python爬取美团评论
文章目录
- 1、分析网页
- 1.1如何进行抓包
- 2.爬取评论
- 3.爬取存入CSV代码汇总
- 4.爬取所有评价
- 4.1.爬取所有页面代码
1、分析网页
这是一家花溪大学城的店铺,现在学习对评点的信息进行爬取
店铺链接:https://www.meituan.com/meishi/193383554/
对于学习网络爬虫,不管对什么网页,我们做的第一件事都是要先对网页进行分析,然后再对它进行抓包分析,然后再决定请求服务器的方式。
 我们可以看到这有很多页的评价,所以我们先分析每一页的url,看是否会有变换:
我们可以看到这有很多页的评价,所以我们先分析每一页的url,看是否会有变换:
第一页:https://www.meituan.com/meishi/193383554/
第二页:https://www.meituan.com/meishi/193383554/
第三页:https://www.meituan.com/meishi/193383554/
分析结果:
再点击下一页,它的URL并没有发生变化,可以初步判断它是ajax加载的数据,而我们现在所做的就是不再将ajax里的内容放进HTML里,而是把它截取出来分析。
1.1如何进行抓包
抓包步骤
1.选择页面,右键进入检查元素
2.选择Network
3.选择All
4.刷新网页(快捷键CTRL+R)
5.查看加载的数据
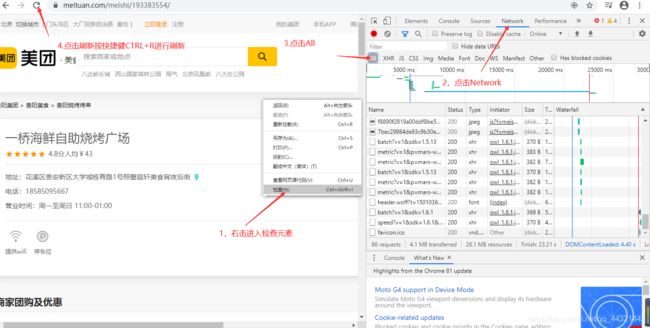
怎么查看加载的内容
1.我们只需要注重看 Network 中的Type(加载的文件类型) 和 size(加载的文件大小) 这两个要素,因为我们要查看的目标是文字文件,而带有图片类型的文件都可以不用查看了,其二就是它的大小。
2.查看内容
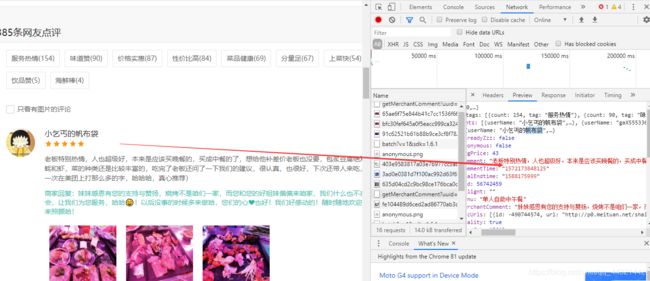 3.请求请求数据的方式,把它点在headers这里查看它的请求头
3.请求请求数据的方式,把它点在headers这里查看它的请求头
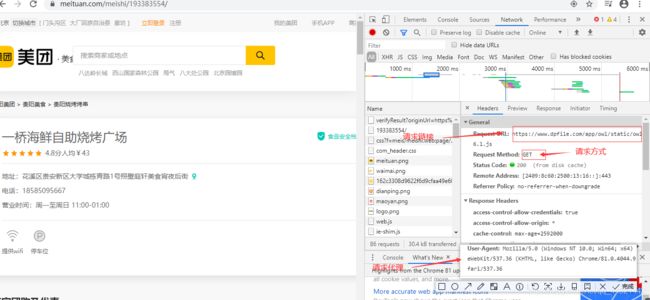
4.把上面的链接复制到浏览器打开

5.分析每一页的评论路径

从上面的结果发现,它们的参数只有 offset= 不同,并且间隔为10,接下来我们直接生成对应的这个数据通道。
以上便完成抓包
2.爬取评论
1.请求服务器

请求的值为200,百事请求成功,现在在括号后面添加.text,将请求的内容变为文本格式。

可以将所请求的内容赋予一个reponse
2.用json匹配内容
[0][“userName”]中[0]里面的0,1表示选取的用户
reponse.json()["data"]["comments"][0]["userName"]代码结果如下
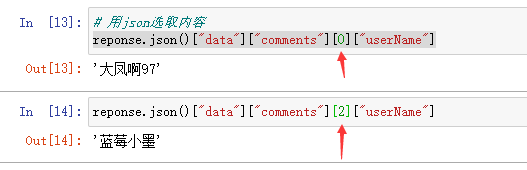
接下来用for循环提取内容,一页只有十个用户
代码表示如下
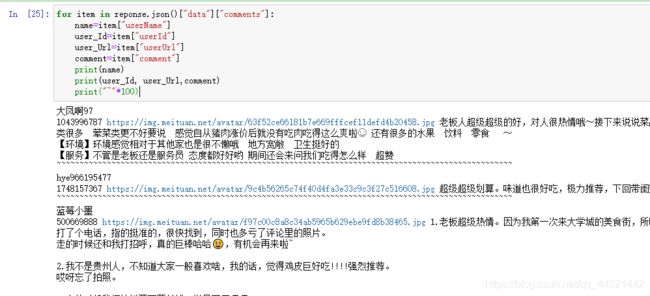
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
user_Id=item["userId"]
user_Url=item["userUrl"]
comment=item["comment"]
表示结果如下
3.爬取存入CSV代码汇总
存入csv的代码为
#"./"表示当前文件夹,"a"表示添加
fp = open('./美团.csv','a', newline='',encoding='utf-8-sig')
#方式为写入
writer = csv.writer(fp)
#关闭文件夹
fp.close总代码为
import requests,csv
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=d6c8026e-ccb2-46b3-8e77-1f5dad952f63&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset=0&pageSize=10&sortType=1"
# 设置请求浏览器/字典型
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}
# 请求方式
reponse=requests.get(url=ajax_url,headers=headers_meituan)#将所得的内容赋予一个值reponse
print(reponse)
# 新建文件夹
fp = open('./美团.csv','a', newline='',encoding='utf-8-sig')
#方式为写入 表头
writer = csv.writer(fp)
writer. writerow(("用户名","用户ID","用户链接","用户评价")) #表头
# writer. writerow((name,user_Id, user_Url,comment))
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
user_Id=item["userId"]
user_Url=item["userUrl"]
comment=item["comment"]
print(name)
result=(name,user_Id, user_Url,comment)
print(result)
writer. writerow(result)
print("~"*100)
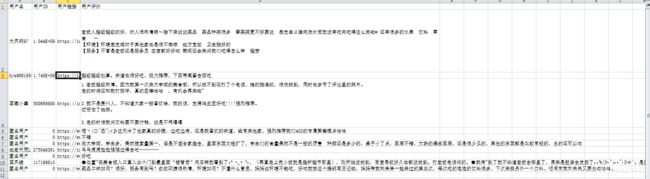
fp.close()运行结果为
这是第一页的所有评论
4.爬取所有评价
1.分析ajax_url链接

从上面的结果发现,它们的参数只有 offset= 不同,并且间隔为10
2.用for循环爬取所有页面链接
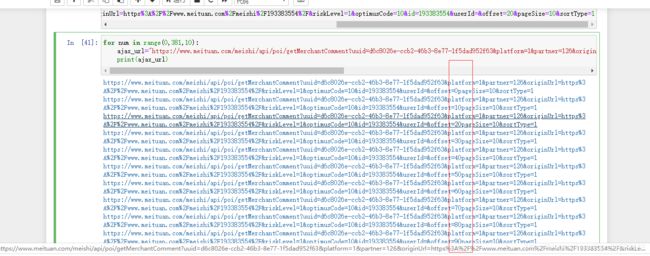
for num in range(0,381,10):
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=d6c8026e-ccb2-46b3-8e77-1f5dad952f63&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset="+str(num) +"pageSize=10&sortType=1"
print(ajax_url)运行结果如下
爬取所有页面成功
4.1.爬取所有页面代码
import requests,csv
# 设置请求浏览器/字典型
headers_meituan={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36"
}
# 新建文件夹
fp = open('./美团.csv','a', newline='',encoding='utf-8-sig')
#方式为写入 表头
writer = csv.writer(fp)
writer. writerow(("用户名","用户ID","用户链接","用户评价"))
#爬取所有网页
for num in range(0,381,10):
print("正在爬取%s条......."%num)
ajax_url="https://www.meituan.com/meishi/api/poi/getMerchantComment?uuid=d6c8026e-ccb2-46b3-8e77-1f5dad952f63&platform=1&partner=126&originUrl=https%3A%2F%2Fwww.meituan.com%2Fmeishi%2F193383554%2F&riskLevel=1&optimusCode=10&id=193383554&userId=&offset="+str(num) +"pageSize=10&sortType=1"
print(ajax_url)
reponse=requests.get(url=ajax_url,headers=headers_meituan)#将所得的内容赋予一个值reponse
for item in reponse.json()["data"]["comments"]:
name=item["userName"]
user_Id=item["userId"]
user_Url=item["userUrl"]
comment=item["comment"]
result=(name,user_Id, user_Url,comment)
print(result)
writer. writerow(result)
print("~"*100)
fp.close()运行结果如下
