字节-面经1
乐观锁和悲观锁的区别?说一下使用场景
乐观锁:总是假设是最好的场景,即获取数据时没有别人来修改数据,只有在更新数据时会检查是否数据被修改了
悲观锁:总是假设最坏的场景,即获取数据时与更新数据时总有别人在更改数据所以每次操作都要上锁
使用场景:乐观锁:CAS,原子类,数据库版本号,时间戳 悲观锁:synchronized,reentrantLock
数据库版本号:通过为数据表增加一个数字类型的version字段来实现,当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一,当我们提交更新时,判断数据表对应记录的当前版本信息与第一次取出来的version是否相等,相等则更新,否则版本冲突
时间戳:在乐观锁控制的table中增加一个字段,每次更新时检查数据库中数据的时间戳和自己更新前取得的时间戳是否一致,一致则更新,否则冲突
如果某一时刻大量的缓存失效,有大量的请求落到数据库上,怎么处理?
这就是缓存雪崩,缓存雪崩的解决方案:
1.加锁或者用队列的方式保证缓存的单线程写,从而避免失效时大量的并发请求落到底层存储系统上
2.将缓存失效时间分散开,随机设置缓存过期时间
3.建立备份缓存,缓存A和缓存B,A设置超时时间,B不设置,先从A读,没则去B读,并且更新A缓存和B缓存
讲一下分布式锁,如何实现
分布式锁和传统锁不同,它表示多个进程或线程运行在不同的机器上。产生原因就是因为分布式系统下的多个服务器,多个数据库。
实现方式:
1.基于数据库表
2.使用redis的setnx,expire()方法
3.使用ZooKeeper
更新数据时先更新redis还是mysql?
分情况
1.先删除缓存再更新数据库
这种情况下产生脏数据的概率较大
因为假如先删除缓存,查询操作没有命中缓存,这个时候会去访问数据库,于是先把老数据读出来再放到缓存中,然后更新了数据库,于是,缓存中的是老数据,这样的话这个数据就是脏数据,而且一直脏下去
2.先更新数据库,再删除缓存(推荐这种)
这种情况下产生脏数据概率小,但是会出现一致性问题,假如更新操作的时候,同时进行查询操作,如果命中,则查询到的是旧的数据,但是不会影响到后面的查询(代价小)
写个单例模式懒加载,并解释
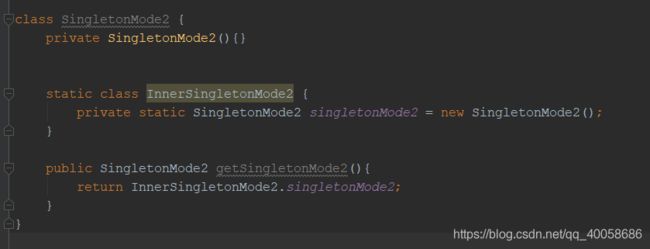
采用的是静态内部类的方式来实现的懒加载。这样的话只有在真正用到该静态内部类时,才会进行初始化,而且静态类的初始化只会进行一次。当然,还可以通过双重校验锁的方式来实现,不过要把那个变量设置为volatile的,或者采取枚举的方式
volatile关键字,底层怎么实现的知道吗
volatile是通过lock指令实现的。
lock指令有两个效果
1:将数据从缓存写回到系统内存
2:写到到系统内存会导致其他缓存该内存地址的数据无效,如果想要再获取最新值时要重新从系统内存中读取
正是这两个事件,使得volatile保证了可见性
讲一下拥塞控制?
拥塞控制是为了防止过多的数据注入到网络中,这样可以使得网络中的路由器或者链路不至于过载
前提:网络能够承受现有的网络符合
与流量控制的区别:拥塞控制是一个全局性的过程,涉及到所有主机,路由器
代价:需要获得网络内部流量分布的信息。还需要将一些资源分配给各个用户单独使用
拥塞控制的几种方法:慢开始 拥塞避免 快重传 快恢复
ioc原理
ioc就是控制反转将控制权由应用代码移到了spring容器,由容器来负责bean的实例化,初始化,配置依赖,核心接口就是BeanFactory
线程池了解吗?
了解,好处是降低资源消耗,提高响应速度,提高线程的可管理性
工作原理是先判断核心线程池是否满了,没满的话会新起一个核心线程,如果核心线程满了,则会放入工作队列中,如果工作队列也满了就会放入线程池中,线程池满了就进行饱和策略处理,这里面第一步,第三步都需要获取全局锁,所以耗时,我们大多数情况下需要进行第二步
线程池类型分为newCacheThreadPool,newFixedThreadPool,newScheduleThreadPool,newSingleThreadPool.
饱和策略有抛弃队列中最近的任务,直接抛出异常,不处理直接丢弃
阻塞队列分为ArrayBlockingQueue,LinkedBlockingQueue,SynchronousQueue,PriorityBlockingQueue
介绍一下垃圾回收机制和算法。
根据对象所处的分代的不同,会进行不同的收集算法,假如是在新生代,则是用的复制算法,假如是老年代,则是用的标记清除算法。复制算法一次只会用一个Survivor区,另一边不会使用,标记清除算法则是初始标记,并发标记,重复标记,并发清除,其中初始标记和重复标记不是并发进行的,不过耗时远远小于并发标记,所以总体上来看是并发的。
为什么垃圾回收回收的是堆,不用回收栈里面的
因为栈里面的对象的生命周期和栈同步,随着线程的销毁而销毁,所以他们占用的内存会自动释放,所以只有方法区和堆需要进行GC
垃圾回收的种类了解吗?
了解,Serial,ParNew,parallel scanvage,CMS,Serial old,parallel old,G1
内存泄漏的例子
Vector容器类,还有数据库连接,网络连接和IO操作如果不主动调用close()方法就会导致内存泄漏
原因就是长生命周期的对象持有了短生命周期的引用导致短生命周期对象无法被垃圾回收
单例模式也会导致内存泄漏,因为很多时候我们将它的生命周期看做和整个程序的生命周期差不多了,如果这个对象持有一些其他对象的引用,很容易发生内存泄漏
内部类和外部模块的引用
HashMap和LinkedHashMap的区别
LinkedHashMap也是一个HashMap,不过内部维持的是一个双向链表,可以保持顺序,而hashMap内部是无序的
有哪些线程安全的类
HashTable,ConcurrentHashMap,StringBuffer
为什么说HashTable是线程安全的
因为HashTable的方法使用了synchronized,保证了线程安全
HashMap底层原理
HashMap是基于hashing原理实现的,它的put和get方法用来存储键值对,put方法会根据键得到一个hashcode,然后找到对应的bucket,将键值对存放上去,假如hash冲突了,该bucket会成为一个链表,然后放在该链表的下一个节点,当get时,会先去通过键的hashcode找到bucket,然后调用equals方法找到对应的键值对,取出该键值对。hashMap还有一个最大负载因子,当超过该负载因子的时候,会进行扩容也就是再哈希。再哈希的过程会对所有元素重新进行排序并且插入到新的数组中,这里也是从头部插入
有一个List
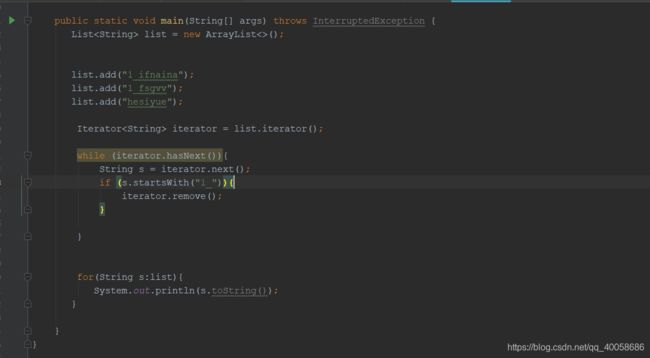
迭代器删除
有一个整数数组 7,4,2,9,3,6,11,10
求:第一个间断的数 5
(间断数:比如上一个例子中出现了2,3,4,6,7,9,10,11),那么5就是第一个间断数
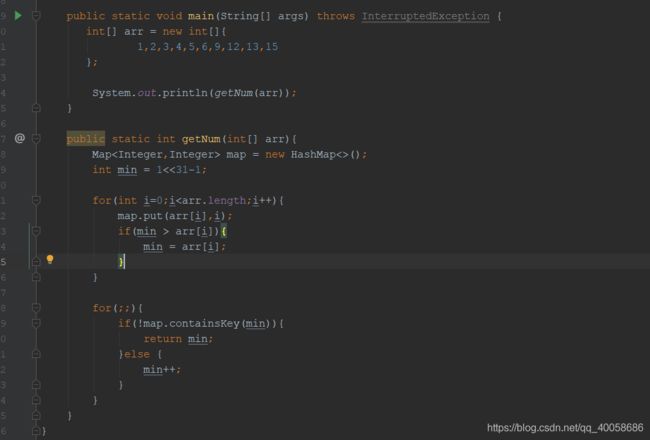
要求:时间复杂度:o(N),空间复杂度尽可能小