hadoop介绍
1.hadoop的概念:
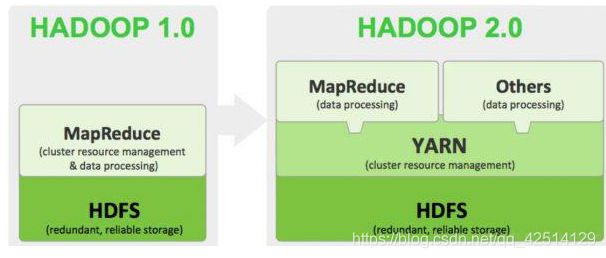
hadoop是apache下的一个开源软件框架,hadoop允许使用简单的编程模型来完成大量计算机集群下的大量数据的分布式处理
狭义上:hadoop单指apache下的产品
* HDFS(hadoop分布式文件系统): 解决海量数据存储问题
* YARN(任务调度和资源管理框架): 解决海量数据运算时的资源调度问题
* MAPREDUCE(分布式运算编程框架): 解决海量数据计算问题
广义上:hadoop指haoop生态圈,包括其他社区对hadoop的扩展
2.hadoop优点:
扩容能力强(横向无线扩容),成本低,高性能,高可靠
3.hadoop集群:
hadoop集群集群主要包含两个集群:HDFS集群,YARN集群,两者逻辑上分离,物理上常配置在相同计算机上;
* HDFS集群中的角色:
namenode datanode secondaryNamenode
* YARN集群中的角色:
resourceManager nodeManager
* mapreduce主要体现在代码层面
4.hadoop部署模式:
独立模式(单机单进程),伪分布式模式(单机多进程),集群模式
5.hadoop集群访问:
首次启动HDFS时,必须对其进行格式化操作(主要是自动生成一些文件,及配置信息,并且只能格式化唯一一
次),hdfs namenode–format;
NameNode http://nn_host:port/ 默认50070.
ResourceManager http://rm_host:port/ 默认 8088.
HDFS
1.HDFS介绍:
HDFS,全称Hadoop Distribute File System,Hadoop分布式文件系统,主要解决海量数据的存储问题
2.HDFS的特性:
2.1 master/slave架构
HDFS集群中,有一个master节点,多个slave节点;master(namenode)负责管理文件目录结构及分块文件的存储信息(分块文件ID,分块文件所在的datanode),由slave(datanode)来完成文件的分块存储
2.2 分块存储,副本存储
默认情况下,大文件会被分割为128M的多个小文件并保存一共默认3份副本,存储在不同的datanode下,datanode定时向namenode汇报自己的存储信息分块文件
2.3 一次写入,多次读取
HDFS的本身设计不推荐文件的修改
3.hadoop shell脚本:
hadoop fs -put -f /home/test/a.txt /hdDir #将当前系统上的a.txt放到HDFS的hdDir目录下
hadoop fs -get /hdDir/a.txt ./ # 从HDFS的hdDir目录获取a.txt到当前目录
4.HDFS的元数据:
文件系统中所有文件的目录树,以及分块文件的存储相关信息,对元数据备份的方式分为:fsimage镜像文件(RDB)和edits log(AOF);fsimage镜像文件会定时更新,但是镜像文件不记录分块的具体位置,由namenode重启时,datanode主动汇报分块信息;并且edits log会在增删改操作前先记录本次操作,
5.namenode:
* 每个HDFS集群都只有一个namenode;是HDFS集群中的单点故障
* namenode负责维护元数据信息,并将元数据存储到缓存中;secondaryNamenode会协助namenode对元数据进
行备份;当namenode重启时,通过读取元数据备份信息,以及datanode主动汇报的信息来完成namenode元数据的
重建;
* namenode只负责元数据维护,不负责数据存储;
* 通常namenode节点所在计算机要求内存足够大
6.datanode:
* 每个HDFS集群都有多个datanode;
* datanode负责大文件的分块存储和副本存储,datanode会将大文件拆分成128M,并保存3份副本,分别存放到不同的datanode中
* datanode默认每隔3s向namenode汇报心跳,每隔6h向namenode汇报保存的当前datanode分块存储文件信息
* 通常datanode节点所在的计算机要求硬盘足够大
7.HDFS工作原理:
namenode负责元数据的管理,secondaryNode协助nameNode对元数据进行备份,datanode负责对分块文件的存储(datanode并不保存一整个完整的数据,而是通过将分块拼接获得完整数据);客户端请求访问HDFS实际上就是通过操作namenode来完成
8.checkpoint元数据合并
当满足一定的触发条件时,secondaryNameNode就会通过http get请求的方式,将namenode上的fsimage镜像文件和edits log编辑日志拉取到secondaryNameNode所在的机器上;然后将镜像文件加载进内存,重演编辑日志中的记录,更新镜像文件;更新完成后,再次把新的镜像文件dump下来,保存到namenode所在机器,并且标识最新的镜像文件;
由于dump镜像时,namenode可能正在提供服务,因此dump镜像的操作只能由secondaryNameNode完成;
由于namenode和secondaryNameNode都需要加载镜像文件到内存,占用的内存非常高,因此通常会将namenode和secondaryNameNode部署在不同的机器上;
secondaryNameNode本质上是用来帮助namenode完成镜像文件的更新合并的,并不是namenode的备份文件;但是如果namenode机器真的出了问题,也可以使用secondaryNameNode上合并镜像文件时留下的文件,这样可以恢复部分数据,止损
9.checkpoint触发条件
通过core-site.xml进行配置,
<property>
<name> dfs.namenode.checkpoint.period</name>
<value>3600</value>
<description>
两次连续的checkpoint之间的时间间隔。默认1小时
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>
最大的没有执行checkpoint事务的数量,满足将强制执行紧急checkpoint,即使尚未达到检查点周期。默认设置为100万。
</description>
</property>
10.HDFS安全模式(只读模式):
* 自动进入安全模式:
当namenode启动时,由于HDFS服务下,数据不完整,会自动进入安全模式;当datanode也启动完毕,并且维持30s不出现波动,就会自动退出安全模式;在安全模式下,HDFS不允许客户端进行任何增删改操作,只允许读取数据;
退出安全模式的条件:datanode汇报的可用分块达到namenode记录分块数的比例(0.999),可用datanode达到要求(默认0),保持上述条件30s
*手动进入安全模式: 通常用于集群升级维护
hdfs dfsadmin -safemode enter
hdfs dfsadmin -safemode leave
HDFS读写数据流程
==>写数据
1.客户端发送上传文件的请求给namenode,namenode校验文件系统目录树是否存在客户端指定的目录,是否已经存在客户端上传的文件来决定,响应允许上传文件或者拒绝上传文件;
2.客户端再次请求namenode第一个分块文件存储的位置,namenode根据HDFS存储策略,即:客户端本地一份,客户端所在的机架上的其他机器一份,以及其他机架上的机器一份;根据网络拓扑图的距离,按照从近到远的顺序依次返回这3个datanode的IP给客户端;
3.客户端获得这3个IP后,根据IP的顺序,请求与这3个datanode建立一个串行的Pipeline,即:客户端-->dn1-->dn2-->dn3,再由这3个datanode反序响应连接结果;
4.客户端每次向管道中传输64KB的package(Buffer),当到达第一个节点时,保存package并继续流向第二个节点,再流向第三个节点;最终从第三个节点开始返回保存信息,依次往回响应,通知客户端是否保存成功
5.当第一个分块文件保存完成,客户端继续向namenode请求上传第二个.....
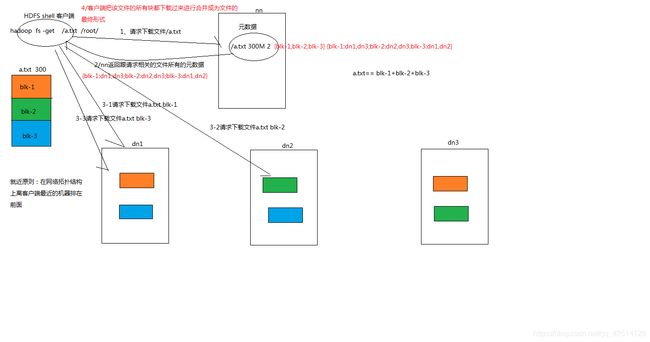
==>读数据
1.客户端向namenode发送RPC下载文件请求,namenode检查校验目录树是否存在文件;如果存在就返回这个文件所对应的block副本信息和datanode位置,并按照网络拓扑图的距离(就近原则)以及datanode的心跳活跃(心跳状况差的靠后)情况排序,返回给客户端;
2.客户端收到namenode返回的文件信息后,按照返回信息指定的datanode位置并行开启Socket Stream(FSDataInputStream) 开始下载文件;
3.每读完一个分块,都会进行checksum验证,如果某个副本下载出错,就再从它的下一个副本重新下载;
4.最终全部下载完毕后,合并分块得到完整的文件
HDFS API
public class TestHDFSClient{
@Test
public void testUpload() throws Exception{
System.setProperty("HADOOP_USER_NAME", "root");
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://node-1:9000");
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.copyFromLocalFile(new Path("e:/a.txt"),new Path("/hdfsDir/"));
fileSystem.close();
}
@Test
public void testDownload() throws Exception{
....
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.copyToLocalFile(new Path("/hdfsDir/a.txt"),new Path("e:/"));
fileSystem.close();
}
@Test
public void testUploadByStream(){
....
FSDataOutputStream dos = fileSystem.create(new Path("/hdfsDir/"));
FileInputStream fis = new FileInputStream("e:/a.txt");
IOUtils.copy(fis,dos);
}
@Test
public void testDownloadByStream(){
....
FSDataInputStream dis = fileSystem.open("/hdfsDir/a.txt");
FileOutputStream fos = new FileOutputStream("e:/");
IOUtils.copy(dis,fos);
}
}
坐标:
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
</dependencies>
Hadoop Shell完成文件定时上传
数据采集阶段获得为access.log文件,通常每隔1h滚动一次,因此log目录下应该包含一个正在记录的
access.log文件,以及多个滚动后的文件access.log.1,access.log.2 ...;shell脚本定时查找log目录下的
所有已经滚动后的日志文件,并移动到toUpload待上传目录并重命名为toUpload.n,并将待上传文件移动后的路径
记录到一个新的日志文件中;接着shell开始遍历日志文件中的待上传文件(toUpload.n结尾的文件),先将
toUpload.n重命名为doingUpload.n然后开始向hdfs上传文件,上传成功后,再将doingUpload.n重命名为
haveUpload.n;然后继续开始上传其他文件;每一次重命名文件都会带上时间戳