Mycat分片路由解析引起的查询效率问题解决--源码解读
- 题前话
对于做大数据分析的同学来说,整个ETL过程无疑是大数据工作中最有挑战也最耗费精力的部分,尤其是在数据收集、清洗、计算阶段,比如如何保证数据收集完整,如何保证清洗后数据真实有效字段含义准确,如何选取集群计算引擎保证数据处理稳定高效,如何实现集群高可用以及容错机制等等,然而做完这些工作只能说是完成大数据分析工作中的80%,最后怎么将分析结果呈现给客户,并达到可交互、实时性的数据展示,也是大数据分析工作中尤为重要的一环。
笔者有遇到一些业务场景,对网站访问日志进行分析并提供实时分析结果响应,然而Spark分析出来的结果集依然十分庞大,采用Mysql存储并对常用字段做了索引优化的情况还是难以达到理想的查询性能,前面考虑过采用Hbase,但是业务场景中会有大量的条件查询、数据聚合且数据整行读取的场景比较常见,采用基于列存储的Nosql数据库会显得有点力不从心,遂放弃,后面前辈给推荐了分布式数据库中间件Mycat(前身基于阿里开源Cobar),目前来看还算比较好用,其实主要还是免费。 - 问题描述
目前采用Mycat中间件对Mysql数据库进行水平分库分表,共有300个物理分片,采取固定范围分片规则将不同时间段的数据分布存储到300个物理库中。按常理讲,同样的查询条件下查询单个物理库和和按照分片规则通过中间件定位到具体的物理库查询所耗费的时间应该相差不大,唯一可能引起性能损失的不外乎路由解析过程和sql转发,不过这部分损耗应该非常小,相比于实际的物理库查询时间可忽略。然而,实际测试情况看,通过Mycat查询比通过Mysql进行单库查询慢非常多,原因出在哪里呢? - 问题分析
笔者首先想到的是Mycat可能会有问题,去看Mycat日志
 一看日志,报了大量的no ilde connection in pool,create new connection这样的信息,不对呀,查询条件明明带了分片字段而且数据集范围只可能出现在一个物理库中怎么会创建这么多新连接呢,继续找
一看日志,报了大量的no ilde connection in pool,create new connection这样的信息,不对呀,查询条件明明带了分片字段而且数据集范围只可能出现在一个物理库中怎么会创建这么多新连接呢,继续找
好了,可以看到,分片字段的范围好像并没有生效,Mycat是去查了所有的分片,没道理啊,难道Mycat所谓的路由分片规则没有生效吗?带着疑问,决定看看Mycat源码找找原因
可以从Github下载源码https://github.com/MyCATApache/Mycat-Server.git,导入IDEA用Maven编译,整个过程耗时较长,约需1个多小时编译完成
打开AbstractRouteStrategy.java类查看到Mycat的路由策略
public RouteResultset route(SystemConfig sysConfig, SchemaConfig schema, int sqlType, String origSQL,
String charset, ServerConnection sc, LayerCachePool cachePool) throws SQLNonTransientException {
//对应schema标签checkSQLschema属性,把表示schema的字符去掉
if (schema.isCheckSQLSchema()) {
origSQL = RouterUtil.removeSchema(origSQL, schema.getName());
}
/**
* 处理一些路由之前的逻辑
* 全局序列号,父子表插入
*/
if ( beforeRouteProcess(schema, sqlType, origSQL, sc) ) {
return null;
}
/**
* SQL 语句拦截
*/
String stmt = MycatServer.getInstance().getSqlInterceptor().interceptSQL(origSQL, sqlType);
if (!origSQL.equals(stmt) && LOGGER.isDebugEnabled()) {
LOGGER.debug("sql intercepted to " + stmt + " from " + origSQL);
}
RouteResultset rrs = new RouteResultset(stmt, sqlType);
/**
* 优化debug loaddata输出cache的日志会极大降低性能
*/
if (LOGGER.isDebugEnabled() && origSQL.startsWith(LoadData.loadDataHint)) {
rrs.setCacheAble(false);
}
/**
* rrs携带ServerConnection的autocommit状态用于在sql解析的时候遇到
* select ... for update的时候动态设定RouteResultsetNode的canRunInReadDB属性
*/
if (sc != null ) {
rrs.setAutocommit(sc.isAutocommit());
}
/**
* DDL 语句的路由
*/
if (ServerParse.DDL == sqlType) {
return RouterUtil.routeToDDLNode(rrs, sqlType, stmt, schema);
}
/**
* 检查是否有分片
*/
if (schema.isNoSharding() && ServerParse.SHOW != sqlType) {
rrs = RouterUtil.routeToSingleNode(rrs, schema.getDataNode(), stmt);
} else {
RouteResultset returnedSet = routeSystemInfo(schema, sqlType, stmt, rrs);
if (returnedSet == null) {
rrs = routeNormalSqlWithAST(schema, stmt, rrs, charset, cachePool,sqlType,sc);
}
}
return rrs;
}
从源码可以看到执行路由策略前,会首先对拦截到的sql语句进行解析,接着通过解析AST语法树类来寻找路由
/**
* 路由之前必要的处理
* 主要是全局序列号插入,还有子表插入
*/
private boolean beforeRouteProcess(SchemaConfig schema, int sqlType, String origSQL, ServerConnection sc)
throws SQLNonTransientException {
return RouterUtil.processWithMycatSeq(schema, sqlType, origSQL, sc)
|| (sqlType == ServerParse.INSERT && RouterUtil.processERChildTable(schema, origSQL, sc))
|| (sqlType == ServerParse.INSERT && RouterUtil.processInsert(schema, sqlType, origSQL, sc));
}
/**
* 通过解析AST语法树类来寻找路由
*/
public abstract RouteResultset routeNormalSqlWithAST(SchemaConfig schema, String stmt, RouteResultset rrs,
String charset, LayerCachePool cachePool,int sqlType,ServerConnection sc) throws SQLNonTransientException;
/**
* 路由信息指令, 如 SHOW、SELECT@@、DESCRIBE
*/
public abstract RouteResultset routeSystemInfo(SchemaConfig schema, int sqlType, String stmt, RouteResultset rrs)
throws SQLSyntaxErrorException;
接着往下走,看看这个AST语法树解析是什么东东。。。
public RouteResultset routeNormalSqlWithAST(SchemaConfig schema,
String stmt, RouteResultset rrs,String charset,
LayerCachePool cachePool,int sqlType,ServerConnection sc) throws SQLNonTransientException {
/**
* 只有mysql时只支持mysql语法
*/
SQLStatementParser parser = null;
if (schema.isNeedSupportMultiDBType()) {
parser = new MycatStatementParser(stmt);
} else {
parser = new MySqlStatementParser(stmt);
}
MycatSchemaStatVisitor visitor = null;
SQLStatement statement;
/**
* 解析出现问题统一抛SQL语法错误
*/
try {
statement = parser.parseStatement();
visitor = new MycatSchemaStatVisitor();
} catch (Exception t) {
LOGGER.error("DruidMycatRouteStrategyError", t);
throw new SQLSyntaxErrorException(t);
}
/**
* 检验unsupported statement
*/
checkUnSupportedStatement(statement);
DruidParser druidParser = DruidParserFactory.create(schema, statement, visitor);
druidParser.parser(schema, rrs, statement, stmt,cachePool,visitor);
DruidShardingParseInfo ctx= druidParser.getCtx() ;
rrs.setTables(ctx.getTables());
if(visitor.isSubqueryRelationOr()){
String err = "In subQuery,the or condition is not supported.";
LOGGER.error(err);
throw new SQLSyntaxErrorException(err);
}
/* 按照以下情况路由
1.2.1 可以直接路由.
1.2.2 两个表夸库join的sql.调用calat
1.2.3 需要先执行subquery 的sql.把subquery拆分出来.获取结果后,与outerquery
*/
//add huangyiming 分片规则不一样的且表中带查询条件的则走Catlet
List tables = ctx.getTables();
SchemaConfig schemaConf = MycatServer.getInstance().getConfig().getSchemas().get(schema.getName());
int index = 0;
RuleConfig firstRule = null;
boolean directRoute = true;
Set firstDataNodes = new HashSet();
Map tconfigs = schemaConf==null?null:schemaConf.getTables();
Map rulemap = new HashMap<>();
if(tconfigs!=null){
for(String tableName : tables){
TableConfig tc = tconfigs.get(tableName);
if(tc == null){
//add 别名中取
Map tableAliasMap = ctx.getTableAliasMap();
if(tableAliasMap !=null && tableAliasMap.get(tableName) !=null){
tc = schemaConf.getTables().get(tableAliasMap.get(tableName));
}
}
if(index == 0){
if(tc !=null){
firstRule= tc.getRule();
//没有指定分片规则时,不做处理
if(firstRule==null){
continue;
}
firstDataNodes.addAll(tc.getDataNodes());
rulemap.put(tc.getName(), firstRule);
}
}else{
if(tc !=null){
//ER关系表的时候是可能存在字表中没有tablerule的情况,所以加上判断
RuleConfig ruleCfg = tc.getRule();
if(ruleCfg==null){ //没有指定分片规则时,不做处理
continue;
}
Set dataNodes = new HashSet();
dataNodes.addAll(tc.getDataNodes());
rulemap.put(tc.getName(), ruleCfg);
//如果匹配规则不相同或者分片的datanode不相同则需要走子查询处理
if(firstRule!=null&&((ruleCfg !=null && !ruleCfg.getRuleAlgorithm().equals(firstRule.getRuleAlgorithm()) )||( !dataNodes.equals(firstDataNodes)))){
directRoute = false;
break;
}
}
}
index++;
}
}
RouteResultset rrsResult = rrs;
if(directRoute){ //直接路由
if(!RouterUtil.isAllGlobalTable(ctx, schemaConf)){
if(rulemap.size()>1&&!checkRuleField(rulemap,visitor)){
String err = "In case of slice table,there is no rule field in the relationship condition!";
LOGGER.error(err);
throw new SQLSyntaxErrorException(err);
}
}
rrsResult = directRoute(rrs,ctx,schema,druidParser,statement,cachePool);
}else{
int subQuerySize = visitor.getSubQuerys().size();
if(subQuerySize==0&&ctx.getTables().size()==2){ //两表关联,考虑使用catlet
if(!visitor.getRelationships().isEmpty()){
rrs.setCacheAble(false);
rrs.setFinishedRoute(true);
rrsResult = catletRoute(schema,ctx.getSql(),charset,sc);
}else{
rrsResult = directRoute(rrs,ctx,schema,druidParser,statement,cachePool);
}
}else if(subQuerySize==1){ //只涉及一张表的子查询,使用 MiddlerResultHandler 获取中间结果后,改写原有 sql 继续执行 TODO 后期可能会考虑多个子查询的情况.
SQLSelect sqlselect = visitor.getSubQuerys().iterator().next();
if(!visitor.getRelationships().isEmpty()){ // 当 inner query 和 outer query 有关联条件时,暂不支持
String err = "In case of slice table,sql have different rules,the relationship condition is not supported.";
LOGGER.error(err);
throw new SQLSyntaxErrorException(err);
}else{
SQLSelectQuery sqlSelectQuery = sqlselect.getQuery();
if(((MySqlSelectQueryBlock)sqlSelectQuery).getFrom() instanceof SQLExprTableSource) {
rrs.setCacheAble(false);
rrs.setFinishedRoute(true);
rrsResult = middlerResultRoute(schema,charset,sqlselect,sqlType,statement,sc);
}
}
}else if(subQuerySize >=2){
String err = "In case of slice table,sql has different rules,currently only one subQuery is supported.";
LOGGER.error(err);
throw new SQLSyntaxErrorException(err);
}
}
return rrsResult;
}
嗯,是用了DruidParser对sql以及Mycat配置schema进行解析然后得到路由结果集,druidParser.parser(schema, rrs, statement, stmt,cachePool,visitor)进去看看,到DefaultDruidParser.java类
public void visitorParse(RouteResultset rrs, SQLStatement stmt,MycatSchemaStatVisitor visitor) throws SQLNonTransientException{
stmt.accept(visitor);
ctx.setVisitor(visitor);
if(stmt instanceof SQLSelectStatement){
SQLSelectQuery query = ((SQLSelectStatement) stmt).getSelect().getQuery();
if(query instanceof MySqlSelectQueryBlock){
if(((MySqlSelectQueryBlock)query).isForUpdate()){
rrs.setSelectForUpdate(true);
}
}
}
List> mergedConditionList = new ArrayList>();
if(visitor.hasOrCondition()) {//包含or语句
//TODO
//根据or拆分
mergedConditionList = visitor.splitConditions();
} else {//不包含OR语句
mergedConditionList.add(visitor.getConditions());
}
if(visitor.isHasChange()){ // 在解析的过程中子查询被改写了.需要更新ctx.
ctx.setSql(stmt.toString());
rrs.setStatement(ctx.getSql());
}
if(visitor.getAliasMap() != null) {
for(Map.Entry entry : visitor.getAliasMap().entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
if(key != null && key.indexOf("`") >= 0) {
key = key.replaceAll("`", "");
}
if(value != null && value.indexOf("`") >= 0) {
value = value.replaceAll("`", "");
}
//表名前面带database的,去掉
if(key != null) {
int pos = key.indexOf(".");
if(pos> 0) {
key = key.substring(pos + 1);
}
tableAliasMap.put(key.toUpperCase(), value);
}
// else {
// tableAliasMap.put(key, value);
// }
}
ctx.addTables(visitor.getTables());
visitor.getAliasMap().putAll(tableAliasMap);
ctx.setTableAliasMap(tableAliasMap);
}
ctx.setRouteCalculateUnits(this.buildRouteCalculateUnits(visitor, mergedConditionList));
}
private List buildRouteCalculateUnits(SchemaStatVisitor visitor, List> conditionList) {
List retList = new ArrayList();
//遍历condition ,找分片字段
for(int i = 0; i < conditionList.size(); i++) {
RouteCalculateUnit routeCalculateUnit = new RouteCalculateUnit();
for(Condition condition : conditionList.get(i)) {
List 原因即将出现,大家注意看这里
if(operator.equals("between")) {
RangeValue rv = new RangeValue(values.get(0), values.get(1), RangeValue.EE);
routeCalculateUnit.addShardingExpr(tableName.toUpperCase(), columnName, rv);
} else if(operator.equals("=") || operator.toLowerCase().equals("in")){ //只处理=号和in操作符,其他忽略
routeCalculateUnit.addShardingExpr(tableName.toUpperCase(), columnName, values.toArray());
}
What The Fuck?Mycat使用DruidParser进行sql解析扫描condition寻找含有分片字段的查询条件,处理where语句里的分片字段进而路由到指定的物理库进行查询时,只会处理BETWEEN…AND、= 和 IN 这三种情况,也就是说,只有分片字段的查询条件是这三种情况的时候才会路由的指定的Range,那之外当然是要扫描所有分片啦,每个物理分片查询会创建一个sql连接,也印证了前面Mycat日志中大量create new connection的异常情况。
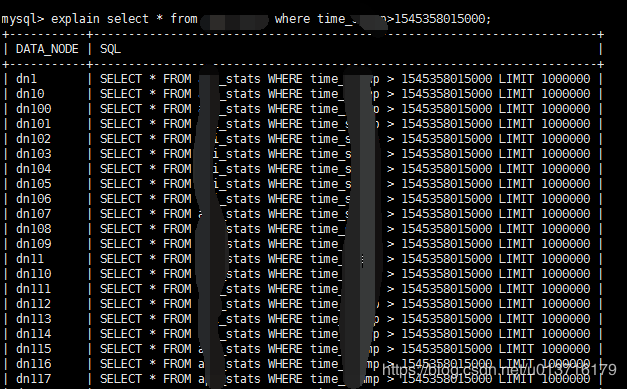
分析完源码,那下面就是验证的时候了,先看看执行计划


神奇的想象出现了,采用><查询时Mycat扫面了全部分片,而采用between…and查询时,Mycat成功路由到了数据所在分片,下面在看下查询效率区别


同样的查询结果,耗时相差了整整3倍,目前看来Mycat建立到所有物理分片的sql连接是一件非常耗费性能的事情。
至此,问题已经解决,希望Mycat在下个版本的分片路由解析策略中做出优化~