python网络爬虫学习(五) 模拟登陆北邮信息门户并爬取信息
之前利用爬虫爬取过百度贴吧的部分页面,但是百度贴吧并不需要登录。当我们发现一些网站上有具有实用价值的信息时,又往往需要登录后才能查看这些信息。那么如何通过python模拟登陆这些网站呢?我们以北邮信息门户为例。
一.工具
1.requests库
2.firefox浏览器和Temper Data
“工欲善其事,必先利其器”,之前我们介绍过urllib和urllib2这两个python自带的库。而requests库是一个第三方库,相比于前两个库则显得更为好用。
requests库提供了get,post,delete等方法,我们待会儿将用它来向网站发出请求
Temper Data是一个firefox插件,它能够拦截表单,以便我们查看表单内容。
二.爬取前的准备工作
首先打开信息门户网站”http://my.bupt.edu.cn/index.portal“,一个登录界面挡住了我们
我们使用chrome浏览器的开发者模式,按下F12即可进入。 先输入一个错误的密码,点击登录按钮向网站发送一个表单。之后我们在查看这个表单都具有哪些内容。
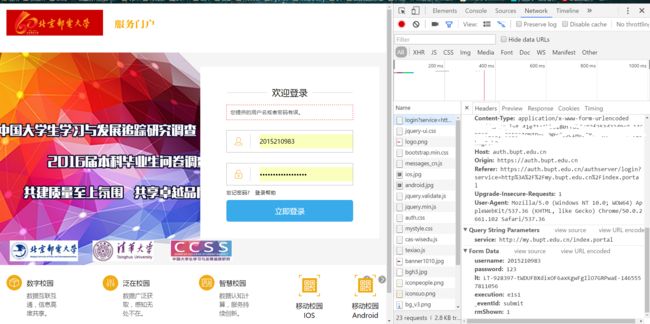
安全起见,我没有输入真实的密码,擦掉了cookie等敏感信息。我们看到表单中具有这样几个内容:
1.username
2.password
3.lt(待会儿介绍这是什么)
4.execution
5._eventId:
6.rmShown
通过分析,我们知道要想登录,就要构造含有上面这些内容的表单,username,password由用户提供,经过多次的抓取表单分析后,发现execution,_eventId,rmShown都是常量。
那么唯一没有解决的问题就是lt,lt在每次的发送的表单中都不相同,而且看不出什么规律,lt到底是什么呢?
回想起前些天模拟登陆CSDN时也遇到了一个名为lt的项目,会不会是类似的东西呢。于是我打开了CSDN登录界面的源代码,如图
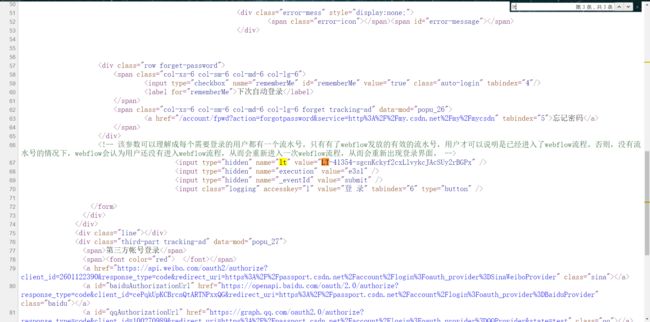
通过搜索lt,我发现了这个数据的具体含义,lt可以理解成每个需要登录的用户都有一个流水号。只有有了webflow发放的有效的流水号,用户才可以说明是已经进入了webflow流程。否则,没有流水号的情况下,webflow会认为用户还没有进入webflow流程,从而会重新进入一次webflow流程,从而会重新出现登录界面。
那么如何获得这个数据呢?很简单,只需要get方式请求到登录界面的内容,用Beautifulsoup解析所有的input标签,将所有input标签 的name和value两个量写成一个字典即可,需要用lt时,从字典中提取即可。
还有一个问题需要解决,在我们请求页面以获取lt值后,如果再用post发送我们构造好的表单,在这个过程中,相当于刷新了一下页面,换句换说,我们先前获得的lt值已经不再是现在的lt值了,所以这个时候我们就要用requests的session方法来保持cookie不变了,session方法可以让同一个实例发出的所有请求保持相同的cookie。
说了这么多,下面请看代码:
#-*-coding=utf-8-*-
#encode=utf-8
import requests
import cookielib
from bs4 import BeautifulSoup as bs
def getLt(str):
lt=bs(str,'html.parser')
dic={}
for inp in lt.form.find_all('input'):
if(inp.get('name'))!=None:
dic[inp.get('name')]=inp.get('value')
return dic
header={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0'
}
#setting cookie
s=requests.Session()
s.cookies=cookielib.CookieJar()
r=s.get('https://auth.bupt.edu.cn/authserver/login?service=http%3A%2F%2Fmy.bupt.edu.cn%2Findex.portal',headers=header)
dic=getLt(r.text)
postdata={
'username':'',#此处为你的学号
'password':'',#你的密码
'lt':dic['lt'],
'execution':'e1s1',
'_eventId':'submit',
'rmShown':'1'
}
response=s.post('https://auth.bupt.edu.cn/authserver/login?service=http%3A%2F%2Fmy.bupt.edu.cn%2Findex.portal',data=postdata,headers=header)
response2=s.get('http://my.bupt.edu.cn/index.portal',headers=header)
soup=bs(response2.text,'html.parser')
info=soup.find_all('div',class_='timeinfobox')
Date=soup.find_all('div',class_='timedateup')
Time=soup.find_all('div',class_='timedatedown')
Title=soup.find_all('a',class_='timetitle')
Tea=soup.find_all('spam')
date=[]
time=[]
title=[]
tea=[]
for dt in Date:
date.append(dt.string)
for ti in Time:
time.append(ti.string)
for tit in Title:
title.append(tit.string)
for teacher in Tea:
print teacher.string
for i in range(0,len(date)):
print date[i]
print time[i]
print title[i]
不明白的地方见注释,我在登陆成功之后用Beautifulsoup获取了关于讲座信息的一些内容,程序运行结果如图:
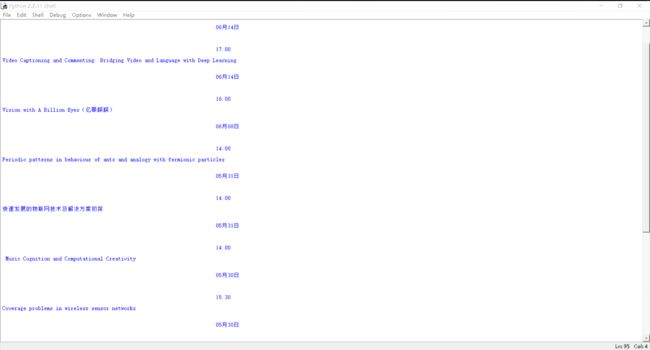
至此,我们就介绍完了爬取信息门户的整个过程,我们当然可以从页面上获取别的数据,不过我更关心各种各样的讲座,所以写了这样一个爬虫,免去了每次要登陆信息门户的麻烦。
2016-06-10
于朝阳