MySQL从入门到放弃(二)
1.MySQL数据查询
(1)基本查询语句SELECT
SELECT {*|<字段名>} [
FROM <表1>,<表2>...
[WHERE <表达式>
[GROUP BY ]
[HAVING [{}...]]
[ORDER BY ]
[LIMIT[,]]
]
SELECT {字段1,字段2,...字段n}
FROM [表或视图]
WHERE[查询条件];其中,各条子句的含如下:
{*|<字段名>}包含星号通配符选字段列表,表示查询的字段,其中字段列至少包含一个字段名称,如果要查询多个字段,多个字段之间用到逗号隔开,最后一个字段后不要加逗号。
FROM <表1>,<表2>...表1和表2表示查询数据的来源,可以是单个或多个。
WHERE子句是可选项,如果选择该项,将限定查询行必须满足的查询条件。
GROUP BY<字段>,该子句告诉MySQL如果显示查询出来的数据,并按照指定的字段分组。
[ORDER BY
[LIMIT[
创建一张名为student的学生表,表结构如下:
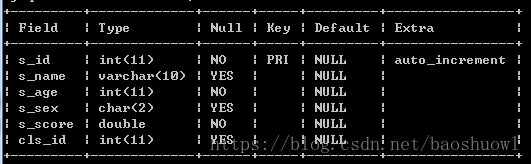
CREATE TABLE student(
s_id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
s_name VARCHAR(10) NOT NULL,
s_age INT NOT NULL ,
s_sex CHAR(2),
s_score DOUBLE NOT NULL,
cls_id INT);随便插入10条数据
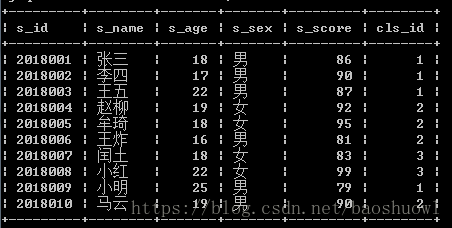
INSERT INTO student(s_id,s_name,s_age,s_sex,s_score,cls_id)VALUES(2018001,'张三',18,'男',86,001),
(2018002,'李四',17,'男',90,001),
(2018003,'王五',22,'男',87,001),
(2018004,'赵柳',19,'女',92,002),
(2018005,'牟琦',18,'女',95,002),
(2018006,'王炸',16,'男',81,002),
(2018007,'闰土',18,'女',83,003),
(2018008,'小红',22,'女',99,003),
(2018009,'小明',25,'男',79,001),
(2018010,'马云',19,'男',90,002);(2)单表查询
查询所有字段
可以使用最简单的形式也就是通配符“*”来查询所有字段
SELECT * FROM 表名;
查询指定字段
查询单个字段
SELECT 列名(字段名) FROM 表名;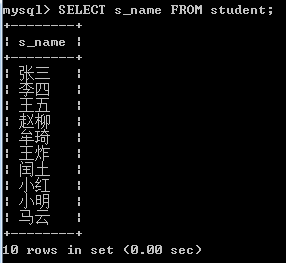
查询多个字段
SELECT 字段名1,字段名2,...,字段名n FROM 表名;
条件查询,查询指定记录
数据库中包含大量的数据,根据特殊要求,可能只需要查询表中的指定数据,即对数据进行过滤,通过WHERE子句可以对数据进行过滤,语法如下
SELECT 字段名1,字段名2,...字段名n
FROM 表名
WHERE 查询条件
查询学号为2018009的学生信息
SELECT * FROM student WHERE s_id = 2018009;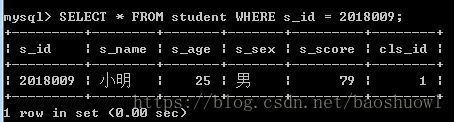
查询成绩小于90分的学生信息
SELECT * FROM student WHERE s_score < 90;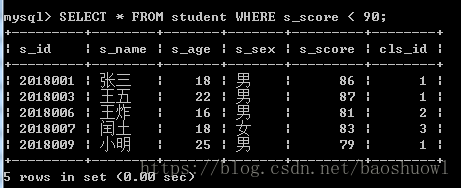
包含查询,带IN关键字的查询
查询学生年龄为17,18,19的学生信息
SELECT * FROM student WHERE s_age IN(17,18,19);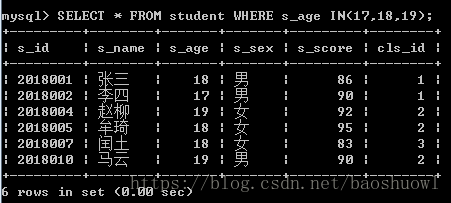
查询学号不是2018002,2018004,2018008的学生信息
SELECT * FROM student WHERE s_id NOT IN (2018002,2018004,2018008);
范围查询,带BETWEEN...AND...关键字的查询
查询成绩在80分~90分的学生信息
SELECT * FROM student WHERE s_score BETWEEN 80 AND 90;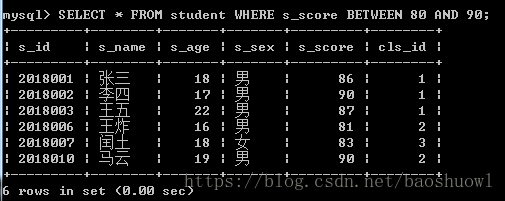
查询年龄在17岁~20岁的学生姓名,性别
SELECT s_name,s_sex FROM student WHERE s_age BETWEEN 17 AND 20;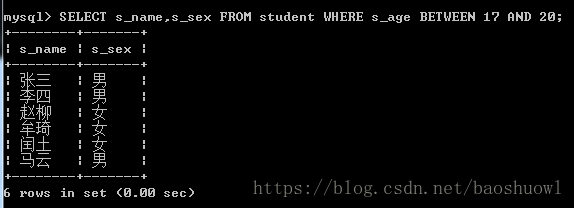
模糊查询,带LIKE的字符匹配查询
百分号“%”通配符,匹配任意长度的字符,甚至包括零字符
查询以王开头的学生姓名
SELECT * FROM student WHERE s_name LIKE '王%';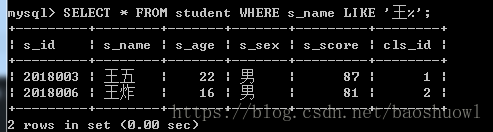
查询以红结尾的学生姓名
SELECT * FROM student WHERE s_name LIKE '%红';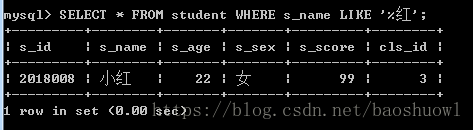
查询包含某字的学生姓名
SELECT * FROM student WHERE s_name LIKE '%m某字%';下划线通配符“_”,一次只能匹配任意一个字符
查询以马字开头的两个字的姓名
SELECT * FROM student WHERE s_name LIKE '王_';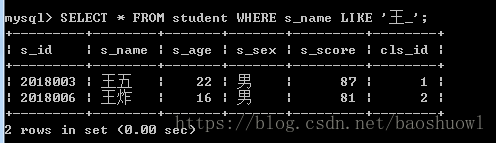
查询空值IS NULL\IS NOT NULL
查询某个字段为空的数据,现在现插入一条数据
INSERT INTO student(s_id,s_name,s_age,s_sex,s_score)VALUES(2018011,'奥八马',35,'男',59);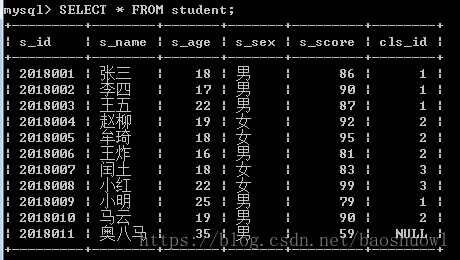
查询cls_id字段数据为空的记录
SELECT * FROM student WHERE cls_id IS NULL;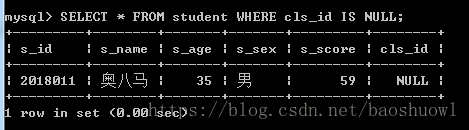
有了IS NULL就自然会有IS NOT NULL
查询cls_id字段数据为不空的记录
SELECT * FROM student WHERE cls_id IS NOT NULL;
多条件查询指定记录AND
查询年龄为18岁,并且成绩在80分~90分的学生
SELECT * FROM student WHERE s_age=18 AND s_score BETWEEN 80 AND 90;
查询年龄为18岁,并且性别为女,并且成绩大于80分的学生
SELECT * FROM student WHERE s_age=18 AND s_sex='女' AND s_score>80;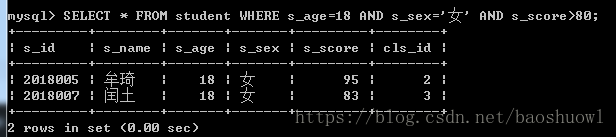
多条件查询指定记录OR
查询年龄小于18岁,或者成绩小于80分的学生
SELECT * FROM student WHERE s_age<18 OR s_score<80;
查询年龄在15岁~20,或者成绩大于90分的学生,或者班级为2的学生
SELECT * FROM student WHERE s_age BETWEEN 15 AND 20 OR s_score>90 OR cls_id=2;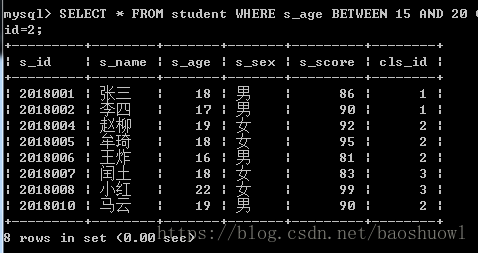
查询结果不重复
查询下班级id

发现有很多重复的cls_id值,有时,出于对数据分析的要求,需要消除重复的记录值,就需要使用到DISTINCT关键字,语法如下
SELECT DISTINCT 字段名 FROM 表名;删除cls_id字段中重复的记录值
SELECT DISTINCT cls_id FROM student;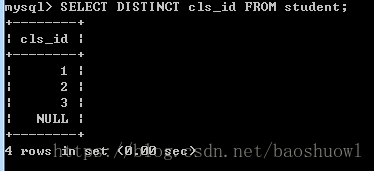
对查询结果进行排序
单列排序,按照成绩进行排序,默认升序ASC
SELECT * FROM student ORDER BY s_score;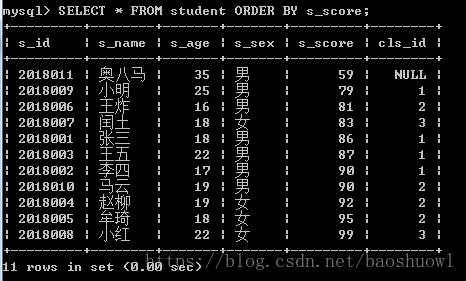
单列排序,按照成绩进行排序,降序DESC
SELECT * FROM student ORDER BY s_score DESC;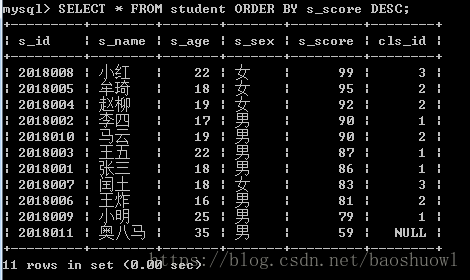
多列排序,按照成绩进行升序排序,名字降序
SELECT * FROM student ORDER BY s_score,s_name DESC;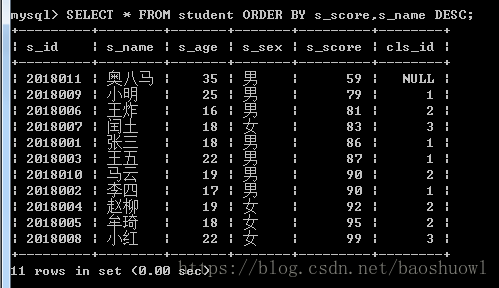
分组查询
分组查询是对数据按照某个字段或多个字段进行分组,MySQL中使用GROUP BY关键字对数据进行分分组,语法如下
[GROUP BY 字段]{HAVING<条件表达式>}GROUP BY关键字通常和集合函数一起使用,例如MAX(),MIN(),COUNT(),SUM(),AVG()。例如,现在要返回每个班级的学生,就要用到COUNT()函数
根据班级序号cls_id字段进行分组,显示每个班级人数
SELECT cls_id,COUNT(*) FROM student GROUP BY cls_id;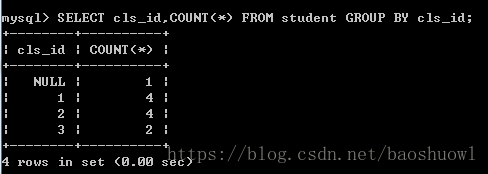
可以从上表看出,班级3中有2个学生,班级2和班级1中分别有4个学生,班级NULL中有一个学生。
根据班级序号cls_id字段进行分组,显示每个班级的学生
SELECT cls_id,GROUP_CONCAT(s_name) FROM student GROUP BY cls_id;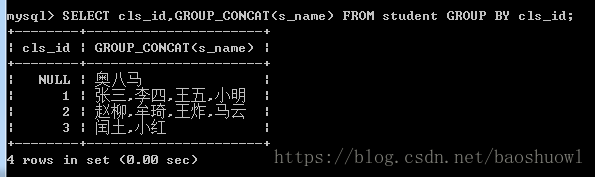
由结果可以看出,GROUP_CONCAT()函数将每个分组中的名字都显示出来了。
使用HAVING过滤分组,将班级人数大于2个人的班级显示
SELECT cls_id,GROUP_CONCAT(s_name) FROM student GROUP BY cls_id HAVING COUNT(s_name)>2;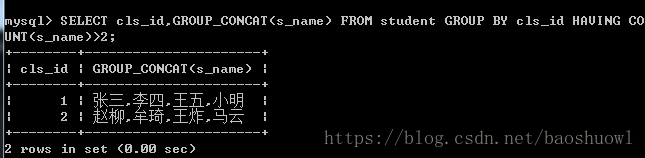
在GROUP BY子句中使用WITH ROLLUP
使用WITH ROLLUP关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的综合,即统计记录数量。
SELECT cls_id,COUNT(*) FROM student GROUP BY cls_id WITH ROLLUP;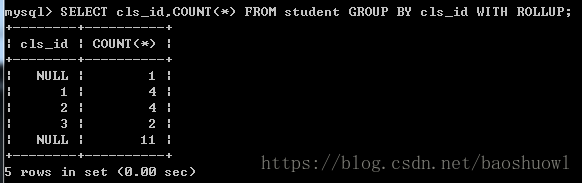
做字段分组,根据cls_id分组后再根据s_sorce分组
SELECT * FROM student GROUP BY cls_id,s_score;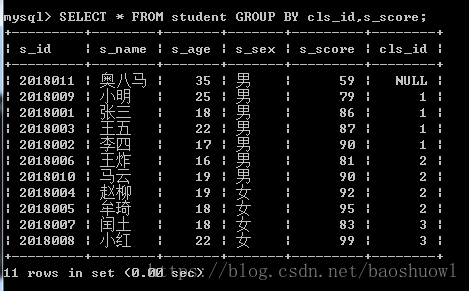
使用LIMIT限制查询结果的数量
显示stuent表中的前5条数据
SELECT * FROM student LIMIT 5;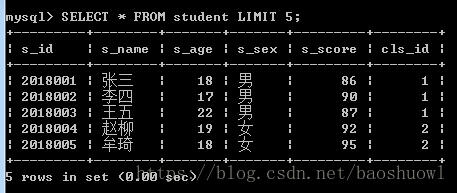
使用集合函数查询
COUNT()函数
COUNT()函数统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数。
COUNT(*)计算表中总的行数,不管某列有数值或为空
SELECT COUNT(*) FROM student;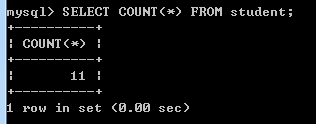
COUNT(字段名)计算指定列下的总行数,计算时将忽略空值的行
SELECT COUNT(cls_id) FROM student;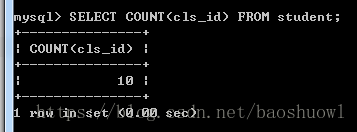
可以看到第十一条记录没有被计入总数
SUM()函数
SUM()是一个求总和的函数,返回指定列的总和
计算所有学生的年龄总和
SELECT SUM(s_age) as ages FROM student;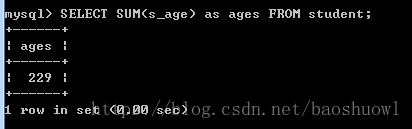
通过GROUP BY和SUM()计算出分组后每组的成绩总和
SELECT cls_id,SUM(s_score) FROM student GROUP BY cls_id;
AVG()函数
AGG()函数通过计算返回的行数和每一行的数据的和,求得指定列数据的平均值
通过GROUP BY和AVG()计算出分组后每组的成绩的平均值
SELECT cls_id,AVG(s_score) FROM student GROUP BY cls_id;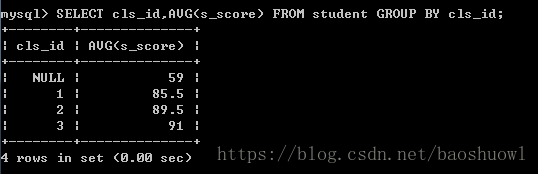
MAX()函数
MAX()函数返回指定列中的最大值
获得成绩最高的学生信息
SELECT *,MAX(s_score) FROM student;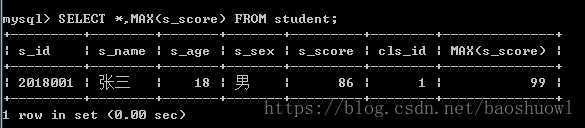
通过GROUP BY 和 MAX()获得每班成绩最高的学生
SELECT s_name,MAX(s_score) FROM student GROUP BY cls_id;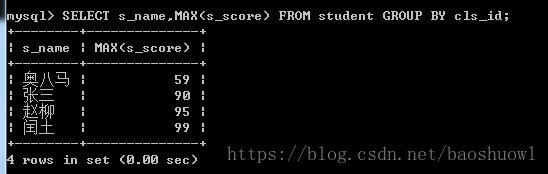
MIN()函数
MIN()返回查询列中的最小值
获得成绩最差的学生信息
SELECT *,MIN(s_score) FROM student;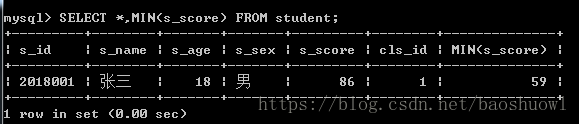
(3)多表联查
内连接查询(INNER JOIN),使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中连接条件相匹配的数据行,组合成新的记录,也就是说,在内连接查询中,至于满足条件的记录才能在结果关系中。
在这里再创建一个teacher表,两个表用cls_id关联。

CREATE TABLE teacher(
class_id INT PRIMARY KEY NOT NULL AUTO_INCREMENT,
t_name VARCHAR(10) NOT NULL,
t_age INT NOT NULL,
t_sex CHAR(2)
);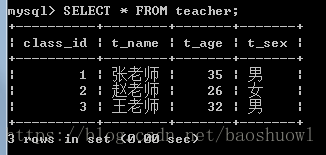
INSERT INTO teacher(class_id,t_name,t_age,t_sex)VALUES(1,'张老师',35,'男'),
(2,'赵老师',26,'女'),
(3,'王老师',32,'男');让teacher表做主表,让student做从表,student中的cls_id参照teacher中的class_id做外键,现在添加外键
ALTER TABLE student ADD CONSTRAINT kf_classId FOREIGN KEY (cls_id) REFERENCES teacher(class_id);通过多表联查,获取两张表的所有字段数据
SELECT class_id,t_name,t_age,t_sex,s_id,s_name,s_age,s_sex,s_score
FROM teacher,student
WHERE teacher.class_id=student.cls_id;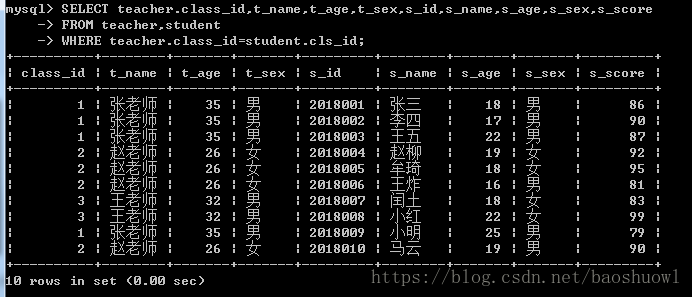
内连接查询
SELECT class_id,t_name,t_age,t_sex,s_id,s_name,s_age,s_sex,s_score
FROM teacher INNER JOIN student
ON teacher.class_id=student.cls_id;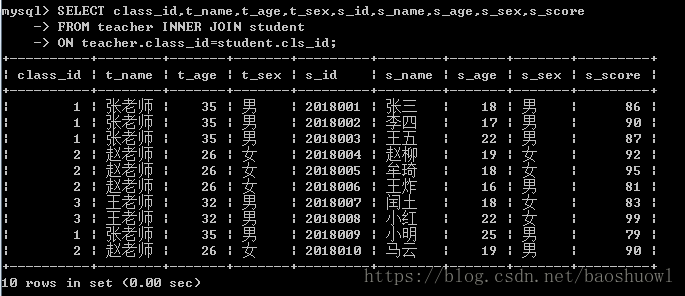
自连接查询
如果在一个连接查询中,设计到的两个表都是同一个表,这种查询称为自连接查询,自连接查询是一种特殊的内连接,它是指相互连接的表在物理上为同一张表,但是可以在逻辑上分为两张表。
SELECT s1.s_name,s1.cls_id
FROM student AS s1,student AS s2
WHERE s1.s_name=s2.s_name AND s1.cls_id=2;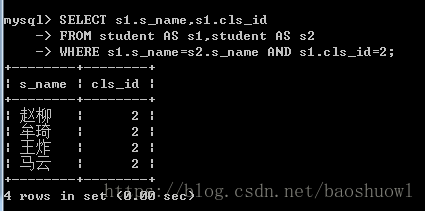
外连接查询
使用LEFT JOIN
SELECT * FROM teacher LEFT JOIN student ON teacher.t_age=student.s_age;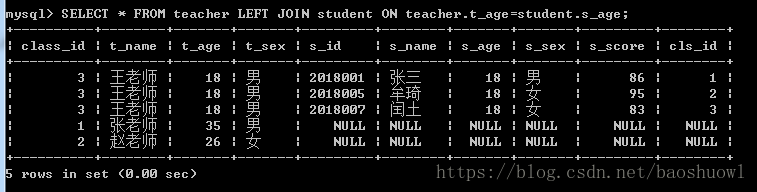
SELECT * FROM student LEFT JOIN teacher ON teacher.t_age=student.s_age;
使用RIGHT JOIN
SELECT * FROM teacher RIGHT JOIN student ON teacher.t_age=student.s_age;
SELECT * FROM student RIGHT JOIN teacher ON teacher.t_age=student.s_age;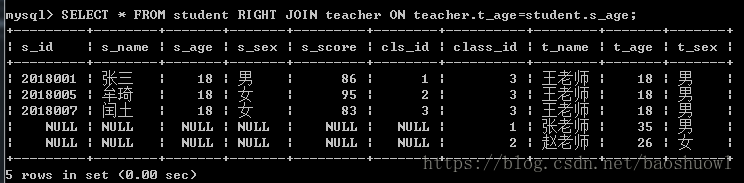
子查询
带有ANY、SOME关键字的子查询
创建两个表
CREATE TABLE t1(num1 INT NOT NULL);
CREATE TABLE t2(num2 INT NOT NULL);分别向表中插入数据
INSERT INTO t1 VALUES(1),(5),(13),(27);
INSERT INTO t2 VALUES(6),(14),(11),(20);ANY关键字接在一个比较操作符后面,表示若与子查询返回的任何值比较为TRUE,则返回TRUE。
SELECT num1 FROM t1 WHERE num1>ANY (SELECT num2 FROM t2);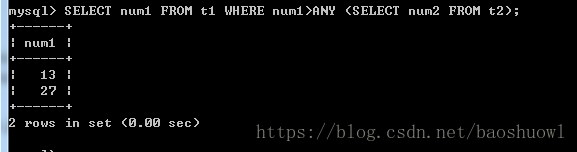
带有ALL关键字的子查询
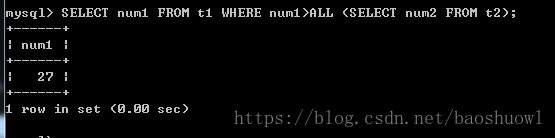
ALL关键字与ANY和SOME不同,使用ALL时需要同时满足所有内层查询的条件。SELECT num1 FROM t1 WHERE num1>ALL (SELECT num2 FROM t2);
带有EXISTS关键字的子查询
EXISTS关键字后面的参数是一个任意的子查询,系统对子查询进行运算以判断它是否返回行,如果至少返回一行,那么EXISTS的结果为TRUE,此时外层查询语句将进行查询;如果子查询没有返回任何行,那么EXISTS返回的结果为FALSE,此时外层语句将不进行查询。
第一种情况,EXISTS返回TRUE
SELECT * FROM student
WHERE EXISTS
(SELECT s_name FROM student WHERE s_name='张三');
第二种情况,EXISTS返回FALSE,外层查询不进行
SELECT * FROM student
WHERE EXISTS
(SELECT s_age FROM student WHERE s_age=100);
带有IN关键字的子查询
IN关键字进行子查询时,内层查询语句仅仅返回一个数据列,这个数据列李的值将提供给外层查询语句进行比较数据