
实验思考题
1.1
也许你会发现我们的readelf程序是不能解析之前生成的内核文件(内核文件是可执行文件)的,而我们之后将要介绍的工具readelf则可以解析,这是为什么呢?
调用readelf,读取vmlinux与testELF得到的结果分别为:
- vmlinux

- testELF

可以发现两个文件存储方式不同,vmlinux为大端存储而testELF为小端存储。我们所写的文件在识别文件格式时会判定大端存储的数据不可读。
1.2
内核入口在什么地方?main函数在什么地方?我们是怎么让内核进入到想要的 main 函数的呢?又是怎么进行跨文件调用函数的呢?
内核入口起始地址0x00000000;main函数地址存放在0x80010000;我们通过执行跳转指令(jal)跳转到main函数并执行;跨文件调用函数时,由于每个函数会被分配自己的地址,因此调用过程为 保护数据(入栈等) -> 跳转指令跳转到指定位置。
实验难点图示
个人感觉本次实验最难的是读懂别人的代码。亦或者更精确和细化一些——知晓已有的代码部分拥有了哪些数据。
事实上,我们确实只需要知道已有的各项数据的 格式 + 用途,即明白:
- 我有什么;
- 我能拿他们干什么;
- 我该怎么调用他们;
而相比之下,我们对于这些数据是怎样得到的,即源代码是怎样操作的,知道的并不需要很精确,只要明白大致思路就可以。毕竟即使思路一致,实现的方法、程序的写法也必然千千万万,不然就没有作业查重一说了。
例如我们在编写自己的readelf函数时,我们知道了elf文件的存储格式:
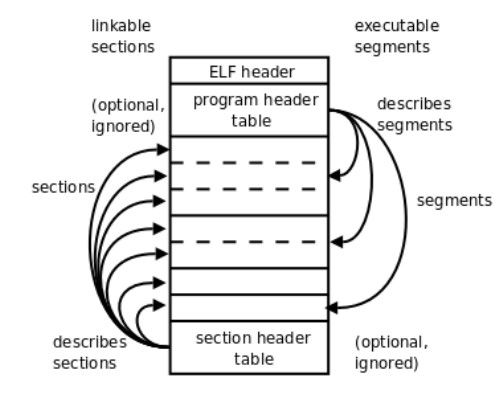
又知道了已有程序帮我们提取了elf的信息并存入了结构体:
typedef struct {
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
// 存放魔数以及其他信息
Elf32_Half e_type; /* Object file type */
// 文件类型
Elf32_Half e_machine; /* Architecture */
// 机器架构
Elf32_Word e_version; /* Object file version */
// 文件版本
Elf32_Addr e_entry; /* Entry point virtual address */
// 入口点的虚拟地址
Elf32_Off e_phoff; /* Program header table file offset */
// 程序头表所在处与此文件头的偏移
Elf32_Off e_shoff; /* Section header table file offset */
// 段头表所在处与此文件头的偏移
Elf32_Word e_flags; /* Processor-specific flags */
// 针对处理器的标记
Elf32_Half e_ehsize; /* ELF header size in bytes */
// ELF文件头的大小(单位为字节)
Elf32_Half e_phentsize; /* Program header table entry size */
// 程序头表入口大小
Elf32_Half e_phnum; /* Program header table entry count */
// 程序头表入口数
Elf32_Half e_shentsize; /* Section header table entry size */
// 段头表入口大小
Elf32_Half e_shnum; /* Section header table entry count */
// 段头表入口数
Elf32_Half e_shstrndx; /* Section header string table index */
// 段头字符串编号
} Elf32_Ehdr;
这时我们意识到,在填写程序剩余部分时,
- 我们拥有结构体中的数据
- 数据的存储格式可以在已有程序中找到
此时我们便要挑选出我们需要的数据:
- e_shoff
- e_shentsize
- e_shnum
接下来便容易地完成了程序的填补。
在填print.c文件时自己写出来了2处bug,都和把已有数据的使用方法搞错有关。
- 在调用printNum函数时,negFlag参数位置放错;
- 把width应当记录的数据记录在了length中。
综上,阅读,特别是使用已有程序时,最重要的是知晓已有的各项数据的 格式 + 用途。
体会与感想
1. 操作系统启动既麻烦又简单
OS的启动很困难而复杂,其终极原因在于启动本身面临着“先有鸡还是先有蛋”的问题。在这样的环境背景下,系统的启动要对软件和硬件进行一系列约束;同时,各种启动方法也都在为可移植性做努力,而这进一步加深了启动的复杂性。
但反向思考,在众多的约束条件下,启动时能够进行的工作并不是很多,而启动本身要达成的目标又十分清晰,少选择性+强目的性是我说其“简单”的原因。
2. C语言地位无法撼动
总感觉C语言就像是连接起汇编语言和(更)高级语言之间的桥梁。C语言既有其易用性,有高级语言的特点,又有汇编语言的特点,运行时的依赖比较少。这样的桥梁一样的C语言地位实在是高。特别是更靠近硬件的层面,例如操作系统,C或许是最合适的语言了。
3. 制定规则重要而难度颇高
想要启动一台机器,进行的操作必然要符合机器本身的要求。这次的实验需要花费大量时间在阅读内存空间分配等“规则”上。便也想到了制定规则必要清晰,而而且严格遵守。
4. 读别人代码可能不难,难在用别人的思路去写代码
接受别人的思路并运用需要读懂+理解+接受三个过程。