一、JML语言理论基础
JML 是用于对 Java 程序进行规格化设计的一种表示语言,为严格的程序设计提供了一套行之有效的方法。
我个人对于 JML 的几点看法:
- JML 的规格化设计相较于自然语言的描述,具有严密的逻辑,便于程序员理解需求,更好地实现功能;
- JML 能够帮助测试人员很好地构造测试数据,检查程序员是否很好地完成了相关代码的实现。
1. 注释结构
JML以javadoc注释的方式来表示规格,每行都以@起头。有两种注释方式,行注释和块注释。其中行注释的表示方式为//@annotation,块注释的方式为/* @ annotation @*/。
2. JML 表达式
2.1 原子表达式
| 表达式 | 描述 |
|---|---|
| \result | 表示一个非void类型的方法执行所获得的结果 |
| \old(expr) | 用来表示一个表达式expr在相应方法执行前的取值 |
| \not_assigned(x,y,...) | 用来表示括号中的变量是否在方法执行过程中被赋值 |
| \not_modified(x,y,...) | 与上面的\not_assigned表达式类似,该表达式限制括号中的变量在方法执行期间的取值未发生变化。 |
2.2 量化表达式
| 表达式 | 描述 |
|---|---|
| \forall | 全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束 |
| \exists | 存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束 |
| \sum | 返回给定范围内的表达式的和 |
| \product | 返回给定范围内的表达式的连乘结果 |
| \max | 返回给定范围内的表达式的最大值 |
| \min | 返回给定范围内的表达式的最小值 |
| \num_of | 返回指定变量中满足相应条件的取值个数 |
2.3 操作符
| 操作符 | 描述 |
|---|---|
| E1<:E2 | 子类型关系操作符 |
b_expr1<==>b_expr2或者b_expr1<=!=>b_expr2 |
等价关系操作符 |
b_expr1==>b_expr2或者b_expr2<==b_expr1 |
推理操作符 |
| \nothing指示一个空集,\everything指示一个全集 | 变量引用操作符 |
3. 方法规格
| 方法规格 | 描述 |
|---|---|
| 前置条件 requires | requires P;其中requires是JML关键词,表达的意思是“要求调用者确保P为真” |
| 后置条件 ensures | ensures P;其中ensures是JML关键词,表达的意思是“方法实现者确保方法执行返回结果一定满足谓词P的要求,即确保P为真” |
| 副作用范围限定 assignable modifiable | 副作用指方法在执行过程中会修改对象的属性数据或者类的静态成员数据,从而给后续方法的执行带来影响 |
| 异常处理 signals | signals (***Exception e) b_expr;意思是当b_expr为true时,方法会抛出括号中给出的相应异常e |
4. 类型规格
| 类型规格 | 描述 |
|---|---|
| 不变式invariant | 要求在所有可见状态下都必须满足的特性 |
| 状态变化约束constraint | 要求在状态变化下需要满足的条件 |
二、SMT Solver验证
static check
/Users/apple/Desktop/homework11 new/src/MyPerson.java:8: 警告: The prover cannot establish an assertion (NullField) in method MyPerson
private String name;
^
/Users/apple/Desktop/homework11 new/src/MyPerson.java:9: 警告: The prover cannot establish an assertion (NullField) in method MyPerson
private BigInteger character;
^
/Users/apple/Desktop/homework11 new/src/MyPerson.java:11: 警告: The prover cannot establish an assertion (NullField) in method MyPerson
private HashMap acquaintance;
^
/Users/apple/Desktop/openjml-0/openjml.jar(specs/java/util/Map.jml):184: 警告: The prover cannot establish an assertion (UndefinedCalledMethodPrecondition: /Users/apple/Desktop/openjml-0/openjml.jar(specs/org/jmlspecs/lang/map.jml):18: 注: ) in method addRelation
@ ensures \result == \old(modelMap).get(key);
^
...
50 个警告
关于MyPerson类的检查,一共触发了50个警告
syntax check
/Users/apple/Desktop/homework11 new/src/com/oocourse/spec3/main/Group.java:58: 错误: 不可比较的类型: int和INT#1
/*@ ensures \result == (people.length == 0? 0 :
^
其中, INT#1是交叉类型:
INT#1扩展Number,Comparable
/Users/apple/Desktop/homework11 new/src/com/oocourse/spec3/main/Group.java:63: 错误: 不可比较的类型: int和INT#1
/*@ ensures \result == (people.length == 0? 0 : ((\sum int i; 0 <= i && i < people.length;
^
其中, INT#1是交叉类型:
INT#1扩展Number,Comparable
2 个错误
关于Network的语法检查,出现了两个错误(原因是不支持三目运算符);关于Person的语法检查,则是通过
runtime assertion check
The operation symbol ++ for type java.lang.Object could not be resolved
org.jmlspecs.openjml.JmlInternalError: The operation symbol ++ for type java.lang.Object could not be resolved
关于MyNetwork的检查,触发了JmlInternalError,感觉是 JML 工具链还不完善导致的内部错误
三、JMLUnitNG使用
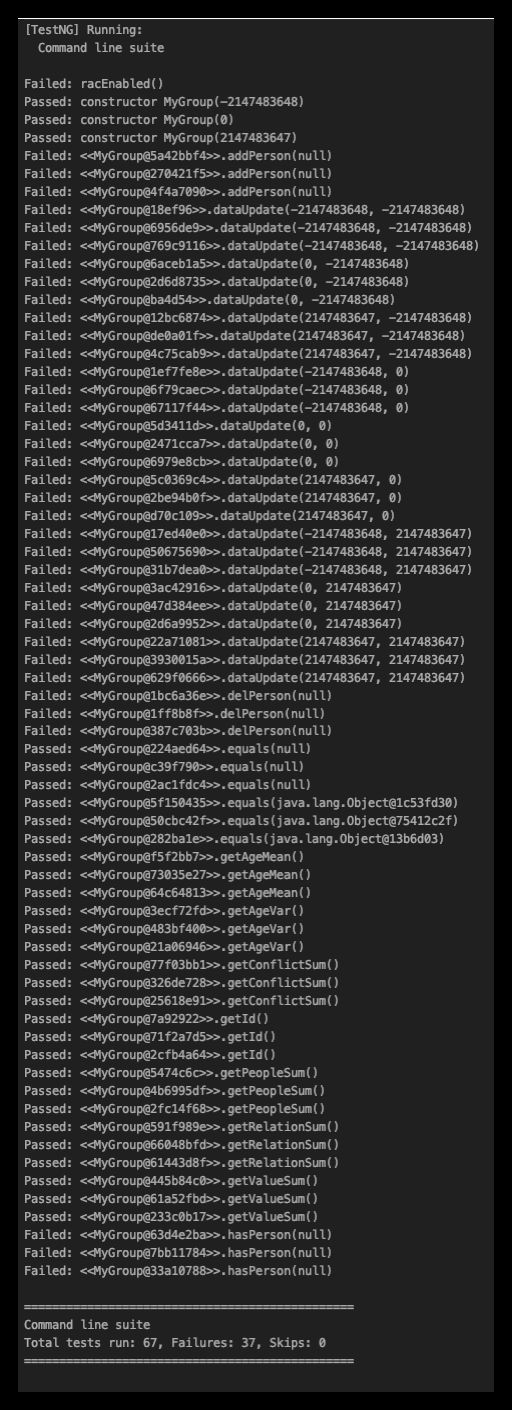
本人测试的时候仅留下了Person,Group,MyPerson,MyGroup四个类,效果图如下
测试分析
我们可以从测试数据看出,基于JMLUnitNG自动生成的测试数据仅对函数的边界条件进行了极端测试,并没有太大的参考意义。如果要实际测试的话,还是进行自己的JUnit单元测试,或者黑盒测试更具有效性。
四、作业分析
本单元三次作业,都是针对已有的 JML 规格实现相关的功能。在整体的架构方面,助教基本把工作做完了,我们只需要实现具体的功能,同时注意一些细节和性能方面的考量就可以了。
第九次作业
本次作业比较需要注意的是Network中的isCircle函数,这个在之后的几次作业也都将涉及,在本次作业中我采用bfs的方式实现,查询的复杂度O(V+E)。同时本次作业中,如果采用了bfs或者dfs的查询方式,需要注意在isCircle函数中对相同id的查询进行判断。
同时本次作业涉及到大量的id查询方面的工作,需要合适的存储方式来帮助管理,我采用的是HashMap,在添加新元素的时候复杂度是O(1),到了一定阈值的时候HashMap会从链表变成红黑树,复杂度变为O(logn),在查询的时候复杂度是O(1)-O(logn);相较于ArrayList的O(n)查询,会高效不少。
第十次作业
本次作业相较于上次,主要变化在于添加了Group类,同时测试数据指令数的上限为10w,所以更需要注重在性能方面的维护。
我主要进行了一下几点改变:
HashMap容量初始化
在HashMap底层中,它的默认容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
如果当前的HashMap的size超过了它的threshold,就需要扩容,为当前最大容量的两倍,这个是很消耗时间的,如果在初始化的时候指定一个合适的容量大小,能够帮助提升性能
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
// HashMap putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
if (++size > threshold)
resize();
...
}
- 在
MyGroup类中进行数据缓存
在每次添加新人,或者新关系的时候对相关缓存进行维护,之后查询的时候就不需要每次都重新对数据进行处理。
private int ageSum;
private int valueSum;
private int relationSum;
private BigInteger conflictSum;
第十一次作业
三次作业我仅在最后一次添加了工具类Pair辅助维护,其他时候都未对框架做出过改动。
在这次作业中,主要想谈一下几点:
- 关于
age的溢出问题
这次age的范围改为[0, 2000],在进行Group内部数据维护的时候可能会发生int的溢出,但是经过测试发现,只要最后的需求数据没有发生溢出,维护数据发生溢出实际是没有影响的(只进行了相关数据的构造测试,没有进行理论化验证)
isCircle和queryBlockSum
本次作业中,添加了更多关于isCircle函数的查询,所以我将isCircle改为了并查集(查询O(1))的查询方法,同时对连通块(queryBlockSum)进行维护,用以保证效率
queryMinPath
这个我采用的是堆优化 Dijkstra 算法,用优先队列PriorityQueue来维护堆,保证为小顶堆
queryStrongLink
我最初是采用暴力的dfs来实现,但是发现效率确实不尽人意,怕会存有隐患,之后改为了点连通分量的 tarjan 算法。
tarjan 算法的实现比较容易出错,这个最好要与暴力的解法进行对拍,同时构造几个特殊的图,在 debug 模式下看看运行流程符不符合期望。
Bug 分析
- 自测
在第十次作业中,最初没有采用缓存的方式进行数据维护,这个在互测中可能会被 hack;
在第十一次作业中,我的堆优化 Dijkstra,最初实现的是大顶堆的,在测试的时候,发现运行时间和他人对比相差甚远。
- 公测
在本单元测试中,我在最后一次强测中挂了一个ctle的点,具体超时的指令为qmp,其余就没遇到问题了。
这个强测挂了一个点确实有点让自己意外,因为已经采用了堆优化的 Dijkstra 算法,竟然还会超时(具体超时了 0.56s),之后询问了几个同学,发现同样使用堆优化的 Dijkstra 算法,但是大家的时间其实有些差别,具体体现在几个环节。
- 可达点距离的权值初始化
for (Integer integer : people.keySet()) {
distances.put(integer, -1);
}
这个环节我在提交的作业中,是遍历了所有点并添加了 -1 的权值,但是这个其实没有什么必要,只需要在之后的判断中添加判断,是否已经检查即可
HashMap的容器初始容量
int size = people.size();
HashMap distances = new HashMap<>(size);
在堆优化Dijkstra算法中,需要有一个容器来记录所有可达点的权值,但是对于某一个点来说,并非所有的点都可达,容器扩容是需要时间的,对于大量qmp的查询,会导致每次查询都需要扩容到最大水平,这个就会很消耗时间,所以在此处让容器自己扩容会比直接赋予容积大小要好一些
- 遍历容器的选择
HashMap values = person.getValue();
for (Integer integer : values.keySet()) {
...
}
对于某个点的可达点集合,我采用的是HashMap的方式,遍历的效率会不如ArrayList,这个点可以优化;同时采用entry的HashMap的遍历方式相较于keySet的遍历,也能提升一定性能。
- 服务器的状态
比较有意思的是,我同样的代码在不同的时间提交,一次爆了ctle,另一次就过了,差距能够达到 0.6s,所以我认为ctle的计算会不会和当前服务器的状态有较大的联系,这种不确定性也会导致TLE,或许日后复杂度较高的测试点可以适当放宽 CPU 的时间限制,这样更为合理点(个人看法)。
- 互测
本人在互测中未被 hack 出 bug,同时 hack 他人仅在第二次作业中 hack 出两个 bug,具体原因为没有对Group的相关变量进行缓存,而导致的 ctle。
心得体会
关于本单元的几点心得体会:
- 本单元的主要目的是了解 JML 这类的契约式编程的方式,同时学会阅读和编写规格
- 助教们设计的架构清晰明了,在设计上让自己收获不少
- 选择合理的实现方式,注重功能与效率的平衡,这个是我这单元收获比较大的部分,主要是这单元的测试就是复杂度和指令数的强测,在实现上需要更多地考虑性能方面的问题
几点不足:
- 本单元自己在架构上没有进行尝试,比如封装算法,独立成类,比如将图这个概念抽象出来,单独实现
- 在测试方面没有很下功夫,主要依靠和大佬们的对拍,然后自己构造些极端数据,并没有一开始就在性能方面进行些验证,而是最后出了问题才总结思考,恍然大悟
最后,吐槽一下 JML 的工具链,查找资料没有很完备的使用流程,主要都是通过往届学长们博客的碎片化信息,然后配置过程也是碰壁无数,最终的配置结果和检验输出也不知道是程序报错还是检查报告,然后 JML 的相关维护好像做得不是很好,尝试了一些方法,发生了程序内部的报错。或许日后,可以找个更合适的方式来引入这种契约式编程的介绍。
感谢助教,老师们在这单元的付出,确实收获了不少。