1.背景
出现多次Unable to close file情况,具体如下。
Client:
| Caused by: java.io.IOException: Unable to close file because the last block does not have enough number of replicas.
at org.apache.hadoop.hdfs.DFSOutputStream.completeFile(DFSOutputStream.java:2306)
at org.apache.hadoop.hdfs.DFSOutputStream.closeImpl(DFSOutputStream.java:2267)
at org.apache.hadoop.hdfs.DFSOutputStream.close(DFSOutputStream.java:2232)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.close(FSDataOutputStream.java:72)
at org.apache.hadoop.fs.FSDataOutputStream.close(FSDataOutputStream.java:106)
|
NN:
| 2020-03-17 12:15:12,337 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: BLOCK* blk_xxx is COMMITTED but not COMPLETE(numNodes= 0 < minimum = 1) in file /xxx
|
找到文件所在的dn日志,发现量的Deleted BP-xxx blk_xxx。初步分析为dn同步处理nn删除块的命令耗时太久,心跳汇报超时,客户端向nn发送rpc请求检测到文件状态不是complete状态,因此报错。本文就dn和nn处理无效块的逻辑做梳理,并对上述问题的解决方案做评估。
2.删除逻辑分析
1.删除文件NameNode入口
NameNode响应客户端delete请求的入口是NameNodeRpcServer.delete() → FSNamesystem.delete()。这里一共分为两步:
- 从namespace中删除文件信息并收集删除的block
- 将待删除的块加到invalidateBlocks中
| //FSNamesystem#delete
boolean delete(String src, boolean recursive, boolean logRetryCache)
throws IOException {
final String operationName = "delete";
BlocksMapUpdateInfo toRemovedBlocks = null;
checkOperation(OperationCategory.WRITE);
final FSPermissionChecker pc = getPermissionChecker();
writeLock();
boolean ret = false;
try {
checkOperation(OperationCategory.WRITE);
checkNameNodeSafeMode("Cannot delete " + src);
//1.从namespace中删除并返回收集到的block块
toRemovedBlocks = FSDirDeleteOp.delete(
this, pc, src, recursive, logRetryCache);
ret = toRemovedBlocks != null;
} catch (AccessControlException e) {
logAuditEvent(false, operationName, src);
throw e;
} finally {
writeUnlock(operationName);
}
//记录到editlog
getEditLog().logSync();
if (toRemovedBlocks != null) {
//2.删除数据块操作
removeBlocks(toRemovedBlocks); // Incremental deletion of blocks
}
logAuditEvent(true, operationName, src);
return ret;
}
|
第一步:从namespace中删除文件信息并收集待删除的block
| // FSDirDeleteOp#unprotectedDelete
private static boolean unprotectedDelete(FSDirectory fsd, INodesInPath iip,
ReclaimContext reclaimContext, long mtime) {
assert fsd.hasWriteLock();
// 检查INode是否存在
// check if target node exists
INode targetNode = iip.getLastINode();
if (targetNode == null) {
return false;
}
// 修改快照
// record modification
final int latestSnapshot = iip.getLatestSnapshotId();
targetNode.recordModification(latestSnapshot);
// 核心部分:从namespace中移除INode
// Remove the node from the namespace
long removed = fsd.removeLastINode(iip);
if (removed == -1) {
return false;
}
// 更新父目录的mtime
// set the parent's modification time
final INodeDirectory parent = targetNode.getParent();
parent.updateModificationTime(mtime, latestSnapshot);
// 收集待删除的块并更新quota,reclaimContext对象就是最后要返回的待删除的块
// collect block and update quota
if (!targetNode.isInLatestSnapshot(latestSnapshot)) {
targetNode.destroyAndCollectBlocks(reclaimContext);
} else {
targetNode.cleanSubtree(reclaimContext, CURRENT_STATE_ID, latestSnapshot);
}
if (NameNode.stateChangeLog.isDebugEnabled()) {
NameNode.stateChangeLog.debug("DIR* FSDirectory.unprotectedDelete: "
+ iip.getPath() + " is removed");
}
return true;
}
|
第二步:将待删除的块加到invalidateBlocks中
| // FSNamesystem#removeBlocks
void removeBlocks(BlocksMapUpdateInfo blocks) {
List toDeleteList = blocks.getToDeleteList();
Iterator iter = toDeleteList.iterator();
while (iter.hasNext()) {
writeLock();
try {
//循环收集到的块,这里双重限制:常量限制和块数量限制
for (int i = 0; i < blockDeletionIncrement && iter.hasNext(); i++) {
blockManager.removeBlock(iter.next());
}
} finally {
writeUnlock("removeBlocks");
}
}
}
|
上述需要注意的是 blockDeletionIncrement 值,每次默认限制删除块的增量是1000.
| this.blockDeletionIncrement = conf.getInt(
DFSConfigKeys.DFS_NAMENODE_BLOCK_DELETION_INCREMENT_KEY,
DFSConfigKeys.DFS_NAMENODE_BLOCK_DELETION_INCREMENT_DEFAULT);
其中:
DFS_NAMENODE_BLOCK_DELETION_INCREMENT_KEY = "dfs.namenode.block.deletion.increment";
DFS_NAMENODE_BLOCK_DELETION_INCREMENT_DEFAULT = 1000;
|
做 blockDeletionIncrement 限制的目的是从blockManager中逐步删除块。并且每次到 blockDeletionIncrement 时,writeLock()会释放然后重新获取,确保其他服务能够进来。
| // BlockManager#removeBlock
public void removeBlock(BlockInfo block) {
assert namesystem.hasWriteLock();
// No need to ACK blocks that are being removed entirely
// from the namespace, since the removal of the associated
// file already removes them from the block map below.
block.setNumBytes(BlockCommand.NO_ACK); //设置这个块的字节为LONG最大
addToInvalidates(block); //添加到invalidates集合中
removeBlockFromMap(block); //从BlocksMap中删除
// Remove the block from pendingReconstruction and neededReconstruction
//从需要构建和等待构建的block集合中删除
pendingReconstruction.remove(block);
neededReconstruction.remove(block, LowRedundancyBlocks.LEVEL);
postponedMisreplicatedBlocks.remove(block);
}
|
上述流程图如下。后续操作便是对无效块集合的处理。

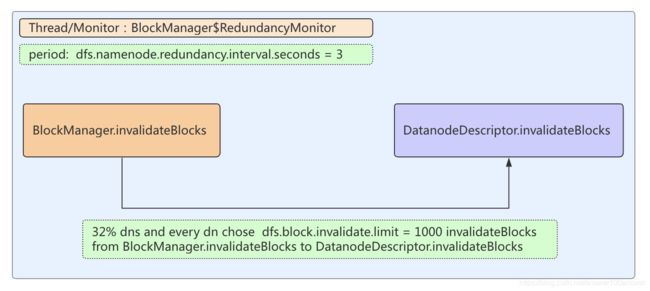
2.RedundancyMonitor监控线程
hadoop3.2中的BlockManager$RedundancyMonitor(即hadoop2版本中的ReplicationMonitor)是随NameNode启动的后台线程。
| "RedundancyMonitor" #46 daemon prio=5 os_prio=0 tid=0x00007fbf2dba2800 nid=0x8e00 waiting on condition [0x00007fbeb9481000]
java.lang.Thread.State: TIMED_WAITING (sleeping)
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager$RedundancyMonitor.run(BlockManager.java:4743)
at java.lang.Thread.run(Thread.java:745)
|
| // BlockManager$RedundancyMonitor
private class RedundancyMonitor implements Runnable {
@Override
public void run() {
while (namesystem.isRunning()) {
try {
// Process recovery work only when active NN is out of safe mode.
if (isPopulatingReplQueues()) {
computeDatanodeWork(); //计算无效块的入口
processPendingReconstructions();
rescanPostponedMisreplicatedBlocks();
}
TimeUnit.MILLISECONDS.sleep(redundancyRecheckIntervalMs);
}
...
}
|
RedundancyMonitor线程周期性地进行块处理。其中无效块处理是在computeDatanodeWork方法中进行。
线程间隔时间是redundancyRecheckIntervalMs,其取值默认为3s:
| DFS_NAMENODE_REDUNDANCY_INTERVAL_SECONDS_KEY = "dfs.namenode.redundancy.interval.seconds";
DFS_NAMENODE_REDUNDANCY_INTERVAL_SECONDS_DEFAULT = 3;
|
| int computeDatanodeWork() {
// Blocks should not be replicated or removed if in safe mode.
// It's OK to check safe mode here w/o holding lock, in the worst
// case extra replications will be scheduled, and these will get
// fixed up later.
if (namesystem.isInSafeMode()) {
return 0;
}
final int numlive = heartbeatManager.getLiveDatanodeCount();
final int blocksToProcess = numlive
* this.blocksReplWorkMultiplier;
//从所有存活的DN中选择32%的节点进行处理
final int nodesToProcess = (int) Math.ceil(numlive
* this.blocksInvalidateWorkPct); //系数默认是32%
int workFound = this.computeBlockReconstructionWork(blocksToProcess);
// Update counters
namesystem.writeLock();
try {
//writeLock用来更新各种block的数量
this.updateState();
this.scheduledReplicationBlocksCount = workFound;
} finally {
namesystem.writeUnlock();
}
//从选中的32%的节点中进行无效块处理
workFound += this.computeInvalidateWork(nodesToProcess);
return workFound;
}
|
| int computeInvalidateWork(int nodesToProcess) {
final List nodes = invalidateBlocks.getDatanodes();
Collections.shuffle(nodes);
//从32%集群dn数和总的无效块所在的dn数中取小者
nodesToProcess = Math.min(nodes.size(), nodesToProcess);
int blockCnt = 0;
for (DatanodeInfo dnInfo : nodes) {
//处理每一个datanode
int blocks = invalidateWorkForOneNode(dnInfo);
if (blocks > 0) {
blockCnt += blocks;
if (--nodesToProcess == 0) {
break;
}
}
}
return blockCnt;
}
|
处理每一个dn的无效块:
| private int invalidateWorkForOneNode(DatanodeInfo dn) {
final List toInvalidate;
namesystem.writeLock();
try {
//...
try {
DatanodeDescriptor dnDescriptor = datanodeManager.getDatanode(dn);
//...
toInvalidate = invalidateBlocks.invalidateWork(dnDescriptor);
if (toInvalidate == null) {
return 0;
}
} catch(UnregisteredNodeException une) {
return 0;
}
} finally {
namesystem.writeUnlock();
}
return toInvalidate.size();
}
|
invalidateWorkForOneNode方法从BlockManager.invalidateBlocks中最多选择该dn的1000个(默认配置)数据块添加到具体的DataNodeDescriptor.invalidateBlocks(LightWeightHashSet结构)中,方法如下:
| //InvalidateBlocks#invalidateWork
synchronized List invalidateWork(final DatanodeDescriptor dn) {
final long delay = getInvalidationDelay();
if (delay > 0) {
BlockManager.LOG
.debug("Block deletion is delayed during NameNode startup. "
+ "The deletion will start after {} ms.", delay);
return null;
}
//默认值是1000
int remainingLimit = blockInvalidateLimit;
final List toInvalidate = new ArrayList<>();
//从无效块集合中返回限制数量的无效块
if (nodeToBlocks.get(dn) != null) {
remainingLimit = getBlocksToInvalidateByLimit(nodeToBlocks.get(dn),
toInvalidate, numBlocks, remainingLimit);
}
//如果副本块处理完了还不到1000个,这时候再处理EC块(副本块 + EC块 <= 1000)
if ((remainingLimit > 0) && (nodeToECBlocks.get(dn) != null)) {
getBlocksToInvalidateByLimit(nodeToECBlocks.get(dn),
toInvalidate, numECBlocks, remainingLimit);
}
if (toInvalidate.size() > 0) {
if (getBlockSetsSize(dn) == 0) {
remove(dn);
}
//把blocksMap.invalidateBlocks选出限制个数的无效块添加到DatanodeDescriptor.invalidateBlocks中
dn.addBlocksToBeInvalidated(toInvalidate);
}
return toInvalidate;
}
//InvalidateBlocks#getBlocksToInvalidateByLimit
private int getBlocksToInvalidateByLimit(LightWeightHashSet blockSet,
List toInvalidate, LongAdder statsAdder, int limit) {
assert blockSet != null;
int remainingLimit = limit;
//获得限制个数的无效块
List polledBlocks = blockSet.pollN(limit);
remainingLimit -= polledBlocks.size();
toInvalidate.addAll(polledBlocks);
statsAdder.add(polledBlocks.size() * -1);
return remainingLimit;
}
|
上述blockInvalidateLimit的取 (20* 心跳值) = 60与所配置的1000二者中的最大值,即1000,从无效块集合中返回1000个无效块。
| DFS_BLOCK_INVALIDATE_LIMIT_KEY = "dfs.block.invalidate.limit";
DFS_BLOCK_INVALIDATE_LIMIT_DEFAULT = 1000;
|
BlockManager$RedundancyMonitor流程如下:
3.DataNode心跳及IBR
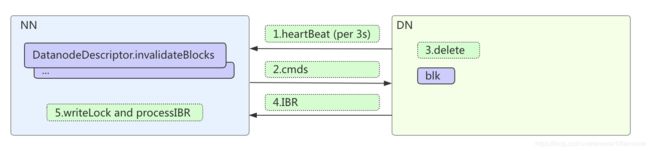
BPServiceActor.offerService()方法是每个BlockPool汇报心跳的入口。
| private void offerService() throws Exception {
// Now loop for a long time....
//
while (shouldRun()) {
try {
// 两大功能:发送心跳和块汇报
// Every so often, send heartbeat or block-report
//
// 心跳间隔3s 用当前时间与上次记录的下次心跳时间比较,到心跳时间了则开始处理
final boolean sendHeartbeat = scheduler.isHeartbeatDue(startTime);
HeartbeatResponse resp = null;
if (sendHeartbeat) {
// 所有的心跳信息包含以下4种:
// All heartbeat messages include following info:
// -- Datanode name
// -- data transfer port
// -- Total capacity
// -- Bytes remaining
//
boolean requestBlockReportLease = (fullBlockReportLeaseId == 0) &&
scheduler.isBlockReportDue(startTime);
if (!dn.areHeartbeatsDisabledForTests()) {
// 发送心跳,并将NN的返回结果放在resp中
resp = sendHeartBeat(requestBlockReportLease);
assert resp != null;
if (resp.getFullBlockReportLeaseId() != 0) {
// 关于Full Block Report,忽略
}
dn.getMetrics().addHeartbeat(scheduler.monotonicNow() - startTime);
// 关于HA,忽略
// ...
long startProcessCommands = monotonicNow();
// 处理NN返回的命令,如果处理失败则直接返回,不进行下一步的块汇报(增量块汇报、缓存汇报等)操作
if (!processCommand(resp.getCommands()))
continue;
}
}
if (!dn.areIBRDisabledForTests() &&
(ibrManager.sendImmediately()|| sendHeartbeat)) {
// 进行增量块汇报(在hadoop2.7中是reportReceivedDeletedBlocks方法)
ibrManager.sendIBRs(bpNamenode, bpRegistration,
bpos.getBlockPoolId());
}
// 其他处理
// There is no work to do; sleep until hearbeat timer elapses,
// or work arrives, and then iterate again.
ibrManager.waitTillNextIBR(scheduler.getHeartbeatWaitTime());
} catch(RemoteException re) {
// ...
} finally {
DataNodeFaultInjector.get().endOfferService();
}
processQueueMessages();
} // while (shouldRun())
}
|
上述增量快汇报(IBR)ibrManager.sendIBRs 直接调用 namenode.blockReceivedAndDeleted方法。具体在后文分析。
dn处理命令方法如下:
| boolean processCommand(DatanodeCommand[] cmds) {
if (cmds != null) {
for (DatanodeCommand cmd : cmds) {
try {
// 循环处理每一条命令
if (bpos.processCommandFromActor(cmd, this) == false) {
return false;
}
} catch (IOException ioe) {
LOG.warn("Error processing datanode Command", ioe);
}
}
}
return true;
}
//processCommandFromActor调用processCommandFromActive
private boolean processCommandFromActive(DatanodeCommand cmd,
BPServiceActor actor) throws IOException {
switch(cmd.getAction()) {
//这里分各种命令进行处理,如删除无效块对应的是DNA_INVALIDATE
case DatanodeProtocol.DNA_INVALIDATE:
//
// Some local block(s) are obsolete and can be
// safely garbage-collected.
//
Block toDelete[] = bcmd.getBlocks();
try {
//这里调用FsDatasetImpl.invalidate删除
// using global fsdataset
dn.getFSDataset().invalidate(bcmd.getBlockPoolId(), toDelete);
} catch(IOException e) {
// Exceptions caught here are not expected to be disk-related.
throw e;
}
dn.metrics.incrBlocksRemoved(toDelete.length);
break;
//...
}
|
FsDatasetImpl.invalidate中删除块完毕后,调用BPOfferService.notifyNamenodeDeletedBlock通知NN删除完毕,其方法栈如下:
| BPOfferService.notifyNamenodeDeletedBlock(ExtendedBlock, String) (org.apache.hadoop.hdfs.server.datanode)
DataNode.notifyNamenodeDeletedBlock(ExtendedBlock, String) (org.apache.hadoop.hdfs.server.datanode)
BlockSender.BlockSender(ExtendedBlock, long, long, boolean, boolean, boolean, DataNode, ...) (org.apache.hadoop.hdfs.server.datanode)
FsDatasetImpl.invalidate(String, ReplicaInfo) (org.apache.hadoop.hdfs.server.datanode.fsdataset.impl)
|
这里通知nn的步骤非常重要,代码如下:
| synchronized void notifyNamenodeBlock(ReceivedDeletedBlockInfo rdbi,
DatanodeStorage storage, boolean isOnTransientStorage) {
addRDBI(rdbi, storage);
final BlockStatus status = rdbi.getStatus();
if (status == BlockStatus.RECEIVING_BLOCK) {
// the report will be sent out in the next heartbeat.
readyToSend = true;
} else if (status == BlockStatus.RECEIVED_BLOCK) {
// the report is sent right away.
triggerIBR(isOnTransientStorage);
}
}
|
主要根据块的不同状态来做不同的处理,块的状态有以下3种:
| public enum BlockStatus {
RECEIVING_BLOCK(1), //正在被接收(写)的块
RECEIVED_BLOCK(2), //接收完毕(已被写完)的块
DELETED_BLOCK(3); //刚刚被删除的块
}
|
addRDBI方法是将增量块信息被加入到IBR Manager的pending IBR集合内,用于增量块汇报。对于已经写完的块,会立即触发增量块汇报;删除和正在接受的块则等待下次心跳时汇报。
NN端处理IBR将调用processIncrementalBlockReport,如下:
| //NN处理增量块汇报,添加写锁。
//FSNamesystem#blockReceivedAndDeleted
public void processIncrementalBlockReport(final DatanodeID nodeID,
final StorageReceivedDeletedBlocks srdb)
throws IOException {
//加锁
writeLock();
try {
//根据block的3中不同的状态进行处理
blockManager.processIncrementalBlockReport(nodeID, srdb);
} finally {
writeUnlock("processIncrementalBlockReport");
}
}
|
综上所述,删除文件时,dn删除块及nn的处理的整个流程如下:
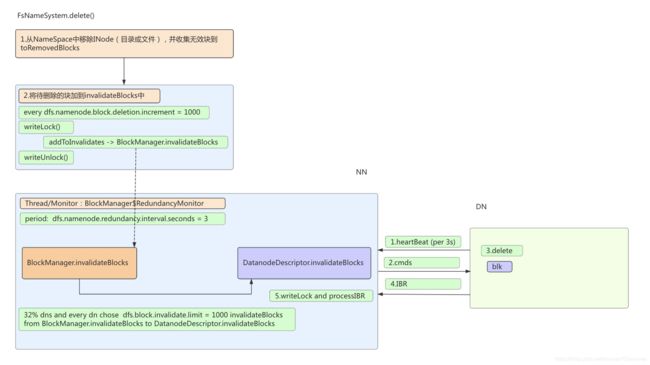
3.大量删除数据块的隐患及解决办法
- 当大量删除无效块时,BlockManager.invalidateBlocks集合变大,将会有更多的dn在进行心跳时收到删除块的命令。
- dn删除完块后就会进行对应的增量块汇报(IBR)。每一个dn的一次IBR就会申请namespace一个全局锁,直至nn处理完该dn的所有block才释放锁。
- 当一次锁持有时间过长时,将会影响到其他文件的块的写操作。如一个RECEIVED_BLOCK在触发IBR时将会等待,不能及时更新该文件INodeFile中的文件状态。
- 客户端在进行指定次数的重试complete文件时,检查INodeFile中的文件状态没有COMPLETE,抛出不能关闭文件异常。(客户端complete发送RPC到NameNode的代码简单,不再粘贴)
解决办法:
- 加大客户端complete文件重试次数,这样可以给NN更多的时间处理IBR,如调到10:dfs.client.block.write.locateFollowingBlock.retries
-
增加RedundancyMonitor线程周期扫描间隔,减少无效块的增长速度,默认3s:dfs.namenode.redundancy.interval.seconds
- 减少NN一次给DN下达命令时block集合大小(默认1000),可以减少NN处理一次IBR时的持锁时间:dfs.block.invalidate.limit
另外社区关于的dn删除block改异步方法(issue HDFS-14997),暂未发现有助于本问题的改善。