python web爬虫_5个最佳Python Web爬虫库
python web爬虫
Well, there are tons of libraries available in python but these 5 are most used by people. You will know why most of the users are using these libraries.
好吧,有大量可用的python库,但是这5个库是人们最常使用的库。 您将知道为什么大多数用户都在使用这些库。
The web is a huge data source and there are many ways to get data from the web. One of the most common ways is Scraping. There are different languages and in each language, there are multiple libraries that can be used to Scrap data on the web. This post is especially for python and its 5 best web scraping libraries.
网络是一个巨大的数据源,有很多方法可以从网络获取数据。 刮擦是最常见的方法之一。 有不同的语言,每种语言都有多个可用于在Web上废弃数据的库。 这篇文章特别适用于python及其5个最佳的Web抓取库。
刮擦的好处 (Benefits of Scraping)
Well, the web is a huge database for grabbing data. Nowadays, data is more costly then gold and the web is open for all to grab data. Here Scraping comes into play. With different scrappers, you can Scrape data from the Web. Many websites are running on Web Scraping.
嗯,网络是用于获取数据的庞大数据库。 如今,数据比黄金更昂贵,并且网络开放给所有人使用。 在这里,爬网发挥了作用。 使用不同的剪贴器,您可以从Web刮取数据。 许多网站都在Web Scraping上运行。
One of the most useful websites I found which uses Scraping to get data is Price Trackers. This website Scrape the data from Amazon, Flipkart, Myntra, AJIO, ShoppersStop, etc and store them in a database. Later they use those data to show a price graph.
我发现使用Scraping获取数据的最有用的网站之一是Price Trackers 。 该网站从Amazon,Flipkart,Myntra,AJIO,ShoppersStop等中收集数据,并将其存储在数据库中。 后来他们使用这些数据显示价格图。
5个最佳Python Web爬虫库 (5 Best Python Web Scraping Libraries)
Requests
要求
Beautiful Soup 4 (BS4)
美丽的汤4(BS4)
lxml
xml文件
Selenium
Selenium
Scrapy
cra草
1)要求 (1) Requests)
It is one of the most fundamental libraries for web scraping. Some people use URLLIB 2 or URLLIB3 instead of Requests.
它是Web抓取的最基本的库之一。 有些人使用URLLIB 2或URLLIB3代替请求。
Functions of Requests in Web Scraping:
Web爬网中请求的功能:
It is used to get raw HTML data. On passing Web Page as a parameter you will get raw HTML of that page. Later this raw HTML can be used to get desired data from it.
它用于获取原始HTML数据。 将网页作为参数传递时,您将获得该页面的原始HTML。 以后,可以使用此原始HTML从中获取所需的数据。
It has many useful methods and attributes that could be useful in Scraping.
它具有许多有用的方法和属性,这些属性可能在Scraping中有用。

This above example of Requests.
上面的请求示例。
Install: You can install this package from PyPI.
安装:您可以从PyPI安装此软件包。
pip install requests
Run this command in your command prompt or Terminal.
在命令提示符或终端中运行此命令。
Here is the Git Repository of this library. You can fork this to change according to your use.
这是该库的Git存储库。 您可以根据自己的需要进行分叉以进行更改。
2)美丽的汤4 (2) Beautifulsoup4)
One of the most famous python library for fetching data from HTML and XML. This library is for basic and simple use. You can do almost all the basic scraping things with beautiful-soup.
从HTML和XML提取数据的最著名的python库之一。 该库供基本和简单使用。 您可以用漂亮的汤做几乎所有基本的刮东西。
Main Functions of BS4
BS4的主要功能
It is mainly used to fetch data from HTML or XML. Once you have raw HTML by using Requests library you can use this one to fetch useful data.
它主要用于从HTML或XML获取数据。 通过使用请求库获得原始HTML之后,您可以使用此库来获取有用的数据。
The above screenshot was taken from bs4 official documentation to show you its uses.
上面的屏幕截图来自bs4官方文档,以向您展示其用法。
Install: you can install it via PyPI
安装 :您可以通过PyPI安装它
pip install beautifulsoup4
Run the command in your terminal or cmd prompt.
在终端或cmd提示符下运行命令。
Here is the official Documentation of BS4
这是BS4的官方文档
3)LXML (3) LXML)
This is one of the best parsers for HTML and XML. It is used to ease the handling of XML and HTML files. It is widely used for its simplicity and extremely fast response. This library is very useful in web Scraping as this can easily parse the large HTML or XML files.
这是HTML和XML的最佳解析器之一。 它用于简化XML和HTML文件的处理。 它因其简单性和极快的响应而被广泛使用。 该库在Web Scraping中非常有用,因为它可以轻松解析大型HTML或XML文件。
Main Function of LXML
LXML的主要功能
Lxml is used for parsing HTML or XML Files. It can parse even large HTML or XML files easily and fastly. That is why people use this parse while Scraping. It is required to parse the HTML or XML files. Some people use their own handwritten parser for parsing. But this parse is mostly used because of its speed, good documentation, the capability of parsing large files, etc.
Lxml用于解析HTML或XML文件。 它可以轻松快速地解析大型HTML或XML文件。 这就是为什么人们在Scraping时使用此解析。 解析HTML或XML文件是必需的。 有些人使用自己的手写解析器进行解析。 但是,由于其速度快,文档完善,解析大文件的能力等原因,通常使用此解析。
Install:
安装 :
To install this via PyPI, run this command- pip install lxml
要通过PyPI安装,请运行以下命令-pip install lxml
For more information on installation, you can check the documentation
有关安装的更多信息,您可以查看文档
4)Selenium (4) Selenium)
Selenium acts as a web driver. This API provides a way to use WebDriver like Firefox, Ie, Chrome, Remote, etc. A program can do almost all the tasks that can be performed by a user on web browsers like form fillings, form clicking or button clicking, browser opening and a lot more. It is a very useful tool in Python for web Scraping.
Selenium充当Web驱动程序。 该API提供了一种使用WebDriver的方式,例如Firefox,IE,Chrome,远程等。程序可以执行用户可以在网络浏览器上执行的几乎所有任务,例如表单填写,表单单击或按钮单击,浏览器打开以及多很多。 这是Python中用于Web搜刮的非常有用的工具。
Main Function of Selenium:
Selenium的主要功能:
It acts as a WebDriver and can perform tasks like browser opening, form filling, button clicking, etc.
它充当WebDriver,可以执行诸如打开浏览器,填写表单,单击按钮等任务。
Here is a Firefox WebDriver which is used to get information from python.org.
这是一个Firefox WebDriver,用于从python.org获取信息。
The above example is taken from Selenium's official documentation. In the above image, there is a basic use of Selenium. You can read further about the above example here.
上面的示例摘自Selenium的官方文档 。 在上图中,Selenium的基本用法。 您可以在此处进一步阅读上述示例。
Install:
安装:
To install using PyPI, use this command- pip install selenium
要使用PyPI安装,请使用以下命令-pip install selenium
Here is the official Git Repo for Selenium. You can fork this Repo to change the package according to your need.
这是Selenium的官方Git回购 。 您可以分叉此Repo以根据需要更改软件包。
5)cra草 (5) Scrapy)
Scrapy is a web scraping framework. It is one of the most advanced scraping framework available in Python. This Scrapy provides bots that can scrape thousands of web pages at once. Here you have to create a web spider that will go from one page to another and provides you the data.
Scrapy是一个Web抓取框架。 它是Python中可用的最先进的抓取框架之一。 该Scrapy提供的机器人可以一次抓取数千个网页。 在这里,您必须创建一个网络爬虫,该爬虫将从一页到另一页并为您提供数据。
Main Function of Scrapy:
Scrapy的主要功能:
With this Framework, you can create Spider that will crawl on web pages and scrape desired data from the web.
使用此框架,您可以创建Spider,该Spider会在网页上抓取并从网上抓取所需的数据。
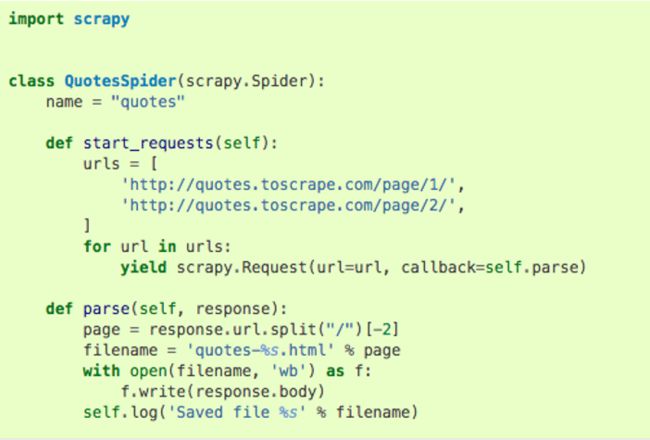
This is the basic code for creating a spider with Scrapy. There are tons of predefined class and methods and you just have to use them to create your Spider. It is easy to create a web Spider with this package. Rather it is quite difficult for a beginner to create a fully functional web scraper.
这是使用Scrapy创建蜘蛛的基本代码。 有很多预定义的类和方法,您只需要使用它们来创建Spider。 使用此程序包很容易创建一个Web Spider。 相反,对于初学者来说,创建功能齐全的刮板非常困难。
Install:
安装 :
To install using PyPI you can use this- pip install Scrapy
or
To Install Scrapy using conda, run this command- conda install -c conda-forge scrapy
要使用PyPI安装,您可以使用this-pip install Scrapy
要么
要使用conda安装Scrapy,请运行以下命令-conda install -c conda-forge scrapy
Here is the installation guide for Scrapy. Also, check the documentation for Scrapy.
这是Scrapy的安装指南 。 另外,请查看Scrapy的文档 。
翻译自: https://www.includehelp.com/python/5-best-python-web-scraping-libraries.aspx
python web爬虫