理论基础
| JML语法 |
|
| 原子表达式 |
|
| \result |
表示方法的返回值 |
| \old(expr) |
expr在方法执行前的值 |
| \not_assigned(x,y,…) |
表示变量在方法执行过程中没有被赋值 |
| \nonnullelements(container) |
表示container中存储的值不会有null |
| \type(type) |
表示值对应的类型 |
| \typeof(expr) |
表示expr的类型 |
| 量化表达式 |
|
| \forall |
表达对于给定范围内的所有元素都满足相应约束 |
| \exists |
表示给定范围内存在元素满足相应约束 |
| \sum |
表示给定范围内表达式的和 |
| \product |
表示给定范围内表达式的连乘的积 |
| \max |
表示给定范围内表达式的最大值 |
| \min |
表示给定范围内表达式的最小值 |
| 操作符 |
|
| ==>,<== |
推理操作符 |
| <==> |
等价操作符 |
| \nothing |
空集 |
| \everything |
全集 |
| 方法规格 |
|
| requires |
前置条件 |
| ensures |
后置条件 |
| assignable |
副作用 |
JML工具链
这单元与JML相关的学习和使用的主要有三个工具 openJML,SMT sovler,和JLMUnitNG.
openJML:可以在静态和运行时检查程序是否满足规格
SMT sovler:JML的形式化验证
JMLunitNG:根据规格自动生成测试样例
openJML及JMLUnitNG部署
部署openJML的时候,我遇到了错误.

这个问题卡了我好久,上网搜也搜不到该怎么解决,最后只能 放弃
架构设计
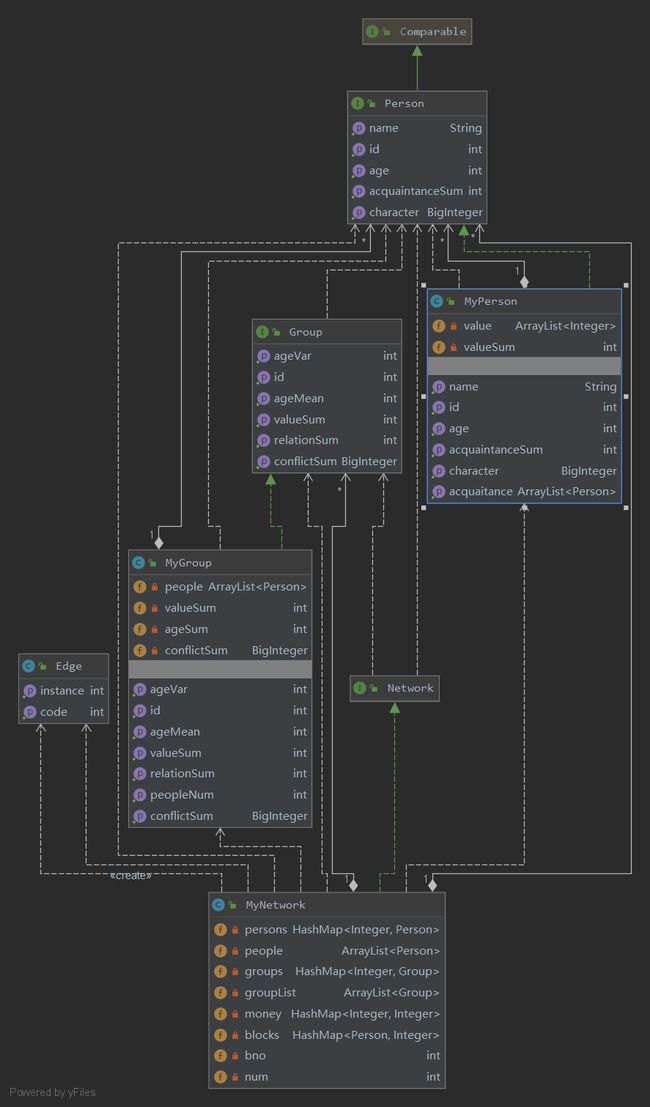
第一次作业的目的主要是为了让我们熟悉JML类,难度方面较低.需要完成的只有Network和Person两个类.这次作业,最麻烦的还在于isCircle函数.由于对JML的轻视,没有进行测试,在这里最后CTLE,挂了强测.
第二次在第一次的基础上增加了Group类,难度方面也没有增加很高.主要在于queryGroupRelationSum和queryGroupValueSum.如果按JML来写的话,复杂度会是O(n^2),可能会导致超时,最终我选择了缓存的方法,通过缓存下来RelationSum和GroupSum,在每次addPerson和addRelation降低了复杂度.此外,queryAgeMean可能会出现除零错误,没有仔细看JML的话也容易出错.
第三次我认为难度相比第二次大大增加.,增加了queryMinPath,queryStrongLinked和queryBlockNum,我分别使用了迪杰斯特拉算法,tarjan算法和并查集解决了这三个难题.其中理解和使用tarjan算法耗费了我大量的时间,而使用的朴素迪杰斯特拉算法复杂度还是较高,导致强测中有三个点出现了TLE,最后debug时使用了堆优化迪杰斯特拉算法.
Bug 分析
HomeWork1
这一次作业最容易出现的bug就是isCircle这里的CTLE问题了.
HomeWork2
第二次作业,如果Group求Sum的那一系列方法,没有采用缓存的话,很容易会导致TLE,而queryAgeMean这地方也有两个坑.一是整除结果是整数,需要注意JML规格中的括号位置,严格按照JML来写,否则可能出现结果不一致.二是这地方可能会出现除零错误,需要注意.
HomeWork3
第三次作业,主要难度还是在算法层面.找最短路径,如果不使用堆优化迪杰斯特拉算法的话很可能被卡时间.
而求强连通,一开始我是采用两层dfs莽的方式,在室友提醒下发现这个方法存在致命bug,很可能导致原本存在强连通的返回却是false.
心得体会
总体而言,这次JML难度并没比前两次高多少,但是坑点很多.在这一单元受到了一次惨痛的教训.
这一单元变化最大的就是一开始,我几乎时完全照着JML写程序,最后出现了很多问题,也没有很理解代码.到了后来,我只是看JML的要求和细节,思路则是自己想,最后写出来的程序真正是自己的.
通过这单元的学习,我了解了JML,但是在我现在的观点看来,JML实在太不灵活.JML自身写起来极为繁琐,可读性也不是很好,注定了无法应用于大工程.而通过自身使用JML工具的经验,这些工具大多已经停止了开发.且使用方面也有诸多不便,因此.尽管JML有着极强的的规范性,但我并不喜欢和看好JML.