Python项目实战:通过jieba分词统计招聘大数据帮你找工作.md
前言:
一切不经过项目验证的代码都是耍流氓,今天我们就通过一个简单的招聘网站的数据归档(数据来源请参考我的上一篇文章)进行当前热门岗位的大数据分析,最后以wordcloud进行显示。帮你分析一名合格的Python从业者到底要掌握什么样的技能。
当然,这篇文章说是大数据是有点严重夸张的,看官勿深纠。
相关代码下载地址请见文末
整理归档文件
上一篇文章中,我们采集了拉勾网的岗位数据,保存到了代码目录的./data中,我们要做的就是对文件进行合并, 当然如果你只想了解词云的使用, 明哥也在代码中上传了文本文件,你可以直接跳过这一部分,进入读取文件部分。
我们先新建一个createTest.py文件,用于将原有的岗位文件进行合并。代码如下:
# -*- coding: utf-8 -*-
# 生成txt文本文章
#author
import os
def file_name(file_dir):
for root, dirs, files in os.walk(file_dir):
return files
files = file_name('./data/')
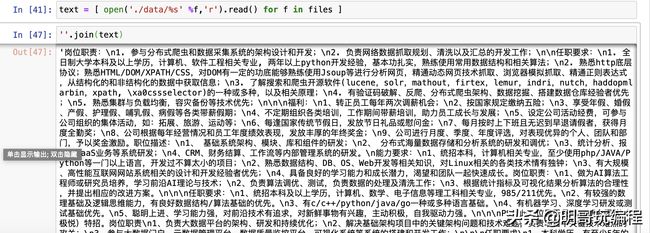
text = ''.join([ open('./data/%s' %f,'r').read() for f in files ]
with open('lagou-job.txt','w+',encoding='utf-8') as lagou:
lagou.write(text)
关键函数: file_name(),传入指定目录文件,返回目录下的文件名列表,因为data目录中我只保存了岗位语言件,所以不需要再进行过滤。
text = ''.join([ open('./data/%s' %f,'r').read() for f in files ] 循环读出所有的文件,并合并成一个字符串。
最后写入到名为lagou-job.txt 文件当中。
执行命令
python3 createTxt.py
执行结果如下。
读取数据文件
text=''
with open('./lagou-job.txt','r') as f:
text=f.read()
f.close()
print(text[:100])
输出结果:
职位描述:岗位职责:1.展开机器学习/深度学习等相关领域研究和开发工作;2.负责从事深度学习框架搭建,包括机器学习、图像处理等的算法和系统研发;3.支持公司相关产品深度学习相关研究;岗位要求:1.机器
jieba分词
上面的输出结果肯定不是我们想要的东西,那么我们就要通过第三方模块“jeba”分词功能来进行处理。
#cell-2
import jieba
words = jieba.lcut(text)
cuted=' '.join(words)
print(cuted[:100])
输出被空格分开的文本:
岗位职责 : 1 . 参与 分布式 爬虫 和 数据 采集 系统 的 架构设计 和 开发 ; 2 . 负责 网络 数据 抓取 规划 、 清洗 以及 汇总 的 开发 工作 ;
安装wordcloud和matplotlib
词云wordcloud的官方项目地址
推荐直接用pip3 install wordcloud进行安装。
conda的安装比较慢,一般明哥在安装的时候都是搭建一套虚拟环境,最后用pip进行安装。
如果是conda则要使用-c切换通道为conda-forge,命令是
conda install -c conda-forge wordcloud可能比较慢,耐心等就好。
matplotlib视觉化模块官方网址
安装命令pip3 install matplotlib或conda install matplotlib。
生成词云对象
from wordcloud import WordCloud
fontpath='/System/Library/Fonts/STHeiti Medium.ttc' #当前字体文件为MAC下所有,如果WIN环境下,请替换文件路径
wc = WordCloud(font_path=fontpath, # 设置字体
background_color="white", # 背景颜色
max_words=1000, # 词云显示的最大词数
max_font_size=500, # 字体最大值
min_font_size=20, #字体最小值
random_state=42, #随机数
collocations=False, #避免重复单词
width=1600,height=1200,margin=10, #图像宽高,字间距,需要配合下面的plt.figure(dpi=xx)放缩才有效
)
wc.generate(cuted)
首先,默认情况wordcloud是不支持中文显示的,所以要先添加一个中文字体文件,一般是.ttf或.ttc格式,你可以使用本机中文字体进行替代,(网上大部分都是收费,或因版权问题被下架了)
WordCloud(...)命令包含了很多参数,其中就包含了我们上面设定的字体路径font_path。
注意这里width=1600,height=1200,margin=100图像宽高只是原始图像的大小,至于后面显示出来的时候可能还会被放缩。它的更多参数可以查看 wordcloud官方WordCloud方法说明
显示词云图
我们用matplotlib的imshow就是image-show把图片显示出来。
import matplotlib.pyplot as plt
plt.figure(dpi=200) #通过这里可以放大或缩小
plt.imshow(wc, interpolation='catrom',vmax=1000)
plt.axis("off") #隐藏坐标
可以得到如下图效果:

去除冗余单词
我们可以利用jieba的del_word方法去掉冗余单词。
#cell-2
import jieba
removes =['熟悉', '技术', '经验']
for w in removes:
jieba.del_word(w)
words = jieba.lcut(text)
cuted = ' '.join(words)
print(cuted[:100])
这里用for循环依次删除了各个冗余词,也可不用for循环,改为lcut之后对words进行处理:
words = jieba.lcut(text)
words = [w for w in words if w not in removes]
整体运行,得到下图:

区分中英文
如果我们只关注英文技术点,比如python,tensorflow等,那就忽略中文内容。
使用正则表达式来匹配提取哪些由az小写字母和AZ大写字母加上0~9数字组成的单词。
修改cell-2如下:
#cell-2
import jieba
words = jieba.lcut(text)
import re
pattern = re.compile(r'^[a-zA-Z0-1]+$')
words = [w for w in words if pattern.match(w)]
cuted = ' '.join(words)
print(cuted[:100])
完整执行,得到下图:

我们可以从这个图中看到人工智能技术相关职位所需要的掌握的主要技能。
改变造型
我们让单词按照特定的造型来排列。首先我们需要一张造型图片,下面是一张AI文字造型图片,请把它右键另存为mask.png文件。

前面在wc = WordCloud(font_path=fontpath...中有很多参数可以设置,其中就有mask遮罩参数,可以指定一张读取的图片数据,根据官方说明,这个数据应该是nd-array格式,这是一个多维数组格式(N-dimensional Array)。
我们使用PIL模块中的Image.open(’…’)可以读取图片,然后利用numpy来转换为nd-arry格式。
修改cell-3,读取图片并增加mask参数:
#cell-3
from wordcloud import WordCloud
fontpath='SourceHanSansCN-Regular.otf'
import numpy as np
from PIL import Image
aimask=np.array(Image.open("mask.png"))
wc = WordCloud(font_path=fontpath, # 设置字体
background_color="white", # 背景颜色
max_words=1000, # 词云显示的最大词数
max_font_size=100, # 字体最大值
min_font_size=5, #字体最小值
random_state=42, #随机数
collocations=False, #避免重复单词
mask=aimask, #造型遮盖
width=1600,height=1200,margin=2, #图像宽高,字间距,需要配合下面的plt.figure(dpi=xx)放缩才有效
)
wc.generate(cuted)
完整执行后得到下图:

可以看到原本图片上白色的部分被留空,有颜色的部分才会放置单词。
改进颜色
默认情况图片上文字的颜色都是随机的,我们可以使用图片来控制文字的颜色。
WordCloud方法提供了一个color_func颜色函数的参数,用一个函数来改变每个词的颜色,在这里我们直接使用上面深色的AI图片颜色来控制。
from wordcloud import WordCloud
from wordcloud import ImageColorGenerator
fontpath='/System/Library/Fonts/STHeiti Medium.ttc'
import numpy as np
from PIL import Image
aimask=np.array(Image.open("mask.png"))
genclr=ImageColorGenerator(aimask)
wc = WordCloud(font_path=fontpath, # 设置字体
background_color="white", # 背景颜色
max_words=1000, # 词云显示的最大词数
max_font_size=100, # 字体最大值
min_font_size=5, #字体最小值
random_state=42, #随机数
collocations=False, #避免重复单词
mask=aimask, #造型遮盖
color_func=genclr,
width=1600,height=1200,margin=2, #图像宽高,字间距,需要配合下面的plt.figure(dpi=xx)放缩才有效
)
wc.generate(cuted)
在上面,我们引入了from wordcloud import ImageColorGenerator方法,它是直接用来生成一个color_func颜色函数的,它括号里需要一个nd-array多维数组的图像,恰好我们上面的aimask就是这个格式,直接用就可以。
重新运行得到最开始看到的图,
和原图对比,就能看到文字颜色的规律了:

汇总
- 生成文件
- 读取文件
- jieba分词
- 利用re正则表达式选出英文单词
- 生成词云对象,利用图片遮罩形状和改变颜色
- 使用Matplotlib来显示图片
作者相关:
博客、新浪微博、简书、微信
本系列教程及源码地址:点击访问
最后:如果你正在学习Python的路上,或者准备打算学习Python、明哥会陪着你陪你一起共同进步!
手打不易,有用的话,请记得关注转发。