「RPC」简述RPC
转载请注明出处:https://blog.csdn.net/jinixin/article/details/80711790
最近工作中一直有用到Thrift,所以想对此做个简单小结。分为两篇,第一篇(即本篇)介绍rpc是什么、其与http服务的区别、基本架构、使用步骤等,第二篇介绍常用rpc框架Thrift的Python案例。
可能写的有些平淡无奇或存在大量不准确之处,大家海涵。
引入
平时写程序中我们常常会用到函数调用,而一般的函数调用都在同一个进程内。但如果现在要求某个函数去调用另个工程里的一个函数,该怎么办呢?
我最先想到的是http服务,编写RESTful风格的url并通过http请求传递参数从而获得远程工程的响应,这个方法可以很方便的在两个程序间保持通讯。
如A工程下的a方法调用B工程下的b方法:

但有没有办法可以向本地调用那么畅快呢?不用在B工程下搭建http服务器,进行构建url、序列化/反序列化数据等一系列操作,就直接了当的像下面这样:
function a() {
...
B.b()
...
}答案是肯定的,这种调用方式被称为rpc,rpc全称是Remote Procedure Call,即远程过程调用,个人觉得称为远程函数调用可能更贴切。
1)rpc是一种计算机通信协议,其允许程序通过网络调用某远程计算机上的某个服务(函数),而开发人员无需额外为此编程。
2)使用rpc使得我们可以非常便捷的搭建分布式系统。是不是一下子就感觉自己高大上了不少,以前听别人谈到分布式就感觉很高深,没想到自己现在也在搭建分布式系统了。
3)虽然rpc是一种通信协议,但我觉得其是抽象的,不像HTTP协议那么具体,有详细的标准。各个公司都有自己的rpc协议,很多都做成了开源软件。
rpc与http的区别
可是rpc服务相较于http服务在网间通讯上有什么优势呢?
1. http服务使用HTTP协议传输数据,其的header会在消息中占很大比例,由于接收方不是浏览器,因此这部分就是废信息,完全是在浪费带宽。而rpc服务普遍基于TCP协议,自定义了消息格式,携带很少的无用信息,具有很高效率。但2015年推出的HTTP2.0协议会对header做压缩,故使用HTTP2.0来传输数据也可以接受。
2. rpc服务普遍基于TCP协议,http服务则基于HTTP协议。我们知道在计算机网络的工业实现中一般采用4层模型,从上至下依次为:应用层,传输层,网络层,链路层。

TCP协议位于传输层,而HTTP协议则基于TCP协议,位于应用层中。因此相较于rpc服务直接使用TCP协议包装,http服务则需依次经过HTTP与TCP的两次包装,速度不言而喻。
3. rpc服务使用长链接,相较于http服务的短链接,避免大量三次握手所带来的性能下降。
这条理由目前已没那么重要了,在HTTP1.0中需要keep-alive来建立长连接,HTTP1.1默认长连接,HTTP2.0支持多路复用,即一个连接处理多个请求,这一系列举动在于尽量避免http服务建立连接时的过多握手。目前觉得这点可能不会太影响效率,并且Google的rpc框架GRPC就是基于HTTP2.0的。
从上面三点可以看出,相较于http服务,rpc服务具有更快的速度,并所需更小的带宽。
4. rpc服务内部直接指明服务器ip,且传输的数据是经过自己编码过的,因此具有更高的安全性。可以认为采用http传递信息是在讲普通话,而rpc则是讲团队黑话,具有更高的保密性。
5. rpc服务有许多现成的rpc框架,我们自己只需去实现服务器端的一些处理函数。有关读写网络内容,使用传输协议序列化/反序列化数据,处理器调用等操作框架会自动处理,我们不必操心。并且rpc框架还封装了错误重试等特性,针对服务的稳定性和可靠性都做了优化,而单纯的http服务是没有这些特性的。
到底选择http服务或rpc服务来传递数据,还是要看具体工程,没有绝对好坏之分,但rpc确实适合大型项目不同工程间的内部调用。另外说一下,在http服务器上增加一层封装,也就变成了rpc服务,比如Google的GRPC框架。
rpc的架构
rpc是典型的客户端/服务器模式,请求发起者是客户端,而服务提供者是服务器。客户端与服务器之间需要事先约定好传输方式与编码协议。
个人感觉一个rpc框架逃不开四大核心组件:Client、Server、Client Stub、Server Skeleton。
1)Client:客户端,服务的调用方
2)Server:服务端,服务的真正提供者
3)Client Stub:客户端存根,存放有服务器地址,其将客户端的请求打包后通过网络发给服务方
4)Server Skeleton:服务端存根,用于接收客户端发来的消息,将消息解包后调用服务端本地方法,并将本地方法的返回值打包后回复给客户端
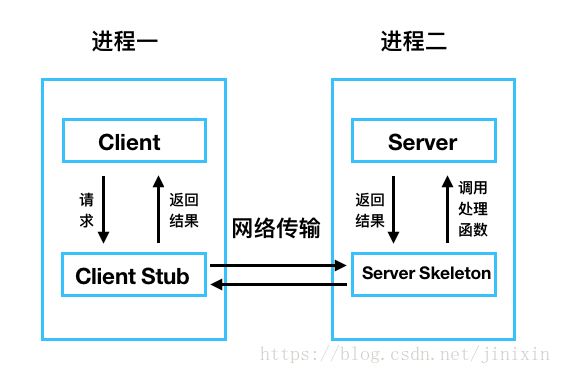
其中的存根可以理解成是接口,即需要自己编写代码去实现。其目的是屏蔽客户端调用远程主机上某个对象的过程,其提供某种方式在本地模拟远程对象,负责接收本地方法的调用,并将请求委派给远端的具体执行对象。
上面的这段描述可能有些绕,下面稍作解释(A工程下的a方法调用B工程下的b方法):

使用rpc时,A工程为客户端,B工程为服务端。为了使B工程下的b方法在a方法中可被调用,我们会在A工程里为b方法搞个替身c。

c方法一旦被调用,其会调用客户端的stub,stub通过网络调用服务端的skeleton,而skeleton则调用并返回本地b方法的执行结果。由此,a方法在调用客户端c方法的时候,感觉上就是直接调用了远端服务器的b方法。
使用rpc的步骤
虽然可供选择的rpc框架非常多,但使用的大体流程似乎都差不多:
1. 使用类似的IDL(接口描述语言)定义数据结构和接口
2. 选择目标语言,用框架的代码生成引擎生成rpc的客户端,服务端,客户端存根,服务端存根等代码
3. 配置客户端与服务器,将响应客户端请求的处理器与目标服务相绑定,也就是这个绑定过程需要开发者编写一些代码
通过上面三步整个rpc服务便搭建好了,我们可以很轻松的在A工程的a方法内调用B工程的b方法。
想必通过上面这些,我们已经对rpc有了大致了解。在第二篇中将简单介绍Facebook的rpc框架Thrift,并给出Python实现的具体案例。文中有不当之处,望大家海涵与指出,谢谢。
参考链接:
https://blog.csdn.net/wangyunpeng0319/article/details/78651998