目录
- 从容器说起
- 背景
- docker实现原理
- 编排之争
- 基于容器的分布式系统设计之道
- 单节点协作模式
- Sidecar pattern(边车模式)
- Ambassador pattern(外交官模式)
- Adapter pattern(适配器模式)
- 多节点协作模式
- 单节点协作模式
都2020年了,容器,或者说docker容器这个概念,从事互联网行业的开发者应该都不会感到陌生。无论大厂还是小厂的应用部署现在都首选docker容器。
但是docker虽好,却并非万能。docker本身,其实仅仅是提供了一种沙盒的机制,对不同应用进行隔离。镜像是它出彩的一个设计,可以让开发者们快速部署应用。但这对大型应用管理来说,是远远不够的。开发者们在意识到这个问题后,提出了编排这个概念,从而引发的新的纷争。。。
本篇文章从容器的历史开始说起,然后介绍编排领域,swarm和k8s的纷争,最后讨论基于容器的系统设计模式,这个设计模式参考自google的论文,当然是基于k8s的啦~
PS:容器并非只有docker,但本篇暂略去了它们的差异,大部分情况下这两个词可以等价。
从容器说起
背景
在虚拟机和云计算较为成熟的时候,各家公司想在云服务器上部署应用,通常都是像部署物理机那样使用脚本或手动部署,但由于本地环境和云环境不一致,往往会出现各种小问题。
这时候有个叫Paas的项目,就是专注于解决本地环境与云端环境不一致的问题,并且提供了应用托管的功能。简单得说,就是在云服务器上部署Paas对应的服务端,然后本机就能一键push,将本地应用部署到云端机器。然后由于云服务器上,一个Paas服务端,会接收多个用户提交的应用,所以其底层提供了一套隔离机制,为每个提交的应用创建一个沙盒,每个沙盒之间彼此隔离,互不干涉。
看看,这个沙盒是不是和docker很类似呢?实际上,容器技术并不是docker的专属,docker只是众多实现容器技术中的一个而已。那为什么后来docker会变得如日中天呢?还是得从Paas说起。
Paas的本质就是通过一套打包(本地)-分发(云)的机制,帮助用户将应用分发到大规模的集群中,容器技术只是其中比较底层的一部分而已。听起来很完美,但问题恰恰就出现在这个打包功能上。打包功能比较繁琐,要为每个应用,语言,版本都打一个包,重点是打包过程常常出现问题,很可能本地运行得好好的,打包到Paas上就出现问题,而且这种问题无迹可寻,只能通过试错解决。换句话说,Paas确实可以让你体验到一键部署的快感,但在这之前,你要先体验打包过程的万千痛苦。
这个让用户痛苦万分的打包,docker的一个小创新的却能够解决,那就是镜像。镜像本身也是一种打包机制,并且这个镜像通常包含完整的操作系统,可以尽可能还原本地环境,同时你的应用还包含在这里面。
通过镜像这种东西,你可以方便得在本地开发,然后将镜像上传到云端服务器部署,且基本不需要或者只需要少量修改就可以使云端服务器拥有和本地一样的应用环境,然后可以通过这个镜像建立彼此隔离的沙盒环境,以部署自己的多个应用。
但是,docker虽然解决了Paas打包难的问题,但Paas原本的大规模集群部署的能力,却是docker的弱项,甚至docker本身并没有这方面的功能。
才有了后来提出的容器编排概念,Swarm和K8s就是围绕这块而起的纷争,当然那是另外一个故事了。
docker实现原理
说完了docker实现原理,接下来就来看看docker底层是如何实现沙盒隔离机制的。
说起docker,很多人都会将它与虚拟机进行比较,基本都会引用下面这张图:

其中左边是虚拟机的结构,右边是docker容器的结构,但这张图其实不是那么准确。在虚拟机中,通过Hypervisor对硬件资源进行虚拟化,在这部分硬件资源上安装操作系统,从而可以让上层的虚拟机和底层的宿主机相互隔离。但docker是没有这种功能的,我们在docker容器中看到的与宿主机相互隔离的沙盒环境(文件系统,资源,进程环境等),本质上是通过Linux的Namespace机制,CGroups(Control Groups)和Chroot等功能实现的。实际上Docker依旧是运行在宿主机上的一个进程(进程组),只是通过一些障眼法让docker以为自己是一个独立环境。接下来我们简单介绍下这部分内容。
如果在一个docker容器里面,使用ps命令查看进程,可能只会看到如下的输出:
/ # psPID USER TIME COMMAND 1 root 0:00 /bin/bash 10 root 0:00 ps在容器中执行ps,只会看到1号进程/bin/bash和10号进程ps。前面有说到,docker容器本身只是Linux中的一个进程(组),也就是说在宿主机上,这个/bin/bash的pid可能是100或1000,那为什么在docker里面看到的这个/bin/bash进程的pid是1呢?答案是linux提供的Namespace机制,将/bin/bash这个进程的进程空间隔离开了。
具体的做法呢,就是在创建进程的时候添加一个可选的参数,比如下面这样:
int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL); 那样后,创建的线程就会有一个新的命名空间,在这个命名空间中,它的pid就是1,当然在宿主机的真实环境中,它的pid还是原来的值。上面的这个例子,其实只是pid Namespace(进程命名空间),除此之外,还有network Namespace(网络命名空间),mount Namespace(文件命名空间,就是将整个容器的根目录root挂载到一个新的目录中,然后在其中放入内核文件看起来就像一个新的系统了)等,用以将整个容器和实际宿主机隔离开来。而这其实也就是容器基础的基础实现了。
但是,上述各种Namespace其实还不够,还有一个比较大的问题,那就是系统资源的隔离,比如要控制一个容器的CPU资源使用率,内存占用等,否则一个容器就吃尽系统资源,其他容器怎么办。
而Linux实现资源隔离的方法就是Cgroups,具体的使用方法就不多介绍。Cgroups主要是提供文件接口,即通过修改 /sys/fs/cgroup/下面的文件信息,比如给出pid,CPU使用时间限制等就能限制一个容器所使用的资源。
所以,docker本身只是linux中的一个进程,通过Namespace和cgroup将它隔离成一个个单独的沙盒。明白这点,就会明白docker的一些特性,比如说太过依赖内核的程序在docker上可能执行会出问题,比如无法在低版本的宿主机上安装高本版的docker等,因为本质上还是执行在宿主机的内核上。
对了,还有mac和windows系统,这些是怎么实现的呢?很简单,它们的docker都是建立在虚拟化的linux上的,所以其实还是linux。
说完容器,接下来就开始介绍编排了。
编排之争
这里我们主要会介绍编排这个概念,以及从这个概念起引发的docker swarm和k8s的纷争。
docker本身只是提供打包-部署的功能,它并没有提供分布式集群(大规模集群)管理的功能,这其实是原本Paas项目的主要领域。而编排才是容器技术的核心魅力所在,没有编排,容器就只是一个沙箱工具。所以从docker成熟以后,你会发现它的主要发力点是在编排,也就是swarm项目上,不过这个docker的亲儿子,swarm编排工具,却败给了横空出世的k8s。
为什么会这样?
先说说什么是容器的编排,说简单些就是对(docker)容器的配置,运行时候的行为的管理。
那么docker swarm是怎么进行编排的呢?这其实还涉及到另一个项目,docker-compose,这两个项目与docker Machine合称为docker三剑客(怎么听起来有点low)。
前面说到编排就是对容器的配置和运行行为进行管理,那么很自然的想法就是将这些配置和行为的定义都写到一个配置文件里面,比如用户需要运行容器A,容器B,容器C。那么我们可以将这几个容器相关的配置和关联,比如网络,磁盘,启动副本,出错行为等配置,还有容器间的协作方式(启动顺序等)都写到一个配置文件。最后通过一条命令,加载并执行这个配置文件,就能够实现容器的编排了。
swarm做的事情很简单,有时候简单不一定是好事,因为那意味着难以满足业界复杂的需求。比如它在处理有状态服务上的无力,又比如它难以处理多个服务间复杂的关系(处理服务的顺序是不够的)。这时候,脱胎于Borg的kubernetes(k8s)出现在人们的面前。它身上,沉淀着google数十年的经验,可以说它就是那个站在巨人肩膀上的宠儿。那么相比于swarm,它的优势到底在哪里呢?
答案在他的设计上,这个说起来得详细介绍k8s才能说明白。从设计上说,k8s整体是基于API设计,即整体架构中涉及的组件都可插拔,以容器举例,在k8s中,容器是可替换的,只要满足对应的接口设计的标准即可,docker是其中一种方案,而其他容器技术也是可选方案。和容器类似的还有网络插件,volume插件等等。有关k8s的详细内容这里不多介绍,有兴趣的童鞋可以参考以下文档:
- kubernetes设计理念
- Kubernetes设计架构
即整个设计是以集群管理为核心,整体架构都是松散的,可插拔的。而swarm则是以docker为核心,两者设计就存在本质上的区别。
而后在容器的基础上,k8s添加了另一层的封装,即Pod,所谓Pod,是一组相同或功能类似的容器所组成的组(task group)。为什么要有Pod呢?还记得容器的本质是什么吗,是操作系统中的一组进程,从某种程度上来说,从进程这个层次来进行管理,有些繁杂了。比如Linux都有进程组这个概念管理相同或彼此联系的一些进程(比如一个功能由多个进程协作完成,这多个进程构成一个进程组)。
在容器编排中,往往多个容器间也会有类似进程和进程组的关系(这里就不举例了,很多分布式组件都有这种情况),所以需要一个更高层次的抽象来帮助我们对容器进行管理。在k8s中,承担类似进程组的就是Pod,Pod是一种逻辑上的概念,同时Pod也是k8s中最小的调度单位,同组Pod中的容器都是共享volumns。
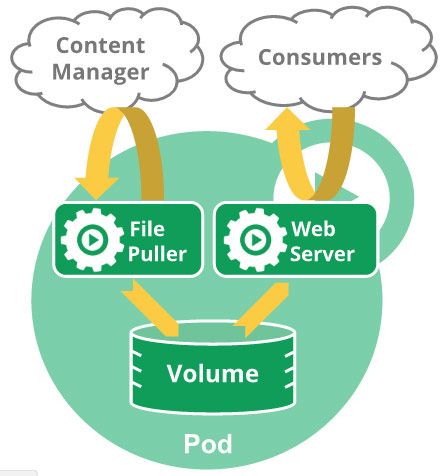
有了Pod,也就是组这个概念后,就能够更加方便对不同服务进行管理。但是它还有个更重要的意义,那就是基于容器的系统设计模式。
基于容器的分布式系统设计之道
让我们回到1980年,假设你是一个写惯了C的程序员,你接触到一个名叫面向对象的编程概念,你会怎么看待这个东西呢?能够想象这个东西在30年后会占据编程领域的大半壁江山吗?
而如今,docker容器(或者说Pod)就是一种类似OOP的东西,核心都是通过模块化封装,将不同的东西相互隔离,让它们相互配合,完成某些事情。
从这个角度,或许就能明白为什么前面说到的,容器价值不高,真正有价值的是编排。因为我们同样不会觉得一个java object有多大价值,OOP的编程思想,及其衍生的设计模式才是精髓。
那么从分布式系统的设计模式的角度来说,容器可以有多少种分类呢?和分布式系统的搭建模式类似,有三种。
- 单容器模式(single-container patterns for container management)
- 单节点协作模式(single-node patterns of closely cooperating containers)
- 和多节点协作模式(multi-node patterns)
PS:这部分内容多参考自google的Design patterns for container-based distributed systems,想看原味论文的童鞋请戳最下方的链接。
单容器模式和单节点协作模式看起来相似,但实际是完全不同的东西。
单容器模式,简单说就是在传统Docker的基础上(传统docker的行为比较简单,只有run(),pause(),stop()),提供更加丰富的功能和生命周期的管理。说得更简单点,使用k8s管理单个docker服务。
我们主要介绍单节点协作模式和多节点协作模式。
单节点协作模式
单节点协作模式,简单说就是在一个分布式的容器服务环境中,通过一个单节点的服务辅助进行管理的这类模式。在这种模式中,需要依赖于k8s中,Pod这个概念的抽象,Pod即task group,一组相同或类似服务的容器的集合。
主要有以下几种设计模式。
Sidecar pattern(边车模式)
边车,这个词可能很多人没听过(包括我了解这个东西之前)。我们先来贴一下边车的图,

边车就是摩托车旁边的那个小车,在某些环境下(比赛,我猜的),旁边车上的人可以给车手递水、食物等操作。
边车模式也是类似的,即在主服务(的容器,main container)身边提供一个辅助容器,帮助主服务做一些脏活累活。
比如一个web应用,它会将日志信息写入到磁盘中,这时候我们就可以新增加一个日志采集的边车,协助web服务完成日志采集的工作。就像下面这样:
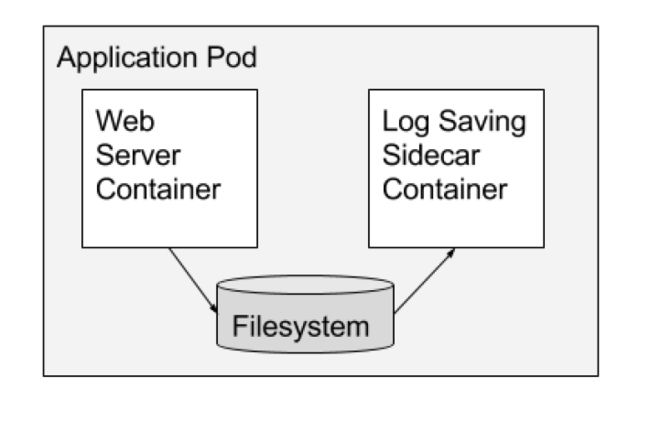
还是挺好理解的,这样的好处,相信了解过设计模式的童鞋随随便便就能列举几个,不过这里还是从容器的角度详细介绍下:
- 容器是资源分配的一个单元。将
边车服务分离后,可以更加灵活地通过cgroup配置资源,或者一些动态调节资源的操作(比如忙时给web服务更多资源而边车更少资源)。 - 容器是最小的打包单位。有助于不同服务的责任划分和测试。
- 容器可以是复用的单位,比如可以将日志服务用语其他服务。
- 提供了错误边界,可以使系统可以正常降级,比如日志服务出错,不会导致web服务出错。
- 容器是最小的部署单位,可以为每个服务升级,和回滚。但这也可能是缺点,因为服务一多难以管理。
因为分离所以多了这些好处,听起来还是蛮诱人的~
Ambassador pattern(外交官模式)
外交官模式,提供一个容器作为代理与主服务(main container)通信。
就相当于在通信口出做多一层代理,比如主服务以为是与一个本地redis通信,但实际上代理会真正与一个redis集群交互。
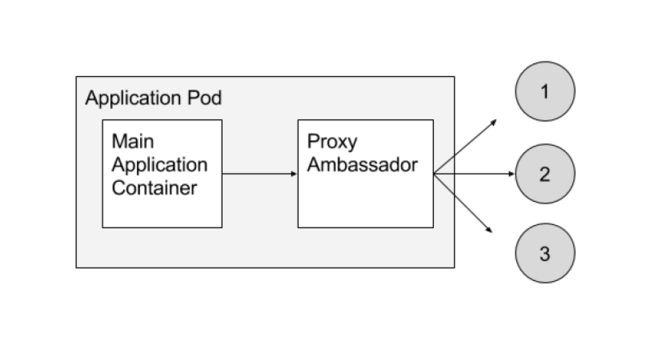
外交官模式的好处是,让主服务与外部组件之间相互隔离。只通过代理的话,那么外部组件可以无缝进行替换,而这一切主服务都是无感知的。然后是方便测试和复用,其实就是服务之间解耦的好处啦,和上面边车模式是有点类似的。
Adapter pattern(适配器模式)
前面说的两种模式,主要是为了帮助主服务(main coninter)更专注于自己的职责。而适配器模式则是为了方便其他组件。
举个例子,假设你有多个服务(web,数据库,缓存服务等),然后需要一个监控监控这几个组件是否正常。正常情况下,需要让监控系统获取不同服务之间的指标信息,然后才能进行监控。
但这样的问题是,如果增加或减少服务,那么对监控系统来说会很麻烦。适配器模式能够解决这种困扰。
如果多个服务,web,数据库,缓存等都提供一个统一的对外接口,那么我们就能够使用一个适配器容器,统一获取这些服务的指标信息,然后由监控系统通过这个适配器容器统一获取所有的指标信息。如下图所示。
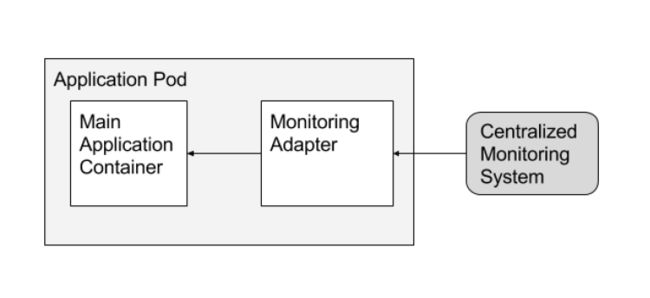
OK,那么以上就是单节点协作情况下的三种设计模式,下面再看看多节点的协作模式。
多节点协作模式
这部分内容会比较简单一些,这里就不花太多篇幅进行讲述。
除了单节点上的协作容器,模块化容器还使构建协作的多节点分布式应用程序变得更加容易。不过这部分内容听起来很高大上,但其实是很好理解的东西。
比如分布式领域的zookeeper,大家应该都不陌生,在论文中,这种多个节点提供领导者选举的模式,被称为领导者选举模式。同样的,kafka这类消息队列,被称之为工作队列模式(rk queue pattern)。而最后一种,则是类似spark的,master worker计算模式,即将一个计算任务分布到多个其他计算节点的这种方式,称之为Scatter/gather pattern模式。
列举的几种模式都是通过多个节点协作,并且通过暴露接口提供对外服务。不过其实基本就是常见的使用容器搭建分布式服务的方式,如果使用过docker来搭建hadoop这一套东西,那么对所谓的多节点协作模式肯定不会陌生。
想想也是,如果真的将分布式系统当做一个工程项目,那么这些多节点的部署模式确实需要一个名分。这可以算是一个典型的实践先于理论,理论总结实践的例子吧。(不过我还是觉得这部分内容有水论文的嫌疑)
那么关于容器的分布式系统设计的内容就先到这吧,有兴趣看原论文的童鞋可以翻到最下。
小结
OK,本文主要介绍了docker容器的发家历史,然后介绍容器编排的重要性,并简单说了为什么swarm会在编排的战争中输给了k8s。最后则从容器编排这个概念延伸到基于容器技术的设计模式,三种模式中,单节点协作模式算是比较新颖,还是有些启发价值的。
以上~
参考文章:
Design patterns for container-based distributed systems
kubernetes设计理念
Docker 核心技术与实现原理
An Introduction to Docker and Analysis of its Performance
文章转载:http://www.shaoqun.com/a/464188.html