更多回答”)
- #多次尝试后发现,进入具体问题的页面,其实一开始只有一个答案,但是很快知乎会动态加载出其他两个回答。
items.py文件的编写:
item是ScrapyZhihuItem类的实例化,可以当成字典来理解,按照该文件的提示,根据所提取的内容来定义。
- # -*- coding: utf-8 -*-
- # Define here the models for your scraped items
- #
- # See documentation in:
- # https://doc.scrapy.org/en/latest/topics/items.html
- import scrapy
- class ScrapyZhihuItem(scrapy.Item):
- # define the fields for your item here like:
- # name = scrapy.Field()
- question_title = scrapy.Field()
- question_detail = scrapy.Field()
- question_url = scrapy.Field()
- answer_author = scrapy.Field()
- answer_voters = scrapy.Field()
- answer_detail = scrapy.Field()
把所提取到的信息存到txt文件中。
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class ScrapyZhihuPipeline(object):
def process_item(self, item, spider):
with open('data.txt','a') as f: #注意settings.py文件中对应的设置
f.write('--------------------------------------' + '\n')
f.write('问题标题:' + item['question_title'] + '\n')
f.write('问题详情:' + item['question_detail'] + '\n')
f.write('问题URL:' + item['question_url'] + '\n')
f.write('作者:' + item['answer_author'] + '\n')
f.write(item['answer_voters'] + '\n')
f.write('回答如下:'+ '\n' + item['answer_detail'] + '\n')
f.write('--------------------------------------' + '\n')
return item