centos7 部署知乎热榜爬虫
一、简介
从 centos安装 开始部署 scrapy 云爬虫项目。
这个项目是想分析热榜规律来预测一些~~~
但是和我合作的另外一位同学没有数据库基础,于是我将数据全部实时导出为csv文件,登录XFTP即可看到。最终效果:
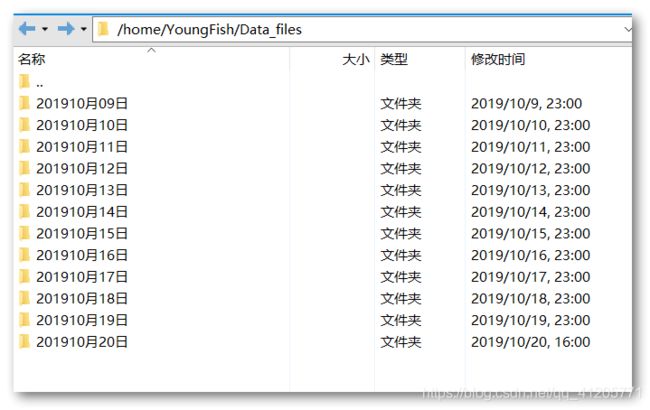
爬虫每五分钟爬取一次数据,连续运行一周也不会被反爬虫处理。非常适合学习数据分析的同学。

爬取的数据分别为:
标题,问题类型,创建时间,更新时间,回答数,访问量,评论数,关注数,问题标签,提问者,提问者id,提问者是否为组织,回答赞同总数,回答评论总数,排名,标签,链接,封面链接,热度,热榜领域,问题编辑日志。

二、环境配置
1、系统版本:
Centos 7.6.64

2、python3 替换 python2
现在python要学就学最新版本,python2很多库都不支持
yum install openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel libffi-devel
tar -zxvf Python-3.7.4.tgz
cd Python-3.7.4
./configure
make && make install
mv /user/bin/pip /user/bin/pip2
ln -s /usr/local/bin/pip3 /usr/bin/pip
mv /usr/bin/python /usr/bin/python2
ln -s /usr/local/bin/python3 /usr/bin/python
3、修改镜像源
用清华镜像源,下载速度快快的
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
4、配置virtualenv
pip install virtualenvwrapper
在.bashrc 后添加两行
export WORKON_HOME=$HOME/.virtualenvs
source /usr/local/bin/virtualenvwrapper.sh
执行
Source ~/.bashrc
创建虚拟运行环境
mkvirtualenv dw01
workon dw01
5、yum配置
替换完python2后,yum便不能使用了,此时需要需改两个文件就可以。具体哪两个我忘了,可以将yum报的错百度一下,能搜索到结果。
三、代码
代码我写了详细的注释,包括每个文件的注释。
1、日志函数
function.py
# 此文件和主爬虫应该在同一目录下
# 自定义功能函数
import time,os,sys,clipboard
from theConf import Config
class writeLog():
'这个类按行写入日志,只需要传入日志名即可,自动补充输出时间'
def __init__(self,csvName):
self.csvName=csvName
if Config.saveLog == True:
theDate = time.strftime('%Y_%m_%d')
self.logDir = os.path.join(Config.Log_Dir, theDate) # 日志存储位置
self.logPath = os.path.join(self.logDir, time.strftime('%H%M%S') + '_' + csvName + '.csv') # 日志名.csv
self.info = '时间,消息\n' # 日志标题
if not os.path.isdir(self.logDir): os.makedirs(self.logDir)
self.plog = self.printlog
self.save = self.savelog
else:
self.plog = self.dontplog
self.save = self.dontsave
self.writefile=self.dontwritefile
# 打印日志
def printlog(self,str,act=None):
thetime=time.strftime('%H:%M:%S')
print(thetime,str)
if ',' in str:
str='"'+str+'"'
self.info=self.info+thetime+","+str+"\n" # 时间,消息
if act=='exit':
self.save()
sys.exit()
if act=='over':
self.save()
# 存储日志
def savelog(self):
'存储日志'
with open(self.logPath,'w',encoding='utf-8-sig')as fp:
fp.write(self.info)
print(80*"*")
print(self.csvName+"写入完成!")
print("日志位置:"+self.logPath)
print(80*"*")
# 写入文件
def writefile(self,filename,text,encoding='utf-8',act=None):
filePath=os.path.join(self.logDir,filename)
with open(filePath,'w',encoding=encoding)as fp:
fp.write(text)
self.plog(80*"*")
self.plog(filename+"写入完成!")
self.plog("写入位置:"+filePath)
self.plog(80*"*")
if act=='copy':
clipboard.copy(text)
# 不保存日志
def dontwritefile(self,*args,**kwargs):
print(80*"*")
print("你的操作无法完成而被退出,失败原因:拒绝保存日志")
print("修改建议:打开 theConf.py 文件,修改 saveLog = True")
print(80*"*")
sys.exit()
def dontsave(self):
print(80 * "*")
print("无需保存日志")
print("关于保存日志的建议:打开 theConf.py 文件,修改 saveLog = True")
print(80 * "*")
def dontplog(self,str,*args,**kwargs):
print(str)
# 醒目输出
def eyeprint(self,str):
'调试代码时,在控制台输出很明显的3行'
print(80*"&")
print(str)
print(80*"&")
class writetxt():
'这个类按行导入文本,如果想写入日志必须传入writelog对象[wlog]'
def __init__(self, txtName, theDir,wLog=None):
self.textName=txtName
self.theDir=theDir
if not os.path.isdir(self.theDir): os.makedirs(self.theDir)
self.txt=''
self.wLog=wLog
def wline(self,str):
'自动补充换行符'
self.txt=self.txt+str+'\n'
def save(self):
'存储文本并打印消息'
self.path=os.path.join(self.theDir,self.textName+'.txt')
with open(self.path,'w',encoding='utf-8')as fp:
fp.write(self.txt)
if self.wLog != None:
self.wLog.plog(80*"*")
self.wLog.plog(self.textName+" 写入完成!")
self.wLog.plog("写入位置:"+self.path)
self.wLog.plog(80*"*")
2、自动登录
主要在windows下写的。
login.py
# 此文件和主爬虫应该在同一目录下
import os,function,time,json,requests,re
from selenium.webdriver import Chrome,ChromeOptions
from theConf import Config
class Login():
zhihu_url="https://www.zhihu.com/"
def __init__(self):
self.W=function.writeLog(Config.loginLog)
self.retryCount=0
def checkLogin(self):
'检查是否可以直接登录'
if Config.produCookie:
self.W.plog("请求登录中...")
self.sele_login()
# 检查Cookies是否存在
if not os.path.exists(Config.Cookie_Path):
self.W.plog("cookies不存在,正在重新登录...")
self.sele_login()
# 检查Cookies是否可用
cookies_jar = self.__parseCookie(Config.Cookie_Path)
with open(Config.Cookie_Path,'r')as fp:
cookies=json.load(fp)
for cookie in cookies:
cookies_jar.set(cookie['name'],cookie['value'],domain=cookie['domain'],path=cookie['path'])
response=requests.get(url=self.zhihu_url,headers=Config.DEFAULT_REQUEST_HEADERS,cookies=cookies_jar)
if response.url!=self.zhihu_url:
self.W.plog("Cookies失效!登录失败!")
self.W.plog("重新获取Cookies...")
self.sele_login()
self.W.plog("登录成功!",act="over")
return self.cookies
def __parseCookie(self,Cookie_Path):
'从文件解析Cookies,文件必须存在'
self.cookies_jar = requests.cookies.RequestsCookieJar()
with open(Cookie_Path,'r')as fp:
self.cookies=json.load(fp)
for cookie in self.cookies:
self.cookies_jar.set(cookie['name'],cookie['value'],domain=cookie['domain'],path=cookie['path'])
return self.cookies_jar
def sele_login(self):
'首次登录知乎,需要一个账户和密码'
# 增加浏览器扩展防止爬虫检测
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
# 登录模拟
driver.get(self.zhihu_url)
driver.find_element_by_xpath("//div[@class='SignFlow-tab']").click()
driver.find_element_by_name("username").send_keys(Config.theName)
driver.find_element_by_name("password").send_keys(Config.thePwd)
submitBtn = driver.find_element_by_xpath("//button[@type='submit']")
submitBtn.click()
time.sleep(Config.waitDefaultTime)
# 检查/保存/重试 cookies
cookies = driver.get_cookies()
current_url=driver.current_url
driver.close()
if current_url == self.zhihu_url:
if not os.path.isdir(Config.Conf_Dir):os.makedirs(Config.Conf_Dir)
with open(Config.Cookie_Path, 'w')as fp:
json.dump(cookies, fp)
else:
if Config.retryLogin==True and self.retryCount<Config.retryMax:
self.retryCount+=1
self.W.plog("登录失败,自动重试第"+str(self.retryCount)+"次...")
self.sele_login()
else:self.W.plog("登录失败,请检查账号密码或手动登录验证后重试!",act='exit')
3、启动爬虫
start.py
from scrapy import cmdline
cmdline.execute("scrapy crawl zhihu".split())
4、配置文件
这个里面的数据库相关的可以不用管,因为导出的是csv,没有用到mysql,我写了许多有关知乎的其他爬虫,他们都共用一个配置文件和登录文件,所以有这些不同的代码。
部署到服务器时,建议修改 DataDir
theConf.py
# 此文件和主爬虫应该在同一目录下
# 整个程序必须要处于可登录的状态,否则无法解析 启动URL
import os
class Config():
# 启动URL
theStart='https://www.zhihu.com/'
# 启动dict
theList={
'全站':'https://www.zhihu.com/hot',
'科学':'https://www.zhihu.com/hot?list=science',
'数码':'https://www.zhihu.com/hot?list=digital',
'体育':'https://www.zhihu.com/hot?list=sport',
'时尚':'https://www.zhihu.com/hot?list=fashion',
'影视':'https://www.zhihu.com/hot?list=film',
'汽车':'https://www.zhihu.com/hot?list=car',
'校园':'https://www.zhihu.com/hot?list=school',
'焦点':'https://www.zhihu.com/hot?list=focus',
'深度':'https://www.zhihu.com/hot?list=depth',
}
# 重要
theName='????????' # 用户名
thePwd='????????' # 密码
# 关键设置
hotToPDF=True # 热榜转PDF, 没有屁用的功能,默认关闭,无效
hotToHtml=True # 热榜转多个HTML, 默认打开,无效
# 存储设置
saveLog=True # 运行时是否保存生成的日志,默认打开
# 无效设置
savePriceSql=False # 估价时是否将生成的数据表保存在mysql中,默认打开
# 系统设置
CONCURRENT_REQUESTS=32 # 并发线程数量,默认16
produCookie=False # 不验证cookies是否过期,直接重新生成cookies, 默认关闭
retryLogin=True # 登录失败自动重试,默认打开
retryMax=3 # 登录失败的自动重试次数,默认是3
waitDefaultTime=3 # 登录默认等待时间,默认是3
# 文件目录
Conf_DirName='conf_files'
Data_DirName='Data_files'
Book_DirName='Book_files'
Log_DirName='Log_files'
Root_Dir=os.path.dirname(os.path.dirname(os.path.dirname(__file__)))
Conf_Dir=os.path.join(Root_Dir,Conf_DirName) # 配置文件目录
Data_Dir=os.path.join(Root_Dir,Data_DirName) # 数据文件目录:个人信息
Book_Dir=os.path.join(Root_Dir,Book_DirName) # 电子书文件目录
Log_Dir=os.path.join(Root_Dir,Log_DirName) # 日志文件目录
Cookie_Path=os.path.join(Conf_Dir,theName+"_Cookie.Json") # Cookie路径,当然你可以指定规则和指定位置
# 文件名
loginLog="登录日志"
startLog="运行日志"
lastHotLog="最新热榜日志"
# 数据库名【务必和mysql中建好的一样!】
hot_db='zhihuhot'
# 默认请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
# 数据库配置
dbparams = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'root',
'charset':'utf8'
}
tableToOver=True # 同名数据表则覆盖内容,默认关闭,如果该项是关闭的,遇到同名数据表时会补充时间参数以达到【不同名】的效果
5、主爬虫
** zhihu.py**
# -*- coding: utf-8 -*-
import scrapy,function,re,json,time,pandas,os
from theConf import Config
from login import Login
class ZhihuSpider(scrapy.Spider):
name = 'zhihu'
allowed_domains = ['zhihu.com']
# 程序运行时间统计
startTime=time.time()
# 完成登录以及基本信息的获取'
cookies=Login().checkLogin()
# 写入日志
W=function.writeLog(Config.startLog)
csvlist=[]
def start_requests(self):
'激活cookies启动爬虫'
yield scrapy.Request(url=Config.theStart,callback=self.startParse,cookies=self.cookies)
def startParse(self,response):
'分发热榜'
if response.url!=Config.theStart:self.W.plog("cookies 激活失败!请重试!",act='exit')
self.W.plog("cookies激活成功!")
Ps=Config.theList
for key in Ps.keys():
yield scrapy.Request(url=Ps[key],callback=self.parsePage,meta={'key':key})
self.W.plog(key+"热榜 正在请求...")
def parsePage(self,response):
'热榜分类爬取'
items=response.xpath("//div[@class='HotList-list']/section")
for item in items:
rank=item.xpath("./div[@class='HotItem-index']/div[contains(@class,'HotItem-rank')]/text()").get()
label=item.xpath("./div[@class='HotItem-index']/div[contains(@class,'HotItem-label')]/text()").get()
url=item.xpath("./div[@class='HotItem-content']/a/@href").get()
imgurl=item.xpath("./a[@class='HotItem-img']/img/@src").get()
hot=item.xpath("./div[@class='HotItem-content']/div[contains(@class,'HotItem-metrics')]//text()").get()
if not label:label=''
if not imgurl:imgurl=''
if not hot:hot=''
else:
if not (hot.startswith("知乎") or hot.startswith("盐")):
hot=re.match(r".*\d", hot).group()
else:hot=0
item={
'rank':rank,
'label':label,
'url':url,
'imgurl':imgurl,
'hot':hot,
'field':response.meta['key']
}
if 'question' in url:yield scrapy.Request(url=url+"/log",callback=self.parseLog,meta=item,dont_filter=True)
def parseQuest(self,response):
'每个问题爬取'
infos_json=re.match(r'.*?