【项目收获】web服务器的收获2:tcp、IO
目录
nc:
tcp连接的正确关闭方式:
服务器tcp端口设置三连:
为什么IO多路复用要搭配非阻塞IO
为什么non-blocking网络编程中应用层buffer是必须的
linux最大打开文件描述符数目:
此版本与先前版本的区别之处:
写脚本监控进程的内存占用、cpu占用
tcp 的keepalive
nc:
netcat 简称 nc,安全界叫它瑞士军刀。ncat 也会顺便介绍,弥补了 nc 的不足,被叫做 21 世纪的瑞士军刀。nc 的基本功能如下:
telnet / 获取系统 banner 信息
传输文本信息
传输文件和目录
加密传输文件
端口扫描
远程控制 / 正方向 shell
流媒体服务器
远程克隆硬盘
参数如下
| 参数 |
说明 |
| -C |
类似-L选项,一直不断连接[1.13版本新加的功能] |
| -d |
后台执行 |
| -e prog |
程序重定向,一旦连接,就执行 [危险!!] |
| -g gateway |
源路由跳数,最大值为8(source-routing hop point[s],up to 8) |
| -G num |
源路由指针:4,8,12,... (source-routing pointer: 4,8,12,...) |
| -h |
帮助信息 |
| -i secs |
延时的间隔 |
| -l |
监听模式,用于入站连接 |
| -n |
指定数字的IP地址,不能用hostname |
| -o file |
记录16进制的传输 |
| -p port |
本地端口号 |
| -r |
任意指定本地及远程端口 |
| -s addr |
本地源地址 |
| -u |
UDP模式,[netcat-1.15可以:远程nc -ulp port -e cmd.exe,本地nc -u ip port连接,得到一个shell.] |
| -v |
详细输出——用两个-v可得到更详细的内容 |
| -w secs |
指定超时的时间 |
| -z |
将输入输出关掉——用于扫描时 |
用法例子:
https://www.oschina.net/translate/linux-netcat-command
1.端口扫描
2.Chat Server
3.文件传输
4.目录传输
5.加密你通过网络发送的数据
6.流视频
7.克隆一个设备
8.打开一个shell
tcp连接的正确关闭方式:
tcp数据发送不完整的情况:
当服务端send()发送完数据就立即close fd,若输入缓冲区内有数据,则close()会触发协议发送RST给客户端,导致客户端过早地断开连接,从而客户端接收到的数据不完整(服务端开一个while,每次读一个文件8k再send给客户端,最后发送的若干8k数据在客户端关闭后就送不到了)

第一次发送文件时,客户端不往服务端写数据,则客户端收到的文件大小是正常的1235399k字节
第二次发送文件时,客户端往服务端写1234567890这串数字,导致了客户端收到RST,提早关闭了连接,只收到1212416k
字节的数据,差了22983k字节。
正确的做法:

服务端send完数据后只关闭写端,保留读端(半关闭状态)->客户端读完了数据(read=0)且无数据要发送 就close -> 服务端read=0 从而close。
注意:若出现客户端恶意或者有bug 一直不close连接,那么服务端可能会一直阻塞或者返回ERRNO=EAGAIN,不满足read=0的情况,就不会close,因此一般要加上一个超时时间,在关闭写端后若干秒内没有收到read=0也强行关闭连接。
对于TCP non-blocking socket, recv返回值== -1,但是errno == EAGAIN, 此时表示在执行recv时相应的socket buffer中没有数据,应该继续recv。
见另一篇文章的 优雅关闭连接
优雅关闭连接(linger):服务器close连接时,会先将缓冲区内未发送完的数据发出去再关闭连接(可设置超时)。
半关闭:服务端send完数据后只关闭写端,保留读端(半关闭状态)->客户端读完了数据(read=0)且无数据要发送 就close -> 服务端read=0 从而close。若出现客户端恶意或者有bug 一直不close连接,那么服务端可能会一直阻塞或者返回ERRNO=EAGAIN,不满足read=0的情况,就不会close,因此一般要加上一个超时时间,在关闭写端后若干秒内没有收到read=0也强行关闭连接。
TCP的连接的拆除需要发送四个包,因此称为四次挥手(four-way handshake)。客户端或服务器均可主动发起挥手动作,在socket编程中,任何一方执行close()操作即可产生挥手操作。
服务器tcp端口设置三连:
tcp NoDelay :关闭tcp的 Nagle算法
ignore sigpipe: 防止某个客户端意外断开连接时,服务器还在往他写数据,会收到RST和sigpipe,导致服务器进程退出的bug
当服务器close一个连接时,若client端接着发数据。根据TCP协议的规定,会收到一个RST响应,client再往这个服务器发送数据时,系统会发出一个SIGPIPE信号给进程,告诉进程这个连接已经断开了,不要再写了。
socket reuseaddr :打开端口复用:目的是在服务器挂掉后能够立即重启,监听跟刚才同一个端口,否则会显示端口正在被监听,一般要等2分钟才能再次监听(time_wait) 。 情况2:accept新连接后创建了一个子进程来处理客户端请求,此时监听进程停止了,重启时,由于子进程正在处理客户端请求(这个连接占用了端口),若没开启SO_REUSEADDR将会导致bind失败,监听进程无法启动。
linger:优雅关闭连接
为什么IO多路复用要搭配非阻塞IO
- select、poll_wait、epoll_wait返回可读≠read去读的时候能读到(因为select和read是两个独立的系统调用)。如果不用非阻塞,程序会永远卡在read上。以上情况可能出现在多进程同时监听一个socket,只有一个进程可以accept,别的都会block(惊群效应)。
- 假如socket的读缓冲区已经有足够多的数据,需要read多次才能读完,如果是非阻塞可以在循环里读取,不用担心阻塞在read上,等到errno被置为EWOULDBLOCK的时候break,安全返回select。但如果是阻塞IO,只敢读取一次,因为如果读取没有数据的fd,read会阻塞,无法返回select,这样就只能期待着多次从select返回,每次只读一次,效率低下。而且,如果是ET模式,还会造成数据无人处理,导致饥饿。
为什么non-blocking网络编程中应用层buffer是必须的
首先,multiplex的核心思想是——用一个线程去同时对多个socket连接服务,(传统的模式是一个thread/process只对一个connection服务),而想要做到这一点,thread/process就不能阻塞在某一个socket的read或write上,就要用到非阻塞IO,原因见上。(应该阻塞在epoll_wait的调用上)
那么现在假设你要向一个socket发送100kb的数据,但是write调用中,操作系统只接受了80kb的数据,原因可能是受制于TCP的流量控制等等,现在你有两个选择 :
1. 等——你可以while这个write调用,但你不知道要等多久,这取决于对方什么时候收到之前的报文并且滑动窗口,而且这样也浪费了处理别的socket的时间。
2. 把剩下的20kb存起来,下次再发,具体一点就是把这20kb保存在这个TCPconnection的output buffer里,并且注册POLLOUT事件,这样select下次返回的时候就还会来发送这20kb的数据,也不会影响别的socket的监听。
- 若20kb发送之前,又有数据要write,则应该append到缓冲区尾部,否则可能造成乱码
- POLLOUT可写事件到来是由操作系统的发送缓冲区有空触发的,同理EPOLLIN事件是操作系统接收缓冲区有数据触发的
- 若缓冲区为empty,则应该停止关心POLLOUT事件,否则可能会busy loop(但是epoll的ET模式下不会再次提醒,就没有这个问题)
至于为什么需要inputbuffer, 那是因为TCP是一个没有边界的字节流协议,不可能一个数据报就是一个请求。
非阻塞IO这里涉及到一个问题,考虑这样一个简单场景:
1. 有一个echo服务器,他的任务就是简单的将客户端发来的数据存到机子的缓冲区里,等到read=0的时候就将缓冲区的数据write回客户端。 现在有一个恶意客户端,往服务器不停地写写写,这样服务器的缓冲区就会一直变大(无限增大或者到达上限后开始溢出丢包),导致服务器程序占用的内存不断增大。这时候应该在程序中设置一个缓冲区大小上限,达到上限时就停止收包,赶紧清空缓冲区。
2. 有个代理服务器,他和服务器之间的带宽是1Gb, 客户端通过普通家用宽带(假设8Mb)像代理服务器请求一个大文件,那么代理服务器很快就从服务器里拿到了整个文件,但是他发给客户端的速度太慢了,出现这种情况:

应该要设置一个高水位和低水位,高于高水位时停止发送,低于低水位时快速发送
同步IO和异步IO:
同步IO 指的是,必须等待IO 操作完成后,控制权才返回给用户进程。异步IO 指的是,无须等待IO 操作完成,就将控制权返回给用户进程。
阻塞IO和非阻塞IO:
阻塞和非阻塞的概念描述的是用户线程调用内核IO 操作的方式:阻塞是指IO 操作需要彻底完成后才返回到用户空间;而非阻塞是指IO 操作被调用后立即返回给用户一个状态值,不需要等到IO 操作彻底完成。
在非阻塞状态下, recv()接口在被调用后立即返回,返回值代表了不同的含义,如下
所述。
( 1 ) recv()返回值大于0 ,表示接收数据完毕,返回值即是接收到的字节数。
( 2) recv()返回0 ,表示连接已经正常断开。
( 3) recv()返回- 1 ,且ermo 等于EAGAIN ,表示recv 操作还没执行完成(内核中数据还没准备好)。
( 4) recv()返回斗,且ermo 不等于EAGAIN ,表示recv 操作遇到系统错误ermo 。

可以看到服务器线程可以通过循环调用recv()接口,可以在单个线程内实现对所有连接的数据接收工作。但是上述模型绝不被推荐,因为循环调用recv()将大幅度占用CPU 使用率; 此外, 在这个方案中recv()更多的是起到检测“操作是否完成”的作用,实际操作系统提供了更为高效的检测“操作是否完成”作用的接口,例如select() 多路复用模式,可以一次检测多个连接是存活跃。
异步IO 模型的流程如图7-6 所示。
用户进程发起read 操作之后,立刻就可以开始去做其他的事;而另一方面,从内核的角度,当它收到一个异步的read 请求操作之后,首先会立刻返回,所以不会对用户进程产生任何阻塞。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存中,当这一切都完成之后,内核会给用户进程发送一个信号,返回read 操作已完成的信息。

调用阻塞IO 会一直阻塞住对应的进程直到操作完成,而非阻塞IO 在内核还在准备数据的情况下会立刻返回。
同步IO与异步IO的区别就在于同步IO 进行IO 操作时会阻塞进程。按照这个定义,之前所述的阻塞IO 、非阻塞IO 及多路IO 复用都属于同步IO 。实际上,真实的IO操作,就是例子中的recvfrom 这个系统调用。非阻塞IO 在执行recvfrom 这个系统调用的时候,如果内核的数据没有准备好,这时候不会阻塞进程。但是当内核中数据准备好时,recvfrom 会将数据从内核拷贝到用户内存中,这个时候进程则被阻塞。而异步IO 则不一样,当进程发起IO 操作之后,就直接返回,直到内核发送一个信号,告诉进程IO 已完成,则在这整个过程中,进程完全没有被阻塞。
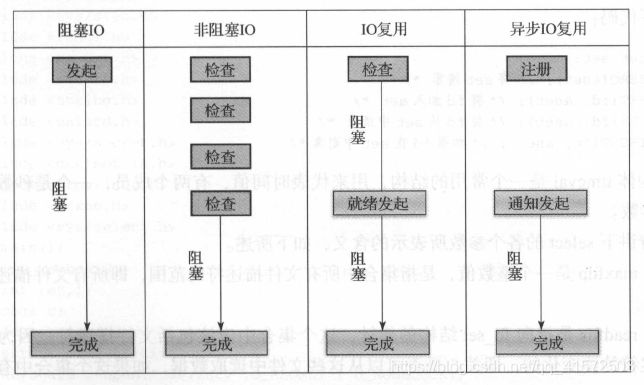
各个IO 模型的比较如图:
linux最大打开文件描述符数目:
系统最大打开文件描述符数:/proc/sys/fs/file-max
1. 查看
$ cat /proc/sys/fs/file-max
186405
2. 设置
a. 临时性
echo 1000000 > /proc/sys/fs/file-maxb. 永久性:在/etc/sysctl.conf中设置
fs.file-max = 1000000
2. 进程最大打开文件描述符数:user limit中nofile的soft limit
1. 查看
$ ulimit -n
17000002. 设置
a. 临时性:通过ulimit -Sn设置最大打开文件描述符数的soft limit,注意soft limit不能大于hard limit(ulimit -Hn可查看hard limit),另外ulimit -n默认查看的是soft limit,但是ulimit -n 1800000则是同时设置soft limit和hard limit。对于非root用户只能设置比原来小的hard limit。
查看hard limit:
$ ulimit -Hn
1700000设置soft limit,必须小于hard limit:
$ ulimit -Sn 1600000b. 永久性:上面的方法只是临时性的,注销重新登录就失效了,而且不能增大hard limit,只能在hard limit范围内修改soft limit。若要使修改永久有效,则需要在/etc/security/limits.conf中进行设置(需要root权限),可添加如下两行,表示用户chanon最大打开文件描述符数的soft limit为1800000,hard limit为2000000。以下设置需要注销之后重新登录才能生效:
chanon soft nofile 1800000
chanon hard nofile 2000000设置nofile的hard limit还有一点要注意的就是hard limit不能大于/proc/sys/fs/nr_open,假如hard limit大于nr_open,注销后无法正常登录。可以修改nr_open的值:
echo 2000000 > /proc/sys/fs/nr_open
3. 查看当前系统使用的打开文件描述符数
[root@localhost bin]# cat /proc/sys/fs/file-nr
5664 0 186405其中第一个数表示当前系统已分配使用的打开文件描述符数,第二个数为分配后已释放的(目前已不再使用),第三个数等于file-max。
4. 总结:
a. 所有进程打开的文件描述符数不能超过/proc/sys/fs/file-max
b. 单个进程打开的文件描述符数不能超过user limit中nofile的soft limit
c. nofile的soft limit不能超过其hard limit
d. nofile的hard limit不能超过/proc/sys/fs/nr_open
此版本与先前版本的区别之处:
- RAII机制管理fd、锁等对象,减少了内存泄漏的可能。例如:每个fd都是由一个httpdata对象进行管理的,主线程accept产生读写fd后,就创建一个httpdata对象来管理他,在httpdata对象析构时close他。不需要我们手动close,这也减少了服务端由于无法close而堆积大量close-wait状态连接的现象。还有shared_from_this(),确保对象的生存周期大于回调中构造的函数对象的生命周期,使用场景是处理httpdata对象关闭fd时。
- 固定数量线程循环可充分发挥多核cpu的性能。每个eventloop都有自己的任务队列,由主线程accept新连接后以round robin形式放入新任务。固定线程数量同时是为了使一个fd固定由一个线程处理。
- keep-alive选项:若无则一个httpdata的timeout为2000ms,若有,则为300000ms。
- 线程池与one-loop-per-thread:使用线程池时,可能同一个客户端发来的先后两个请求会被池中不同的两线程处理(指的是IO操作全在主线程,而线程池只负责计算的情况,若线程池计算完直接IO则不会),若后一次请求的复杂度较低,可能客户端会先收到后一次响应,造成乱序(因为线程池是新来一个请求就插入到线程池的queue尾部,然后notify一个线程来处理),应通过响应id来判断。若用one-loop-per-thread,则一个fd从始至终只由一个线程管理,不会有乱序现象。
写脚本监控进程的内存占用、cpu占用
https://www.cnblogs.com/saryli/p/9924544.html
https://blog.csdn.net/bbwangj/article/details/81320896
核心命令:
cat /proc/pid/status其中PID是具体的进程号,这个命令打印出/proc/特定进程/status文件的内容,信息比较多,包含了物理内存/虚拟内存的使用状况,监控进程是否有内存泄露的问题,一般查看进程占用物理内存的情况:
VmRSS: xxxkB
可以采用grep命令过滤出我们需要的信息:
cat /proc/$PID/status | grep RSS >> "$LOG" #过滤包含RSS的行,并且重定向到参数LOG表示的文件
由于PID号需要通过进程名获取,同样使用grep命令过滤出我们指定进程的进程号:
ps | grep $PROCESS | grep -v 'grep' | awk '{print $1;}'#$PROCESS表示进程名字
脚本示例1:
#!/bin/bash
pid=$1 #获取进程pid
echo $pid
interval=1 #设置采集间隔
while true
do
echo $(date +"%y-%m-%d %H:%M:%S") >> ./proc_memlog.txt
cat /proc/$pid/status|grep -e VmRSS >> ./proc_memlog.txt #获取内存占用
cpu=`ps -p $1 -o pcpu |grep -v CPU | awk '{print $1}' | awk -F. '{print $1}'` #获取cpu占用
echo "Cpu: " $cpu >> ./proc_memlog.txt
echo $blank >> ./proc_memlog.txt
sleep $interval
done调用方式:
$ sh shellName.sh [pid]
#exp:
sh monitor.sh 1234运行效果:proc_memlog.txt文件中:
tcp 的keepalive
- TCP Keepalive的起源
TCP协议中有长连接和短连接之分。短连接环境下,数据交互完毕后,主动释放连接;
长连接的环境下,进行一次数据交互后,很长一段时间内无数据交互时,客户端可能意外断电、死机、崩溃、重启,还是中间路由网络无故断开,这些TCP连接并未来得及正常释放,那么,连接的另一方并不知道对端的情况,它会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,且有可能导致在一个无效的数据链路层面发送业务数据,结果就是发送失败。所以服务器端要做到快速感知失败,减少无效链接操作,这就有了TCP的Keepalive(保活探测)机制。
- TCP Keepalive工作原理
当一个 TCP 连接建立之后,启用 TCP Keepalive 的一端便会启动一个计时器,当这个计时器数值到达 0 之后(也就是经过tcp_keep-alive_time时间后,这个参数之后会讲到),一个 TCP 探测包便会被发出。这个 TCP 探测包是一个纯 ACK 包(规范建议,不应该包含任何数据,但也可以包含1个无意义的字节,比如0x0。),其 Seq号 与上一个包是重复的,所以其实探测保活报文不在窗口控制范围内。
如果一个给定的连接在两小时内(默认时长)没有任何的动作,则服务器就向客户发一个探测报文段,客户主机必须处于以下4个状态之一:
1. 客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常的,服务器在两小时后将保活定时器复位。
2. 客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP都没有响应。服务端将不能收到对探测的响应,并在75秒后超时。服务器总共发送10个这样的探测 ,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
3. 客户主机崩溃并已经重新启动。服务器将收到一个对其保活探测的响应,这个响应是一个复位,使得服务器终止这个连接。
4. 客户机正常运行,但是服务器不可达,这种情况与2类似,TCP能发现的就是没有收到探测的响应。
对于linux内核来说,应用程序若想使用TCP Keepalive,需要设置SO_KEEPALIVE套接字选项才能生效。
有三个重要的参数:
1. tcp_keepalive_time,在TCP保活打开的情况下,最后一次数据交换到TCP发送第一个保活探测包的间隔,即允许的持续空闲时长,或者说每次正常发送心跳的周期,默认值为7200s(2h)。
2. tcp_keepalive_probes 在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包次数,默认值为9(次)
3. tcp_keepalive_intvl,在tcp_keepalive_time之后,没有接收到对方确认,继续发送保活探测包的发送频率,默认值为75s。
其他编程语言有相应的设置方法,这里只谈linux内核参数的配置。例如C语言中的setsockopt()函数,java的Netty服务器框架中也提供了相关接口。
- TCP Keepalive可能导致的问题
Keepalive 技术只是 TCP 技术中的一个可选项。因为不当的配置可能会引起一些问题,所以默认是关闭的。
可能导致下列问题:
1. 在短暂的故障期间,Keepalive设置不合理时可能会因为短暂的网络波动而断开健康的TCP连接
2. 需要消耗额外的宽带和流量
3. 在以流量计费的互联网环境中增加了费用开销
- TCP Keepalive HTTP Keep-Alive 的关系
HTTP协议的Keep-Alive意图在于TCP连接复用,同一个连接上串行方式传递请求-响应数据;TCP的Keepalive机制意图在于探测连接的对端是否存活。