使用KNN算法识别数字
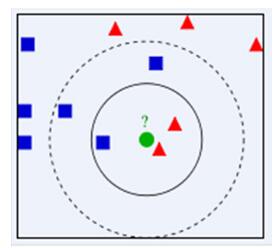
KNN算法作为一种重要的分类算法,这里一步步地构造使用k近邻分类器的手写识别系统。为了简单起见,这里构造的系统只能识别数字0到9,参见下图。需要识别的数字已经使用图形处理软件,处理成具有相同的色彩和大小 :宽高是32像素x32像素的黑白图像。尽管采用文本格式存储图像不能有效地利用内存空间,但是为了方便理解,我们还是将图像转换为文本格式。

digits 目录下有两个文件夹,分别是:
trainingDigits:训练数据,1934个文件,每个数字大约200个文件。testDigits:测试数据,946个文件,每个数字大约100个文件。
每个文件中存储一个手写的数字,文件的命名类似0_7.txt,第一个数字0表示文件中的手写数字是0,后面的7是个序号。
我们使用目录trainingDigits中的数据训练分类器,使用目录testDigits中的数据测试分类器的效果。两组数据没有重叠,你可以检查一下这些文件夹的文件是否符合要求。根据这些数据我们开始实现KNN算法。
我们需要打开一个 Xfce 终端,输入 ipython 进入到交互式模式来边写代码边测试。
k-近邻(k-NN)算法我们在理论学习部分已经有所了解,本节内容将实现这个算法的核心部分:计算“距离”。
当我们有一定的样本数据和这些数据所属的分类后,输入一个测试数据,我们就可以根据算法得出该测试数据属于哪个类别,此处的类别为0-9十个数字,就是十个类别。
算法实现过程:
- 计算已知类别数据集中的点与当前点之间的距离;
- 按照距离递增次序排序;
- 选取与当前点距离最小的k个点;
- 确定前k个点所在类别的出现频率;
- 返回前k个点出现频率最高的类别作为当前点的预测分类。
算法实现为函数 classify0(),函数的参数包括:
- inX:用于分类的输入向量
- dataSet:输入的训练样本集
- labels:样本数据的类标签向量
- k:用于选择最近邻居的数目
全部代码如下所示,
#-*- coding: utf-8 -*-
from imp import reload
from numpy import *
import operator
from os import listdir
# 读取数据到矩阵
def img2vector(filename):
# 创建向量
vec = zeros((1, 1024))
# 打开数据文件,读取每行内容
fr = open(filename)
for index_x in range(32):
# 读取每一行
imgline = fr.readline()
# 将每行前32字符转成int存入向量
for index_y in range(32):
vec[0, index_x * 32 + index_y] = int(imgline[index_y])
return vec
pass
# KNN算法实现
def KNNClassfy(imgvector, imgdict, imgtype, k):
# 获取样本数据数量
imgdictsize = imgdict.shape[0]
imgvector_plus = tile(imgvector, (imgdictsize,1))#####
# 矩阵运算,计算测试数据与每个样本数据对应数据项的差值
diffimgvector = imgvector_plus - imgdict
# 上一步结果的平方和
sqdiffimgvector = diffimgvector**2
sqsumdiffimgvector = sqdiffimgvector.sum(axis=1)
# 取平方根,得到距离向量
distances = sqsumdiffimgvector**0.5
# 按照距离从低到高排序
imgvectorindex = distances.argsort()
classcount = {}
# 依次取出最近的样本数据
for index in range(k):
# 记录该样本数据所属的类别
sortindex = imgvectorindex[index]
classcount[imgtype[sortindex]] = classcount.get(imgtype[sortindex], 0) + 1
# 对类别出现的频次进行排序,从高到低
sortclasscount = sorted(classcount.iteritems(), key=operator.itemgetter(1), reverse=True)
# 返回出现频次最高的类别
return sortclasscount[0][0]
pass
# 测试算法
def HandwritenumTest():
# 样本数据文件列表
trainingfiles = listdir('digits/trainingDigits')
trainingfileslen = len(trainingfiles)
# 初始化样本数据矩阵(len*1024)
imgdict = zeros((trainingfileslen, 1024))
# 样本数据的类标签列表
imgtype = {}
# 依次读取所有样本数据到数据矩阵
for index in range(trainingfileslen):
# 提取文件名中的数字
filenamestr = trainingfiles[index]
filetypestr = filenamestr.split('.')[0]
filetype = int(filetypestr.split('_')[0])
imgtype[index] = filetype
# 将样本数据存入矩阵
imgdict[index] = img2vector('digits/trainingDigits/%s' % trainingfiles[index])
# 测试数据文件列表
testfiles = listdir('digits/testDigits')
testfileslen = len(testfiles)
# 初始化错误率
errorcount = 0.0
# 循环测试每个测试数据文件
for index in range(testfileslen):
# 提取文件名中的数字
filenamestr = testfiles[index]
filetypestr = filenamestr.split('.')[0]
filetype = int(filetypestr.split('_')[0])
# 提取数据向量
imgvector = img2vector('digits/testDigits/%s' % testfiles[index])
# 对数据文件进行分类
classfytype = KNNClassfy(imgvector, imgdict, imgtype, 3)
# 打印KNN算法分类结果和真实的分类
print("the classifier came back with: %d, the real answer is: %d" % (classfytype, filetype))
# 判断KNN算法结果是否准确
if filetype != classfytype:
errorcount += 1
# 打印错误率
print("\nthe total number of errors is: %d" % errorcount)
print("\nthe total error rate is: %f" % (errorcount / float(testfileslen)))
pass
# 执行算法测试
HandwritenumTest()
# vec = img2vector('digits/testDigits/0_1.txt')
# print vec[0, 0:31]
# b=[1,3,5]
# a=tile(b,[2,3])
# print "a.sum ",a.sum(axis=1)
# a=[1,2,3,4,5,56,8,7,9,11,4,4,2,2,1]
# a=tile(a,1)
# print "argsort ",a.argsort()
#
# c={}
# c[0]={1,2}
# c[1] ={3,12}
# c[2] ={4,3}
# print c.get(2,0)
# students = [('john', 'A', 12), ('jane', 'B', 12), ('dave', 'B', 10)]
# print sorted(students, key=operator.itemgetter(2,1,0), reverse=True)
#
# trainingfiles = listdir('digits/trainingDigits')
# print trainingfiles[0]描述
Python 字典(Dictionary) get() 函数返回指定键的值,如果值不在字典中返回默认值。
语法
get()方法语法:dict.get(key, default=None)
参数
key -- 字典中要查找的键。default -- 如果指定键的值不存在时,返回该默认值值。
返回值
返回指定键的值,如果值不在字典中返回默认值None。
shape函数
shape函数是numpy.core.fromnumeric中的函数,它的功能是读取矩阵的长度,比如shape[0]就是读取矩阵第一维度的长度。它的输入参数可以使一个整数表示维度,也可以是一个矩阵。
shape函数定义
def shape(a):
"""
Return the shape of an array.
Parameters
----------
a : array_like
Input array.
Returns
-------
shape : tuple of ints
The elements of the shape tuple give the lengths of the
corresponding array dimensions.
See Also
--------
alen
ndarray.shape : Equivalent array method.
Examples
--------
>>> np.shape(np.eye(3))
(3, 3)
>>> np.shape([[1, 2]])
(1, 2)
>>> np.shape([0])
(1,)
>>> np.shape(0)
()
>>> a = np.array([(1, 2), (3, 4)], dtype=[('x', 'i4'), ('y', 'i4')])
>>> np.shape(a)
(2,)
>>> a.shape
(2,)
"""
try:
result = a.shape
except AttributeError:
result = asarray(a).shape
return resultlist,set等都没有shape属性,因此不能直接使用.shape,下面是asarray的使用使用方式,
numpy.asarray(a,dtype=None,order=None)
功能描述:将输入数据(列表的列表,元组的元组,元组的列表等)转换为矩阵形式
a:数组形式的输入数据,包括list,元组的list,元组,元组的元组,元组的list和ndarrays
dtype:
数据类型由输入数据推导
注:asarray对已经是数组的数据不做任何处理也不会被拷贝,可以如下验证:
from numpy import array
array([1,2,3,4])
asarray(a) is aargsort函数
Help on function argsort in module numpy.core.fromnumeric:
argsort(a, axis=-1, kind='quicksort', order=None)
Returns the indices that would sort an array.
Perform an indirect sort along the given axis using the algorithm specified
by the `kind` keyword. It returns an array of indices of the same shape as
`a` that index data along the given axis in sorted order.
将x中的元素从小到大排列,提取其对应的index(索引),然后输出到y。
a=[1,2,3,4,5,56,8,7,9,11,4,4,2,2,1]
a=tile(a,1)
print "argsort ",a.argsort()http://blog.csdn.net/maoersong/article/details/21875705
numpy.tile函数
函数格式tile(A,reps)
* A:array_like
* 输入的array
* reps:array_like
* A沿各个维度重复的次数
A和reps都是array_like
A的类型众多,几乎所有类型都可以:array, list, tuple, dict, matrix以及基本数据类型int, string, float以及bool类型。
reps的类型也很多,可以是tuple,list, dict, array, int, bool.但不可以是float, string, matrix类型。
举例:A=[1,2]
1. tile(A,2)
结果:[1,2,1,2]
2. tile(A,(2,3))
结果:[[1,2,1,2,1,2], [1,2,1,2,1,2]]
3. tile(A,(2,2,3))
结果:[[[1,2,1,2,1,2], [1,2,1,2,1,2]],
[[1,2,1,2,1,2], [1,2,1,2,1,2]]]
reps的数字从后往前分别对应A的第N个维度的重复次数。如tile(A,2)表示A的第一个维度重复2遍,tile(A,(2,3))表示A的第一个维度重复3遍,然后第二个维度重复2遍,tile(A,(2,2,3))表示A的第一个维度重复3遍,第二个维度重复2遍,第三个维度重复2遍。
numpy.sum(axis=1)函数
例如:
import numpy as np
np.sum([[0,1,2],[2,1,3],axis=1)
结果就是:array([3,6])
下面是自己的实验结果,与上面的说明有些不符:
a = np.array([[0, 2, 1]])
print a.sum()
print a.sum(axis=0)
print a.sum(axis=1)
结果分别是:3, [0 1 2], [3]
b = np.array([0, 2, 1])
print b.sum()
print b.sum(axis=0)
print b.sum(axis=1)
结果分别是:3, 3, 运行错误:'axis' entry is out of bounds
可知:对一维数组,只有第0轴,没有第1轴
c = np.array([[0, 2, 1], [3, 5, 6], [0, 1, 1]])
print c.sum()
print c.sum(axis=0)
print c.sum(axis=1)
结果分别是:19, [3 8 8], [ 3 14 2]
axis=0, 表示列。
axis=1, 表示行。
sorted函数
我们需要对List、Dict进行排序,Python提供了两个方法
对给定的List L进行排序,
方法1.用List的成员函数sort进行排序,在本地进行排序,不返回副本
方法2.用built-in函数sorted进行排序(从2.4开始),返回副本,原始输入不变
--------------------------------sorted---------------------------------------
>>> help(sorted)
Help on built-in function sorted in module __builtin__:
sorted(...)
sorted(iterable, cmp=None, key=None, reverse=False) --> new sorted list
---------------------------------sort----------------------------------------
>>> help(list.sort)
Help on method_descriptor:
sort(...)
L.sort(cmp=None, key=None, reverse=False) -- stable sort *IN PLACE*;
cmp(x, y) -> -1, 0, 1
-----------------------------------------------------------------------------
iterable:是可迭代类型;
cmp:用于比较的函数,比较什么由key决定;
key:用列表元素的某个属性或函数进行作为关键字,有默认值,迭代集合中的一项;
reverse:排序规则. reverse = True 降序 或者 reverse = False 升序,有默认值。
返回值:是一个经过排序的可迭代类型,与iterable一样。
参数说明:
(1) cmp参数
cmp接受一个函数,拿整形举例,形式为:
def f(a,b):
return a-b
如果排序的元素是其他类型的,如果a逻辑小于b,函数返回负数;a逻辑等于b,函数返回0;a逻辑大于b,函数返回正数就行了
(2) key参数
key也是接受一个函数,不同的是,这个函数只接受一个元素,形式如下
def f(a):
return len(a)
key接受的函数返回值,表示此元素的权值,sort将按照权值大小进行排序
(3) reverse参数
接受False 或者True 表示是否逆序
students = [('john', 'A', 12), ('jane', 'B', 12), ('dave', 'B', 10)]
print sorted(students, key=operator.itemgetter(2,1,0), reverse=True) Python中 dict.items() dict.iteritems()区别
Python 文档解释:
dict.items(): Return a copy of the dictionary’s list of (key, value) pairs.
dict.iteritems(): Return an iterator over the dictionary’s (key, value) pairs.
dict.items()返回的是一个完整的列表,而dict.iteritems()返回的是一个生成器(迭代器)。
dict.items()返回列表list的所有列表项,形如这样的二元组list:[(key,value),(key,value),...],dict.iteritems()是generator, yield 2-tuple。相对来说,前者需要花费更多内存空间和时间,但访问某一项的时间较快(KEY)。后者花费很少的空间,通过next()不断取下一个值,但是将花费稍微多的时间来生成下一item。