Zeppelin-安装及使用
Contents:
- Zeppelin简介
- Zeppelin简介Zeppelin编译安装
- Zeppelin案例
- Zeppelin和shell整合
- Zeppelin和JDBC(Hive)整合
- Zeppelin和Spark整合
一、What is Zeppelin?
1)官 网:http://zeppelin.apache.org/
2)帮助文档:http://zeppelin.apache.org/docs/0.6.2/
https://github.com/apache/zeppelin/blob/master/README.md
Zeppelin是一个基于Web的notebook,提供交互数据分析和可视化。后台支持接入多种数据处理引擎,如spark,hive等。支持多种语言: Scala(Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等。本文主要介绍Zeppelin中Interpreter和SparkInterpreter的实现原理。
原理简介
Interpreter
Zeppelin中最核心的概念是Interpreter,interpreter是一个插件允许用户使用一个指定的语言或数据处理器。每一个Interpreter都属于换一个InterpreterGroup,同一个InterpreterGroup的Interpreters可以相互引用,例如SparkSqlInterpreter 可以引用 SparkInterpreter 以获取 SparkContext,因为他们属于同一个InterpreterGroup。当前已经实现的Interpreter有spark解释器,python解释器,SparkSQL解释器,JDBC,Markdown和shell等。下图是Zeppelin官网中介绍Interpreter的原理图。
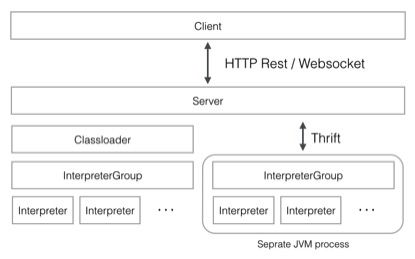
Interpreter接口中最重要的方法是open,close,interpert三个方法,另外还有cancel,gerProgress,completion等方法。
Open 是初始化部分,只会调用一次。 Close 是关闭释放资源的接口,只会调用一次。 Interpret 会运行一段代码并返回结果,同步执行方式。 Cancel可选的接口,用于结束interpret方法 getPregress 方法获取interpret的百分比进度 completion 基于游标位置获取结束列表,实现这个接口可以实现自动结束
二、 Zeppelin安装
下载软件:
1)下载地址1:http://zeppelin.apache.org/download.html
2)下载地址2:http://archive.apache.org/dist/zeppelin/
3)下载地址3:https://github.com/apache/zeppelin
环境要求 :
Zeppelin版本选择: zeppelin-0.8.0
操作系统:Centos6.x版本
JDK:jdk1.8.0_161
CDH安装zeppelin-0.8.0
在下载地址1,下载zeppelin-0.8.0-bin-all.tgz 上传服务器,解压tar -zxvf zeppelin-0.8.0-bin-all.tgz
cd zeppelin-0.8.0-bin-all/conf/
cp zeppelin-env.sh.template zeppelin-env.sh
cp zeppelin-site.xml.template zeppelin-site.xml
注:此处的大数据集群为CM管理
配置zeppelin环境vim zeppelin-env.sh
export HIVE_HOME=/opt/cloudera/parcels/CDH-5.11.1-1.cdh5.11.1.p0.4/lib/hive
export JAVA_HOME=/usr/java/jdk1.8.0_161
export MASTER=local[*]
export ZEPPELIN_JAVA_OPTS="-Dmaster=yarn-client -Dspark.yarn.jar=/home/zepplin/zeppelin-0.8.0-bin-all/interpreter/spark/spark-interpreter-0.8.0.jar"
export DEFAULT_HADOOP_HOME=/opt/cloudera/parcels/CDH-5.11.1-1.cdh5.11.1.p0.4/lib/hadoop
export SPARK_HOME=/opt/cloudera/parcels/SPARK2/lib/spark2
export HADOOP_HOME=${HADOOP_HOME:-$DEFAULT_HADOOP_HOME}
if [ -n "$HADOOP_HOME" ]; then
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HADOOP_HOME}/lib/native
fi
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-/etc/hadoop/conf}
配置zeppelin端口vim zeppelin-site.xml
#value为端口,自定义配置
配置完成。cd zeppelin-0.8.0-bin-all/bin/
./zeppelin-daemon.sh start
访问:http://YourIp:38099
三、 Zeppelin案列
1)Zeppelin和shell整合
zeppelin默认环境就是shell
测试:
2)Zeppelin和JDBC(Hive)整合
cp mysql-connector-java-5.1.35-bin.jar zeppelin/zeppelin-0.8.0-bin-all/interpreter/jdbc/
连接mysql配置:
测试:
连接hive测试:
cp hive-jdbc-1.1.0-cdh5.11.1.jar zeppelin/zeppelin-0.8.0-bin-all/interpreter/jdbc/
cp hive-service-1.1.0-cdh5.11.1.jar zeppelin/zeppelin-0.8.0-bin-all/interpreter/jdbc/
cp hive-common-1.1.0-cdh5.11.1.jar zeppelin/zeppelin-0.8.0-bin-all/interpreter/jdbc/
cp hadoop-common-2.6.0-cdh5.11.1.jar zeppelin/zeppelin-0.8.0-bin-all/interpreter/jdbc/

测试:
3)Zeppelin和Spark整合
运行自带的spark项目: