Spark2.0功能测试和日志查看
一、spark2.0功能测试
1.Spark-shell
在spark的sbin使用spark-shell命令开启,使用如下例子测试:
scala>val file=sc.textFile("hdfs://namenode:9000/user/hadoop/input/core-site.xml")
scala>val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
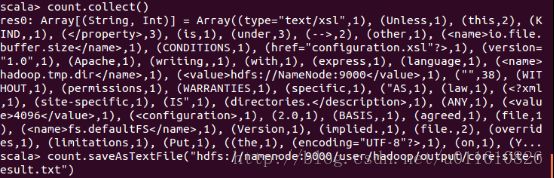
scala>count.collect()
scala>count.saveAsTextFile("hdfs://namenode:9000/user/hadoop/output/core-site-result1.txt")
输出结果如下:

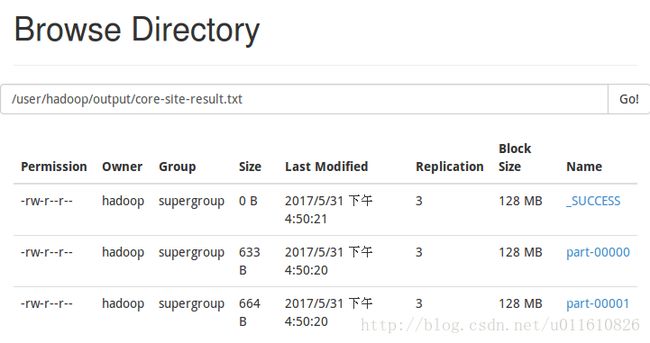
可以在50070端口查看输出结果:
2.Spark-submit
Yarn模式:
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--executor-cores 1 \
--queue default \
examples/jars/spark-examples_2.11-2.0.0.jar \
10
运行的命令行输出如下:

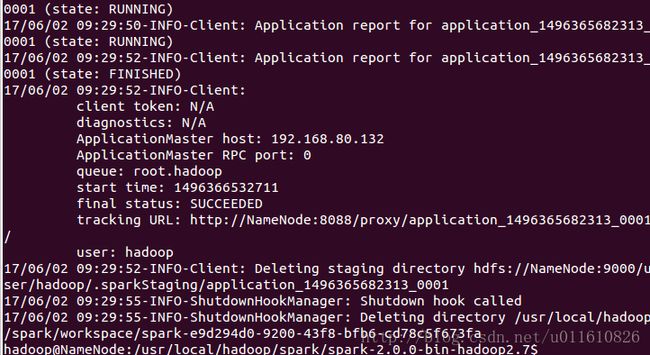
得到的输出如下:
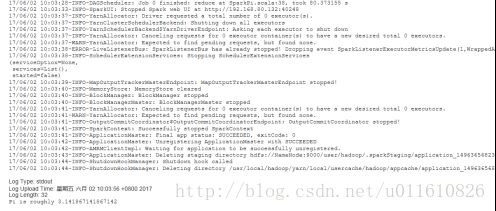
访问log页面可以看到计算出的Pi结果。
二、查看spark日志
1.Spark-shell的例子的输出日志
NameNode的4040端口可以查看jobs的日志如下:
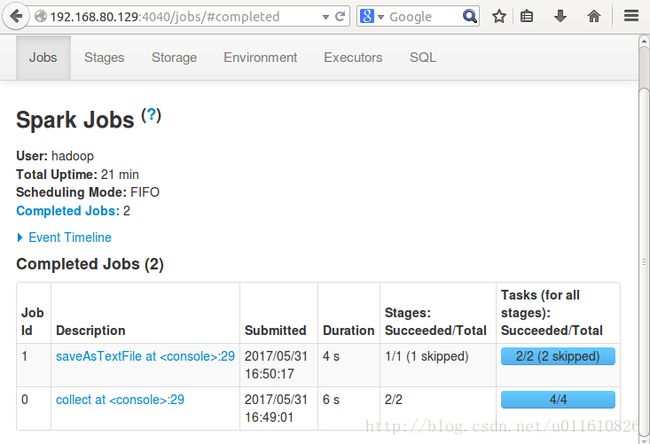
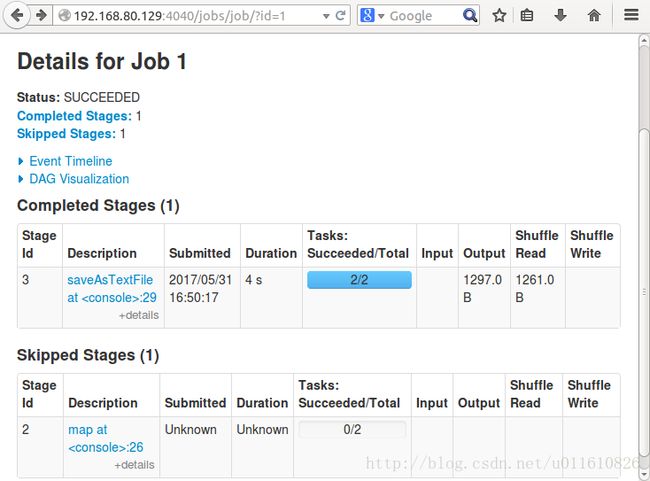
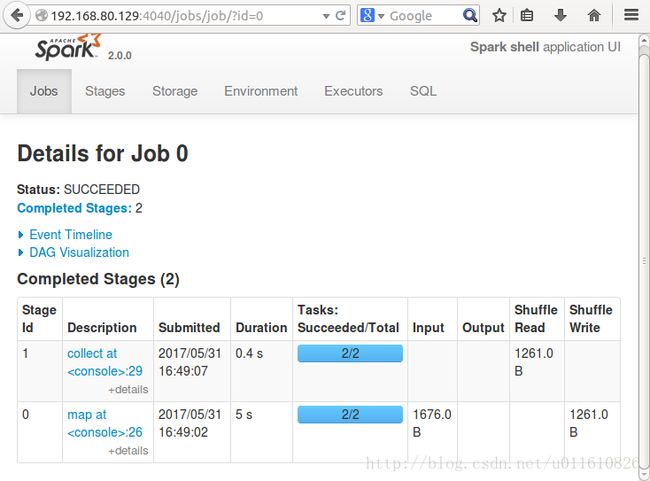
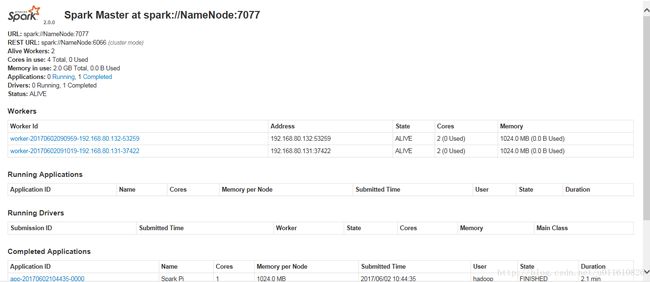
NameNode的8082端口(默认为8080)WebUI可以查看applications的日志如下:

2.Spark-submit的yarn模式例子的输出日志
1)通过hadoop的8088端口可以查看application的运行情况:
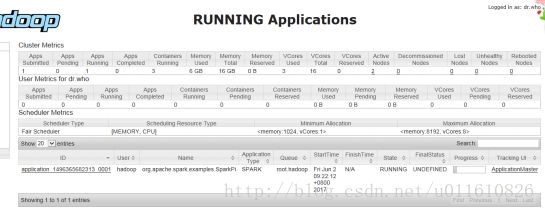
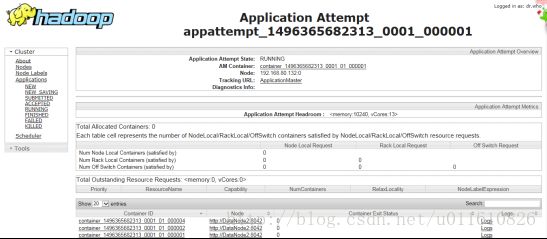
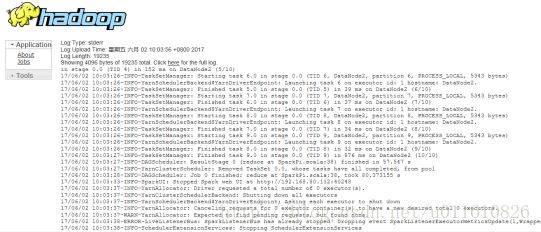
点击logs链接可以查看stdout和stderr如下:
Stderr:
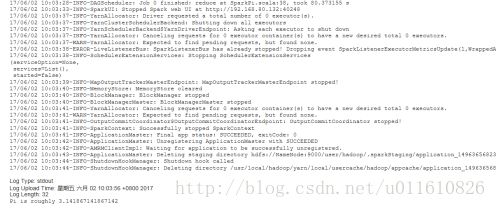
Stdout:
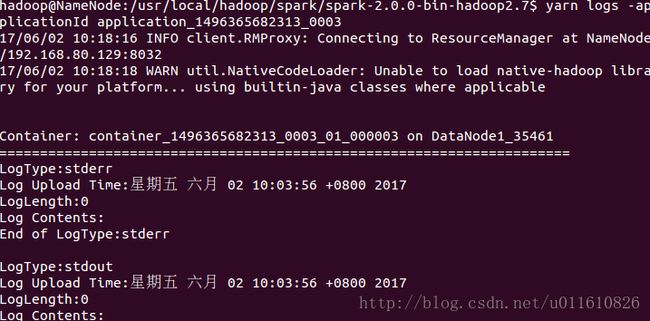
2)也可以通过yarn的logs方法查看相应applicationID的日志
使用yarn logs -applicationId application_1496365682313_0003查看日志;yarn applicaiton -status application_1496365682313_0003查看application的状态。
3)还可以通过配置spark将日志存放到hdfs的/history_server目录下,查看过程如下:
![]()


4)另外测试过程中发现Spark的日志要过一段时间才可以在webUI上显示:
http://192.168.80.129:8082/
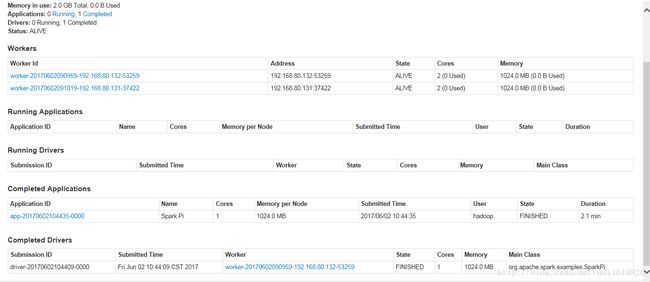
http://192.168.80.129:8082/app/?appId=app-20170602104435-0000
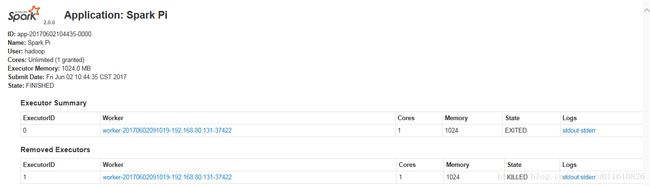
http://192.168.80.131:8081/

http://192.168.80.132:8081/

http://192.168.80.132:8081/logPage/?driverId=driver-20170602104409-0000&logType=stdout

http://192.168.80.132:8081/logPage/?driverId=driver-20170602104409-0000&logType=stderr

说明:要在win7宿主机中查看WebUI中日志,需要配置host。