《28天玩转TensorFlow2》第7天:TensorFlow2构建数据管道—Numpy array格式
tf.data提供了快速、灵活、易于使用的数据管道,同时还提供同步的训练,所谓同步训练就是利用CPU处理数据,供给GPU或者TPU(如果有的话)来训练数据。将数据集转变为数据管道的形式,有助于提升训练的效率。下面通过实例Numpy array格式数据集如何构建数据管道,以及数据的预处理、模型的训练和最终结果的展示。
实例:数字0-9和字母A-Z识别
数据集说明:
- 该数据集有36个类别标签:数字0-9,字母A-Z;
- 每个类别对应一个数组,数组的长度为39,也就是说每个类别有39个样本;
- 数组的元素是一个维度为(20, 16)的数组,数组中的元素为0或者1;
0、可视化Tensorboard
打开Anaconda Prompt, 激活环境activate tf2,安装pip install jupyter-tensorboard。
%%time
# 上面的语句可以查看每个单元格执行完用的时间
# 注意上面计时的命令只能在单元格的第一行,并且后面不能有任何的字符,空格也不行,否则都会报错
import tensorflow as tf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.unicode_minus']=False
import os, datetime
print('tensorflow版本:', tf.__version__)
tensorflow版本: 2.1.0
CPU times: user 1.3 s, sys: 206 ms, total: 1.51 s
Wall time: 1.52 s
1、Numpy array格式:数字0-9和字母A-Z识别数据集
1.1 数据获取
# binary_alpha_digits格式的数据集的网址
Data_Url_Mnist ='https://cs.nyu.edu/~roweis/data/binaryalphadigs.mat'
# 文件下载到制定的路径
Path_Mnist = tf.keras.utils.get_file(r'/Users/anfany/Documents/编程/tf_28_days/binaryalphadigs.mat', Data_Url_Mnist)
Downloading data from https://cs.nyu.edu/~roweis/data/binaryalphadigs.mat
532480/532304 [==============================] - 35s 66us/step
# 解析数据,因为原始数据格式为mat格式
import scipy.io as scio
matdata = scio.loadmat(Path_Mnist)
# 打印标签
label_data = np.array([c[0] for c in matdata['classlabels'][0]])
print('标签:', label_data)
# 特征数据
feature_data = matdata['dat']
print('特征数据维度:', feature_data.shape)
标签: ['0' '1' '2' '3' '4' '5' '6' '7' '8' '9' 'A' 'B' 'C' 'D' 'E' 'F' 'G' 'H'
'I' 'J' 'K' 'L' 'M' 'N' 'O' 'P' 'Q' 'R' 'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z']
特征数据维度: (36, 39)
# 显示第n列数据
def show(feadata, labedata, n): # n为类别的索引
plt.figure(figsize=(14, 10))
# 添加标签
plt.title('标签:${}$'.format(labedata[n]), fontsize=16)
# 关闭坐标轴
plt.xticks([])
plt.yticks([])
# 显示图片:因为每条数据其实有39个样本,先将样本连接起来
one_data = feadata[n][0]
for kk in feadata[n][1:]:
one_data = np.hstack((one_data, kk))
plt.imshow(one_data, 'gray') # 显示为灰度图片
# 索引为35的类别是Z
show(feature_data, label_data, 35)
# 索引为2的类别是2
show(feature_data, label_data, 2)
# 需要注意的是:数据集中的数字0类和大写字母O类是一样的数据。原始数据集存在错误
show(feature_data, label_data, 0)
show(feature_data, label_data, 24)



1.2 Numpy格式数据
# 首先将标签数据变为整数型
Label_Dict = {}
New_Label = []
for index, value in enumerate(label_data):
Label_Dict[index] = value
New_Label.append(index)
New_Label = np.array(New_Label)
# 数据变为特征、标签数据
all_feature_data = []
for c in feature_data:
for s in c:
all_feature_data.append(s)
# 特征数据
all_feature_data = np.array(all_feature_data)
# 标签数据:扩充39次
all_label_data = New_Label.repeat(39)
print(all_feature_data.shape)
print(all_label_data.shape)
(1404, 20, 16)
(1404,)
# 在这里将数据集按照比例分割为训练、验证、测试数据集,保证每个数据集中每个类别的样本数相同
def split_data(fdata, ldata, valid_p=0.15, test_p=0.1, length=36, count=39, model='cnn'):
f_split = np.array_split(fdata, length)
l_split = np.array_split(ldata, length)
train_f_data = []
train_l_data = []
valid_f_data = []
valid_l_data = []
test_f_data = []
test_l_data = []
for index, value in enumerate(f_split):
all_ind = np.random.permutation(count)
valid_c = int(count * valid_p)
test_c = int(count * test_p)
valid_index = all_ind[:valid_c]
test_index = all_ind[valid_c: (valid_c + test_c)]
train_index = all_ind[(valid_c + test_c):]
try:
train_f_data = np.vstack((train_f_data, value[train_index]))
train_l_data = np.hstack((train_l_data, l_split[index][train_index]))
valid_f_data = np.vstack((valid_f_data, value[valid_index]))
valid_l_data = np.hstack((valid_l_data, l_split[index][valid_index]))
test_f_data = np.vstack((test_f_data, value[test_index]))
test_l_data = np.hstack((test_l_data, l_split[index][test_index]))
except ValueError:
train_f_data = value[train_index]
train_l_data = l_split[index][train_index]
valid_f_data = value[valid_index]
valid_l_data = l_split[index][valid_index]
test_f_data = value[test_index]
test_l_data = l_split[index][test_index]
# 如果要建立CNN模型,特征数据需要增加维度
if model == 'cnn':
train_f_data = train_f_data[:, :, :, None] # 增加维度
valid_f_data = valid_f_data[:, :, :, None]
test_f_data = test_f_data[:, :, :, None]
# 训练数据集较少,在这里重复
train_f_data = train_f_data.repeat(5, axis = 0)
train_l_data = train_l_data.repeat(5, axis = 0)
return train_f_data, train_l_data, valid_f_data, valid_l_data, test_f_data, test_l_data
# 分割后的数据集:注意CNN和MLP模型需要不同维度的数据
Tr_f, Tr_l, Va_f, Va_l, Te_f, Te_l = split_data(all_feature_data, all_label_data, model='cnn')
print(Tr_f.shape)
(5580, 20, 16, 1)
1.3 构建数据管道
# 下面就是将特征和标签对应起来,也就是每个(20, 16)对应一个label,并且都转换为张量的形式
# 训练数据集:因为训练数据集较少,重复数据
train_data = tf.data.Dataset.from_tensor_slices((Tr_f, Tr_l))
# 验证数据集
valid_data = tf.data.Dataset.from_tensor_slices((Va_f, Va_l))
# 测试数据集
test_data = tf.data.Dataset.from_tensor_slices((Te_f, Te_l))
# 预测数据集:这里用测试数据集充当预测数据集
predict_data = tf.data.Dataset.from_tensor_slices(Te_f)
train_data
# 可以通过下面的命令,查看前10条数据,因为占用页面,此处不打印结果
# for sa in train_data.take(10):
# print(sa)
1.4 数据管道进入模型
# 需要将数据打乱分组:
# shuffle的数值越大,占用内存越多;数值越小,打乱不充分
train_data_sb = train_data.shuffle(20000).batch(300) # 每200条数据进行乱序,一次批训练的数据条数为32。
valid_data_b = valid_data.batch(16)
test_data_b = test_data.batch(16)
predict_data_b = predict_data.batch(16)
# 代入模型需要数据的维度,通过下面的命令可以得到对应的为维度。
X, Y = next(iter(train_data_sb))
Input_Shape = X.numpy().shape[1:]
print(Input_Shape)
Out_Class = 36 # 总共类别数
(20, 16, 1)
1.5 利用Sequential API建立模型
# Sequential API建立MLP模型
def build_model_mlp(name='python_fan', inputshape=Input_Shape): # name:模型的名称
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=inputshape, name='transpose_1'), # 输入层
tf.keras.layers.Dense(128, name='hidden_layer_1', activation='relu', kernel_regularizer='l2'), # 隐层1,L2正则化防止过拟合
tf.keras.layers.Dense(256, name='hidden_layer_2', activation='relu', kernel_regularizer='l2'), # 隐层2,L2正则化防止过拟合
tf.keras.layers.Dropout(0.2), # 丢弃层,防止过拟合
tf.keras.layers.Dense(Out_Class, name='hidden_layer_3', activation='softmax', kernel_regularizer='l2') # 输出层
], name=name)
model.compile(optimizer=tf.keras.optimizers.Adagrad(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
# Sequential API建立CNN模型
def build_model_cnn(name='python_fan', inputshape=Input_Shape): # name:模型的名称
model = tf.keras.Sequential([
tf.keras.Input(shape=Input_Shape, name='INPUT'),# 输入层
tf.keras.layers.Conv2D(filters=64, kernel_size=[2, 2], activation='relu', name='CONV_1'), # 卷积层
tf.keras.layers.MaxPooling2D(pool_size=[2,2], name='MAXPOOL_1', padding='same'), # 最大池化层
tf.keras.layers.Conv2D(filters=64, kernel_size=[2,2], activation='relu', name='CONV_2'), # 卷积层
tf.keras.layers.MaxPooling2D(pool_size=[2,2], name='MAXPOOL_2', padding='same'), # 最大池化层
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, name='hidden_layer_1', activation='relu', kernel_regularizer='l2'), # 隐层,L2正则化防止过拟合
tf.keras.layers.Dropout(0.32), # 丢弃层,防止过拟合
tf.keras.layers.Dense(Out_Class, name='hidden_layer_2', activation='softmax', kernel_regularizer='l2') # 输出层
], name=name)
model.compile(optimizer=tf.keras.optimizers.Adam(), loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
1.6 模型训练
# 建立CNN模型
model = build_model_cnn('CNN')
# 回调:将训练过程写入到文件夹内,
logpath = os.path.join(r'logs', datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
tensorboard_callback = tf.keras.callbacks.TensorBoard(logpath, histogram_freq=1)
# 回调:动态更改学习率
def scheduler(epoch): # 根据epoch动态更改学习率的参数
if epoch < 20:
return 0.014
else:
return 0.014 * tf.math.exp(0.1 * (20 - epoch))
lr_back = tf.keras.callbacks.LearningRateScheduler(scheduler)
# 回调:保存验证准确度最高的模型
checkpoint_path = "./cp-{val_accuracy:.5f}.h5"
checkpoint_dir = os.path.dirname(checkpoint_path)
# 创建一个回调,保证验证数据集准确率最大,save_weights_only=False,保存整个模型结构+参数
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_weights_only=False, monitor='val_accuracy',
mode='max', verbose=2, save_best_only=True)
# 模型训练
model.fit(train_data_sb, epochs=60, validation_data=valid_data_b, callbacks=[lr_back, tensorboard_callback, cp_callback])
Train for 19 steps, validate for 12 steps
Epoch 1/60
18/19 [===========================>..] - ETA: 0s - loss: 3.6244 - accuracy: 0.1617
Epoch 00001: val_accuracy improved from -inf to 0.50000, saving model to ./cp-0.50000.h5
19/19 [==============================] - 2s 80ms/step - loss: 3.5527 - accuracy: 0.1695 - val_loss: 2.0763 - val_accuracy: 0.5000
Epoch 2/60
18/19 [===========================>..] - ETA: 0s - loss: 1.7845 - accuracy: 0.5991
Epoch 00002: val_accuracy improved from 0.50000 to 0.67222, saving model to ./cp-0.67222.h5
19/19 [==============================] - 1s 61ms/step - loss: 1.7680 - accuracy: 0.6027 - val_loss: 1.6391 - val_accuracy: 0.6722
Epoch 3/60
18/19 [===========================>..] - ETA: 0s - loss: 1.3987 - accuracy: 0.7357
Epoch 00003: val_accuracy improved from 0.67222 to 0.72778, saving model to ./cp-0.72778.h5
19/19 [==============================] - 1s 61ms/step - loss: 1.3936 - accuracy: 0.7371 - val_loss: 1.4415 - val_accuracy: 0.7278
Epoch 4/60
18/19 [===========================>..] - ETA: 0s - loss: 1.2324 - accuracy: 0.7820
Epoch 00004: val_accuracy improved from 0.72778 to 0.73889, saving model to ./cp-0.73889.h5
19/19 [==============================] - 1s 62ms/step - loss: 1.2244 - accuracy: 0.7832 - val_loss: 1.4004 - val_accuracy: 0.7389
Epoch 5/60
18/19 [===========================>..] - ETA: 0s - loss: 1.1701 - accuracy: 0.7894
Epoch 00005: val_accuracy did not improve from 0.73889
19/19 [==============================] - 1s 62ms/step - loss: 1.1650 - accuracy: 0.7912 - val_loss: 1.3218 - val_accuracy: 0.7333
Epoch 6/60
18/19 [===========================>..] - ETA: 0s - loss: 1.1164 - accuracy: 0.8057
Epoch 00006: val_accuracy improved from 0.73889 to 0.74444, saving model to ./cp-0.74444.h5
19/19 [==============================] - 1s 63ms/step - loss: 1.1099 - accuracy: 0.8070 - val_loss: 1.3737 - val_accuracy: 0.7444
Epoch 7/60
18/19 [===========================>..] - ETA: 0s - loss: 1.0259 - accuracy: 0.8259
Epoch 00007: val_accuracy improved from 0.74444 to 0.75000, saving model to ./cp-0.75000.h5
19/19 [==============================] - 1s 65ms/step - loss: 1.0207 - accuracy: 0.8276 - val_loss: 1.3088 - val_accuracy: 0.7500
Epoch 8/60
18/19 [===========================>..] - ETA: 0s - loss: 1.0145 - accuracy: 0.8309
Epoch 00008: val_accuracy improved from 0.75000 to 0.76667, saving model to ./cp-0.76667.h5
19/19 [==============================] - 1s 65ms/step - loss: 1.0141 - accuracy: 0.8321 - val_loss: 1.2784 - val_accuracy: 0.7667
Epoch 9/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9455 - accuracy: 0.8485
Epoch 00009: val_accuracy did not improve from 0.76667
19/19 [==============================] - 1s 65ms/step - loss: 0.9438 - accuracy: 0.8498 - val_loss: 1.3780 - val_accuracy: 0.7278
Epoch 10/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9847 - accuracy: 0.8400
Epoch 00010: val_accuracy did not improve from 0.76667
19/19 [==============================] - 1s 64ms/step - loss: 0.9855 - accuracy: 0.8392 - val_loss: 1.3767 - val_accuracy: 0.7333
Epoch 11/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9586 - accuracy: 0.8474
Epoch 00011: val_accuracy did not improve from 0.76667
19/19 [==============================] - 1s 65ms/step - loss: 0.9560 - accuracy: 0.8486 - val_loss: 1.3936 - val_accuracy: 0.7389
Epoch 12/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9521 - accuracy: 0.8506
Epoch 00012: val_accuracy improved from 0.76667 to 0.78333, saving model to ./cp-0.78333.h5
19/19 [==============================] - 1s 66ms/step - loss: 0.9527 - accuracy: 0.8507 - val_loss: 1.2761 - val_accuracy: 0.7833
Epoch 13/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9223 - accuracy: 0.8609
Epoch 00013: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 66ms/step - loss: 0.9238 - accuracy: 0.8600 - val_loss: 1.3347 - val_accuracy: 0.7389
Epoch 14/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9445 - accuracy: 0.8561
Epoch 00014: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 66ms/step - loss: 0.9468 - accuracy: 0.8565 - val_loss: 1.4882 - val_accuracy: 0.7333
Epoch 15/60
18/19 [===========================>..] - ETA: 0s - loss: 0.9499 - accuracy: 0.8544
Epoch 00015: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 61ms/step - loss: 0.9435 - accuracy: 0.8554 - val_loss: 1.1857 - val_accuracy: 0.7667
Epoch 16/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8447 - accuracy: 0.8820
Epoch 00016: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 62ms/step - loss: 0.8391 - accuracy: 0.8833 - val_loss: 1.2364 - val_accuracy: 0.7500
Epoch 17/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8382 - accuracy: 0.8765
Epoch 00017: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 62ms/step - loss: 0.8435 - accuracy: 0.8754 - val_loss: 1.3252 - val_accuracy: 0.7500
Epoch 18/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8648 - accuracy: 0.8728
Epoch 00018: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 61ms/step - loss: 0.8672 - accuracy: 0.8720 - val_loss: 1.3173 - val_accuracy: 0.7778
Epoch 19/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8573 - accuracy: 0.8741
Epoch 00019: val_accuracy did not improve from 0.78333
19/19 [==============================] - 1s 62ms/step - loss: 0.8528 - accuracy: 0.8753 - val_loss: 1.3552 - val_accuracy: 0.7778
Epoch 20/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8386 - accuracy: 0.8776
Epoch 00020: val_accuracy improved from 0.78333 to 0.80000, saving model to ./cp-0.80000.h5
19/19 [==============================] - 1s 64ms/step - loss: 0.8399 - accuracy: 0.8769 - val_loss: 1.2265 - val_accuracy: 0.8000
Epoch 21/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8473 - accuracy: 0.8748
Epoch 00021: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 63ms/step - loss: 0.8529 - accuracy: 0.8740 - val_loss: 1.3491 - val_accuracy: 0.7667
Epoch 22/60
18/19 [===========================>..] - ETA: 0s - loss: 0.8584 - accuracy: 0.8783
Epoch 00022: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 60ms/step - loss: 0.8537 - accuracy: 0.8792 - val_loss: 1.2209 - val_accuracy: 0.7667
Epoch 23/60
18/19 [===========================>..] - ETA: 0s - loss: 0.7589 - accuracy: 0.8980
Epoch 00023: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 59ms/step - loss: 0.7570 - accuracy: 0.8989 - val_loss: 1.2823 - val_accuracy: 0.7556
Epoch 24/60
18/19 [===========================>..] - ETA: 0s - loss: 0.6979 - accuracy: 0.9024
Epoch 00024: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 60ms/step - loss: 0.6953 - accuracy: 0.9027 - val_loss: 1.1602 - val_accuracy: 0.7889
Epoch 25/60
18/19 [===========================>..] - ETA: 0s - loss: 0.6537 - accuracy: 0.9072
Epoch 00025: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 60ms/step - loss: 0.6460 - accuracy: 0.9090 - val_loss: 1.0746 - val_accuracy: 0.8000
Epoch 26/60
18/19 [===========================>..] - ETA: 0s - loss: 0.5712 - accuracy: 0.9215
Epoch 00026: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 61ms/step - loss: 0.5695 - accuracy: 0.9208 - val_loss: 1.1858 - val_accuracy: 0.7722
Epoch 27/60
18/19 [===========================>..] - ETA: 0s - loss: 0.5387 - accuracy: 0.9239
Epoch 00027: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 62ms/step - loss: 0.5380 - accuracy: 0.9240 - val_loss: 1.0416 - val_accuracy: 0.7722
Epoch 28/60
18/19 [===========================>..] - ETA: 0s - loss: 0.5083 - accuracy: 0.9293
Epoch 00028: val_accuracy did not improve from 0.80000
19/19 [==============================] - 1s 69ms/step - loss: 0.5101 - accuracy: 0.9287 - val_loss: 0.9900 - val_accuracy: 0.7889
Epoch 29/60
18/19 [===========================>..] - ETA: 0s - loss: 0.4777 - accuracy: 0.9309
Epoch 00029: val_accuracy improved from 0.80000 to 0.80556, saving model to ./cp-0.80556.h5
19/19 [==============================] - 1s 62ms/step - loss: 0.4784 - accuracy: 0.9310 - val_loss: 0.9777 - val_accuracy: 0.8056
Epoch 30/60
18/19 [===========================>..] - ETA: 0s - loss: 0.4372 - accuracy: 0.9369
Epoch 00030: val_accuracy did not improve from 0.80556
19/19 [==============================] - 1s 61ms/step - loss: 0.4358 - accuracy: 0.9376 - val_loss: 1.0587 - val_accuracy: 0.8056
Epoch 31/60
18/19 [===========================>..] - ETA: 0s - loss: 0.4231 - accuracy: 0.9391
Epoch 00031: val_accuracy did not improve from 0.80556
19/19 [==============================] - 1s 62ms/step - loss: 0.4251 - accuracy: 0.9384 - val_loss: 1.0058 - val_accuracy: 0.8056
Epoch 32/60
18/19 [===========================>..] - ETA: 0s - loss: 0.4034 - accuracy: 0.9400
Epoch 00032: val_accuracy improved from 0.80556 to 0.82222, saving model to ./cp-0.82222.h5
19/19 [==============================] - 1s 63ms/step - loss: 0.4024 - accuracy: 0.9405 - val_loss: 0.9511 - val_accuracy: 0.8222
Epoch 33/60
18/19 [===========================>..] - ETA: 0s - loss: 0.3692 - accuracy: 0.9511
Epoch 00033: val_accuracy did not improve from 0.82222
19/19 [==============================] - 1s 63ms/step - loss: 0.3675 - accuracy: 0.9514 - val_loss: 0.9566 - val_accuracy: 0.8000
Epoch 34/60
18/19 [===========================>..] - ETA: 0s - loss: 0.3605 - accuracy: 0.9480
Epoch 00034: val_accuracy did not improve from 0.82222
19/19 [==============================] - 1s 63ms/step - loss: 0.3606 - accuracy: 0.9478 - val_loss: 0.8465 - val_accuracy: 0.8167
Epoch 35/60
18/19 [===========================>..] - ETA: 0s - loss: 0.3491 - accuracy: 0.9478
Epoch 00035: val_accuracy improved from 0.82222 to 0.85000, saving model to ./cp-0.85000.h5
19/19 [==============================] - 1s 64ms/step - loss: 0.3481 - accuracy: 0.9482 - val_loss: 0.8236 - val_accuracy: 0.8500
Epoch 36/60
18/19 [===========================>..] - ETA: 0s - loss: 0.3329 - accuracy: 0.9554
Epoch 00036: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 63ms/step - loss: 0.3320 - accuracy: 0.9552 - val_loss: 0.7899 - val_accuracy: 0.7833
Epoch 37/60
18/19 [===========================>..] - ETA: 0s - loss: 0.3177 - accuracy: 0.9567
Epoch 00037: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 62ms/step - loss: 0.3155 - accuracy: 0.9577 - val_loss: 0.8691 - val_accuracy: 0.7944
Epoch 38/60
18/19 [===========================>..] - ETA: 0s - loss: 0.3077 - accuracy: 0.9563
Epoch 00038: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 60ms/step - loss: 0.3088 - accuracy: 0.9563 - val_loss: 0.7664 - val_accuracy: 0.8278
Epoch 39/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2960 - accuracy: 0.9580
Epoch 00039: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 60ms/step - loss: 0.2973 - accuracy: 0.9568 - val_loss: 0.8596 - val_accuracy: 0.8056
Epoch 40/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2903 - accuracy: 0.9633
Epoch 00040: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 60ms/step - loss: 0.2889 - accuracy: 0.9636 - val_loss: 0.8093 - val_accuracy: 0.8111
Epoch 41/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2875 - accuracy: 0.9578
Epoch 00041: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 62ms/step - loss: 0.2899 - accuracy: 0.9565 - val_loss: 0.8206 - val_accuracy: 0.8111
Epoch 42/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2683 - accuracy: 0.9630
Epoch 00042: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 63ms/step - loss: 0.2685 - accuracy: 0.9633 - val_loss: 0.8158 - val_accuracy: 0.7944
Epoch 43/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2578 - accuracy: 0.9656
Epoch 00043: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 62ms/step - loss: 0.2589 - accuracy: 0.9652 - val_loss: 0.8022 - val_accuracy: 0.8111
Epoch 44/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2603 - accuracy: 0.9617
Epoch 00044: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 63ms/step - loss: 0.2603 - accuracy: 0.9618 - val_loss: 0.8134 - val_accuracy: 0.7889
Epoch 45/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2548 - accuracy: 0.9641
Epoch 00045: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2544 - accuracy: 0.9640 - val_loss: 0.7731 - val_accuracy: 0.8056
Epoch 46/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2441 - accuracy: 0.9672
Epoch 00046: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 65ms/step - loss: 0.2454 - accuracy: 0.9672 - val_loss: 0.7958 - val_accuracy: 0.8111
Epoch 47/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2445 - accuracy: 0.9667
Epoch 00047: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 65ms/step - loss: 0.2427 - accuracy: 0.9672 - val_loss: 0.7751 - val_accuracy: 0.8278
Epoch 48/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2377 - accuracy: 0.9663
Epoch 00048: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 65ms/step - loss: 0.2384 - accuracy: 0.9658 - val_loss: 0.7562 - val_accuracy: 0.8333
Epoch 49/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2378 - accuracy: 0.9670
Epoch 00049: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2371 - accuracy: 0.9667 - val_loss: 0.7627 - val_accuracy: 0.8278
Epoch 50/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2324 - accuracy: 0.9694
Epoch 00050: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 65ms/step - loss: 0.2316 - accuracy: 0.9699 - val_loss: 0.7689 - val_accuracy: 0.8222
Epoch 51/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2309 - accuracy: 0.9667
Epoch 00051: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 65ms/step - loss: 0.2305 - accuracy: 0.9668 - val_loss: 0.7629 - val_accuracy: 0.8222
Epoch 52/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2262 - accuracy: 0.9715
Epoch 00052: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2261 - accuracy: 0.9715 - val_loss: 0.7631 - val_accuracy: 0.8333
Epoch 53/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2234 - accuracy: 0.9693
Epoch 00053: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2238 - accuracy: 0.9690 - val_loss: 0.7546 - val_accuracy: 0.8278
Epoch 54/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2185 - accuracy: 0.9687
Epoch 00054: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2187 - accuracy: 0.9688 - val_loss: 0.7502 - val_accuracy: 0.8389
Epoch 55/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2182 - accuracy: 0.9709
Epoch 00055: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 65ms/step - loss: 0.2178 - accuracy: 0.9706 - val_loss: 0.7553 - val_accuracy: 0.8333
Epoch 56/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2220 - accuracy: 0.9698
Epoch 00056: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2216 - accuracy: 0.9695 - val_loss: 0.7473 - val_accuracy: 0.8333
Epoch 57/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2169 - accuracy: 0.9691
Epoch 00057: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 66ms/step - loss: 0.2172 - accuracy: 0.9688 - val_loss: 0.7531 - val_accuracy: 0.8278
Epoch 58/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2142 - accuracy: 0.9706
Epoch 00058: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 60ms/step - loss: 0.2140 - accuracy: 0.9708 - val_loss: 0.7677 - val_accuracy: 0.8167
Epoch 59/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2138 - accuracy: 0.9719
Epoch 00059: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 61ms/step - loss: 0.2148 - accuracy: 0.9713 - val_loss: 0.7610 - val_accuracy: 0.8111
Epoch 60/60
18/19 [===========================>..] - ETA: 0s - loss: 0.2160 - accuracy: 0.9683
Epoch 00060: val_accuracy did not improve from 0.85000
19/19 [==============================] - 1s 61ms/step - loss: 0.2155 - accuracy: 0.9685 - val_loss: 0.7441 - val_accuracy: 0.8222
# 加载最好的模型:最好的模型可通过上面的输出得到“val_accuracy did not improve from 0.850000”。所以文件名就是cp-0.85000.h5
best_model = tf.keras.models.load_model('cp-0.85000.h5')
# 模型评估
best_model.evaluate(test_data_b)
7/7 [==============================] - 0s 15ms/step - loss: 0.7648 - accuracy: 0.8056
[0.7648465377943856, 0.8055556]
1.7 TensorBoard 训练过程可视化
在保存本ipynb的路径中,可以找到刚才指定的文件夹,选中该文件夹,上面会出现tensorboard。点击即可跳转到相应的页面。
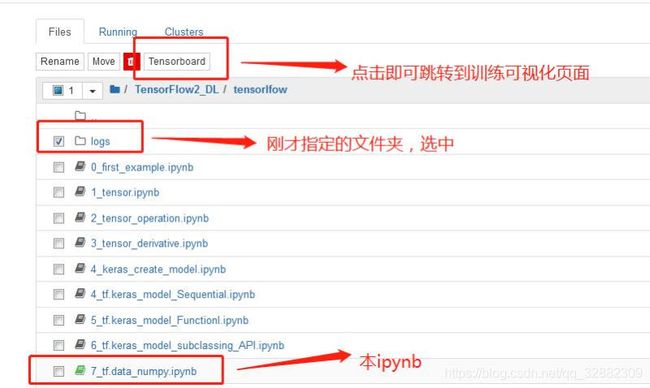
- 查看精确度与成本

- 查看学习率

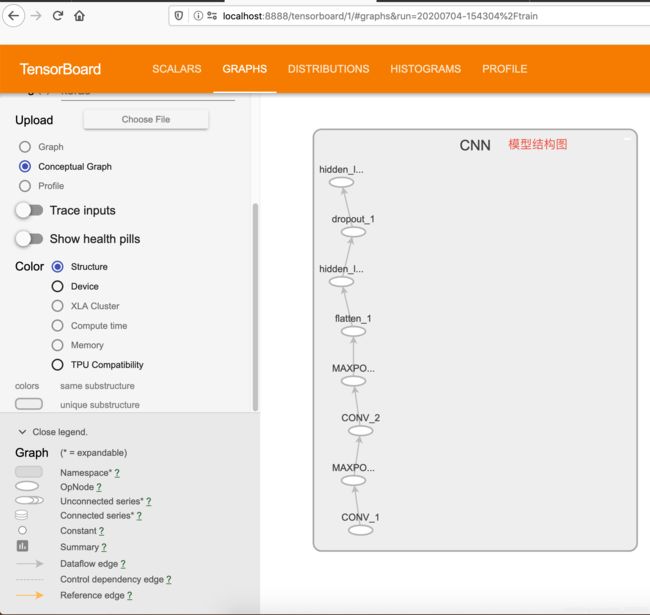
- 查看模型构造
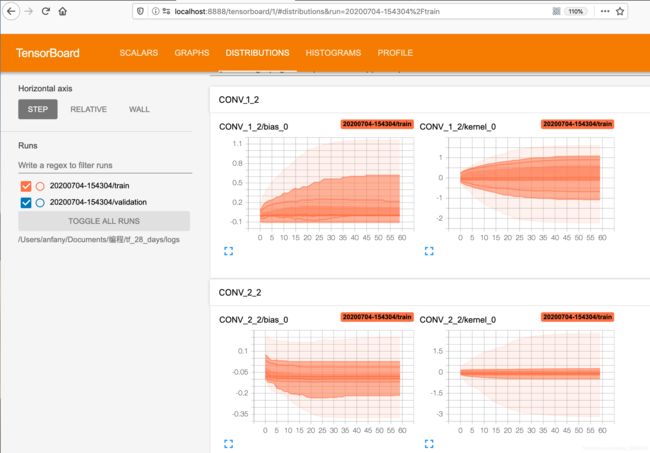
- 查看参数分布
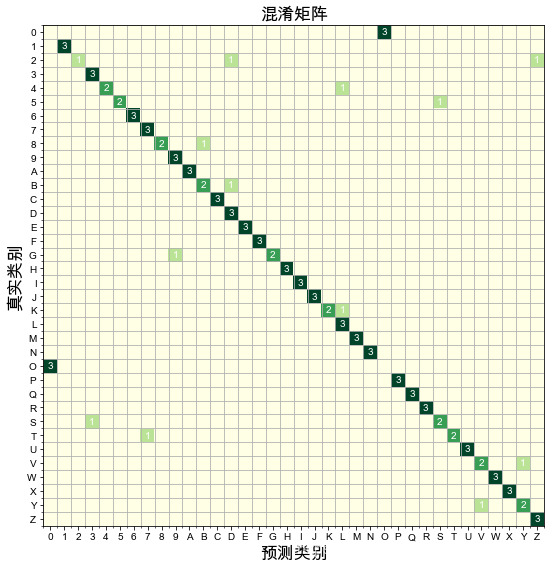
1.8 结果展示
# 模型预测
result = model.predict(predict_data_b)
# 模型预测的类别
class_result = tf.argmax(result, axis=1).numpy()
# 输出混淆矩阵:根据真实类别列表、预测类别列表、数字与类别的对应字典
from matplotlib.ticker import MultipleLocator
def plot_confusion_matrix(realclass, predictclass, classdigdict, classcount=36):
con_mat = tf.math.confusion_matrix(realclass, predictclass, num_classes=classcount).numpy()
class_sign = [classdigdict[k] for k in range(classcount)]
fig, ax = plt.subplots(figsize=(8, 8))
im = ax.imshow(con_mat,cmap="YlGn")
ax.set_xticks(np.arange(len(class_sign)))
ax.set_yticks(np.arange(len(class_sign)))
ax.set_xticklabels(class_sign)
ax.set_yticklabels(class_sign)
ax.set_ylabel('真实类别', fontsize=17)
ax.set_xlabel('预测类别', fontsize=17)
xminorLocator = MultipleLocator(.5)
yminorLocator = MultipleLocator(.5)
for i in range(classcount):
for j in range(classcount):
if con_mat[i, j]:
ax.text(j, i, con_mat[i, j], ha="center", va="center", color="w")
ax.set_title('混淆矩阵', fontsize=17)
ax.xaxis.set_minor_locator(xminorLocator)
ax.yaxis.set_minor_locator(yminorLocator)
ax.xaxis.grid(True, which='minor')
ax.yaxis.grid(True, which='minor')
fig.tight_layout()
plt.show()
plot_confusion_matrix(Te_l, class_result, Label_Dict)
 点击获得更多项目源码。欢迎Follow,感谢Star!!! 扫描关注微信公众号pythonfan,获取更多。
点击获得更多项目源码。欢迎Follow,感谢Star!!! 扫描关注微信公众号pythonfan,获取更多。

